Jimdo~記事の投稿~
記事の投稿方法
① 画面右にある編集タブを開き、 ブログ を選択したら、新しい記事を投稿する をクリックします。

② "新しいブログを書く" のところを消し、タイトルを入力します。
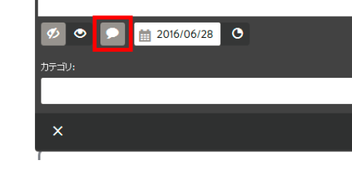
タイトル下にある吹き出しマークはコメントの設定です。
デフォルトはコメント有効になっていますので、不要な場合は無効にして下さい。

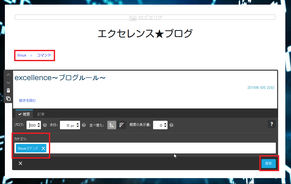
③ 先ほどと同じ枠内にカテゴリ欄があります。
好きなカテゴリを入力できますが、必ず投稿者の名前、もしくはハンドルネームを入力してください。
( 1度入力したカテゴリに関しては、次回入力時に候補として表示されます。 )
最後に枠内右下にある 保存 をクリックします。

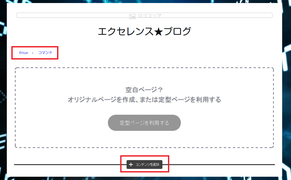
④ 次に記事の挿入の仕方についてですが、タイトル枠より下にカーソルを合わせると
+コンテンツを追加 と表示されるので、クリックします。
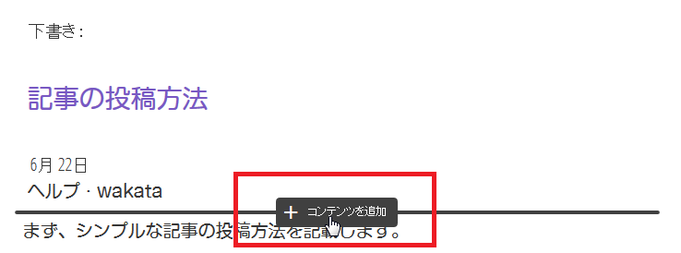
⑤ クリックすると以下の項目が表示されます。
文章のみの場合、画像のみの場合、画像と文章を載せる場合と
選択できますので必要に応じて選択してください。
※ ソースコードを載せる場合は方法が違いますので コチラ を参考にしてください。

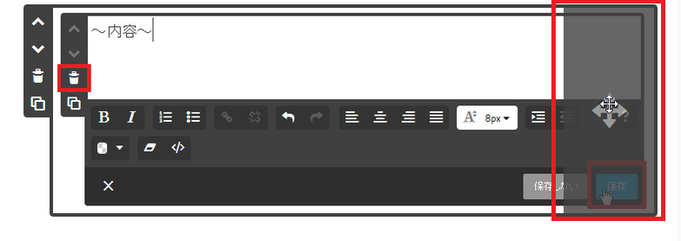
⑥ 例として文章を載せる場合、文章を編集し、 保存 をクリックすれば文章挿入完了です。

⑦ コンテンツはそれぞれ移動できるので、コンテンツ枠右に表示される移動ポインタをクリックした状態で
任意の位置に移動します。
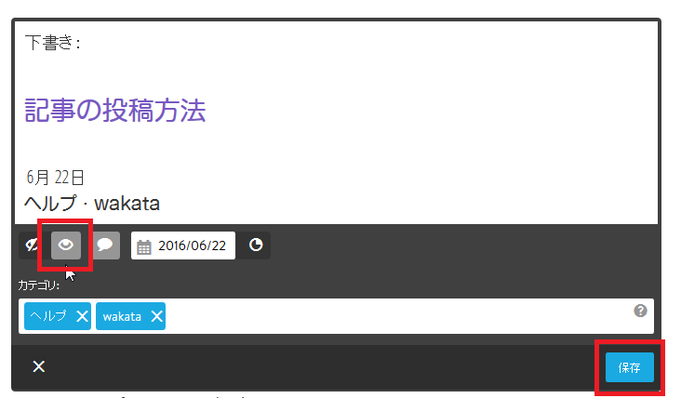
⑧ 最後にタイトル枠内にある "目" のマーク(斜線が入っていない方)をクリックし、グレーになったことを確認します。
この状態で 保存 をクリックすると下書き状態から公開状態に変わります。
HOME画面上に投稿順に記事が表示されていることが確認できたら、記事の投稿は完了です。
Jimdo~記事の見出し~
見出しの追加方法
① 記事に見出しを追加するには、タイトル枠下にある +コンテンツを追加 をクリックし
追加コンテンツの 見出し を追加します。

② ~見出し~ のところに見出しを入力し、 保存 をクリックしたら追加完了です。

③ 一覧記事の表示方法にもよりますが、一覧記事表示編集画面で概要の表示量が 1 以上であれば
タイトル下に見出しが表示されているはずです。


Jimdo~記事の削除~
記事の削除方法
① ブログ記事一つを削除したい場合は、編集画面右端のタブで ブログ を選択します。
削除したい記事の日付横にある 削除 をクリックすると記事の削除完了です。

② 画像や文章などコンテンツ単位で削除したい場合は、コンテンツ編集画面の左端にある ゴミ箱マーク を選択すると
削除ができます。

Jimdo~カテゴリ~
タグの説明
タグ付けをし、タグ毎にブログを掲載することによって、記事が整理されアクセス数もアップします。
タグ付けをしたブログは、ナビゲーションを編集しカテゴリ別に表示させます。
タグは複数でも可能なので、例えば、 "2016/07" と "waka" と入力しておけば
最新の2016/07カテゴリでも表示され、投稿者のwakaのカテゴリでも表示されます。
※ ただし、この記事表示はOR条件なので他のタグと名前が同じにならないようにお願いします。


カテゴリの追加について
ブログ一覧ページに表示されるカテゴリを新たに追加したい場合は、ナビゲーションの編集をします。
編集画面上部にカーソルを合わせると、 ナビゲーションの編集 と表示されるのでクリックします。
ナビゲーションの詳細について

上図のように、ナビゲーションの編集と表示され、
クリックすると左図のように、編集画面が表示されます。
新たに表示するカテゴリを追加する場合は、
新規ページを追加をクリックすると追加欄が表示されます。
それぞれのマークの詳細は以下の通りです。

例)Linux の配下に コマンド という小カテゴリを作成

① 上記の手順でナビゲーションの編集画面を開き、linux カテゴリの配下に
新規ページを作成します。
② カテゴリ名を入力します。
※ 他のタグと名前が同じにならないようにお願いします。
OR条件 でブログ一覧表示する仕様のためです。
③ linux のページより下の階層にしたいので、> マークをクリックし
コマンド の階層を下げます。
④ 右下にある 保存 をクリックし、ナビゲーションを保存します。
保存すると ナビゲーション にカテゴリが追加されます。
※この時点では、コマンド というページに自動で記事が表示されるわけではありません。以下の設定が必要です。
例)Linux>コマンド ページに " linuxコマンド " がタグ付けされている記事を表示させる
①
②

③
① Linux>コマンド のページ上にある +コンテンツを追加 をクリックします。
② クリックすると追加するコンテンツの種類が選択できるので、ブログを表示 をクリックします。
③ 表示させたい "linuxコマンド" というタグを入力し、保存 をクリックします。
④ Linux>コマンド のページ上に、 "linuxコマンド" とタグ付けされているブログが表示されます。
Jimdo~スマホで投稿~
スマホアプリ

Jimdoのブログ投稿はスマホからでも投稿することが可能です。
画面表示もスマホ用とPC用と2種選択できますので、レイアウト確認もしやすくなっています。


excellence~ブログルール~
ブログ掲載ルール
・ ブログ記事投稿の際、コメント無効の状態で投稿してください。

・ ブログ記事投稿の際、必ず年月と名前のタグを入力してください。
このタグは複数入力可能です。
無ければ作ってやるシリーズ①
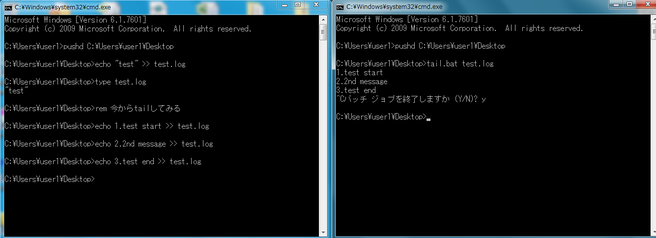
Windowsでtail -fコマンドが使いたい
ログファイルとか出力されつづけるファイルを常時みたい
Windows上でデバック出力したログを確認しながらテストしたいなぁと思う時があります。
Linuxではtailコマンドという便利なものがありますが、Windowsには無い!
なので、自作してみました。
tail -fっぽく動きます。
右記をコピーしてbatファイルを作ってみてください。
できあがったので使ってみました。
tailって便利だなぁ。
ソースコードの埋め込みに対応しました
使い方
[+コンテンツを追加]から[ウィジェット]を選びます。

次のように<pre>タグのclass属性に "brush: XXX" を設定します。※XXXは適用する言語名

保存してページ表示するとこんな感じ。
print "Hello, world!\n"
使える言語とサンプル
※とりあえずサンプルは一部だけ。
あるやつは名前をクリックすると飛べる。
| 言語 | brushに指定する名前 |
|---|---|
| ActionScript3 |
as3 |
| Bash/shell |
bash, shell |
| C/C++ |
c, cpp |
| C# |
csharp |
| ColdFusion |
cf |
| CSS |
css |
| Delphi |
delphi |
| Diff |
diff |
| Erlang |
erl |
| Groovy |
groovy |
| HTML |
html |
| Java |
java |
| JavaFX |
jfx |
| JavaScript |
js |
| Perl |
perl |
| PHP |
php |
| PowerShell |
ps |
| Python |
py |
| Ruby |
ruby |
| Scala |
scala |
| SQL |
sql |
| Visual Basic |
vb |
| XML |
xml |
| プレーンテキスト |
text |
C/C++
設定
<pre class="brush: c"> <!-- ←C++の場合は cpp -->
#include <stdio.h> <!-- 残念ながら<,>はエスケープしないとだめ -->
int main(void)
{
printf("Hello, world!");
return 0;
}
</pre>
表示
#include <stdio.h>
int main(void)
{
printf("Hello, world!");
return 0;
}
C#
設定
<pre class="brush: csharp">
class HelloWorldApp
{
static void Main()
{
System.Console.WriteLine("Hello, world!");
}
}
</pre>
表示
class HelloWorldApp
{
static void Main()
{
System.Console.WriteLine("Hello, world!");
}
}
CSS
設定
<pre class="brush: css">
.body {
color: black;
font-family: monospace;
}
</pre>
表示
.body {
color: black;
font-family: monospace;
}
Java
設定
<pre class="brush: java">
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
</pre>
表示
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
JavaScript
設定
<pre class="brush: js">
(function() {
console.log("Hello, world!");
})();
</pre>
表示
(function() {
console.log("Hello, world!");
})();
作業メモ
- SyntaxHighlighterという外部のJavaScript+CSSを使用
- 設定は右の管理メニュー[設定]>[ヘッダーを編集]から(ホスティングされている.jsファイル及び.cssファイルへのリンクを追加したのみ)
- 古いバージョンのSyntaxHighlighterには[クリップボードにコピー]ボタンがあったが、最新版にはない(環境に依存するから?)。代わりにダブルクリックで全選択ができるので、そうやってからコピーすることが推奨されている。
スマホからの投稿 -sample-
Targetに指定した画面をfocusする
複数のWEB画面を制御したい時に特定の画面にfocusをあてる方法
ポップアップ画面や複数のタブ画面で構成されたWEBアプリケーションでは、formのtarget指定で画面遷移をします。
でも、画面遷移させた先の画面をフォーカス(前面表示)させたり、フォーカスを外し(後面表示)たりしたいと思うことがありませんか?
今回はその方法について紹介します。
複数の画面を制御する構文例でよく紹介されているやり方①
function preview() { window.open("about:blank","preview","width=600,height=450,scrollbars=yes"); document.input_form.target = "preview"; document.input_form.submit(); }
<form action="preview.html" method="post" name="input_form" id="input_form"> - 処理 - </form>
この構文は、新しい画面を開いて、その画面にpostで画面遷移させるやり方です。
①scriptで新規画面を開きます。
②targetで新たな画面に付けた名前を指定します。
③submitします。
同様に以下のようにしておけば、一度開いた画面を制御できます。
var win_name;
// 子画面を開く処理
function preview() { win_name = window.open("about:blank","preview","width=600,height=450,scrollbars=yes"); document.input_form.target = "preview"; document.input_form.submit(); }
// 子画面を閉じる処理
function closeview(){
if(win_name) win_name.close();
}
<form action="preview.html" method="post" name="input_form" id="input_form"> - 処理 - </form>
targetには、以下の特別な意味をもつ指定を使うと他画面を制御することができます。
| 名前 | 意味 |
|---|---|
| _top | フレーム分割の際のトップフレーム(ウィンドウ) |
| _blank | 名前無しの新しいウィンドウ |
| _self | 自分自身のフレーム(ウィンドウ) |
| _parent | フレーム分割の際のひとつ親のフレーム(ウィンドウ) |
複数の画面を制御する構文例でよく紹介されているやり方②
parent.html
<a href="javascript:window.open('child.html');return;">open child</a>
child.html
<a href="javascript:window.opener.focus();return;">activate parent</a>
この構文は、呼び出し元の親画面をフォーカスする方法です。
opener(呼び出し元)を指定すれば、子画面側から親画面にフォーカスを移すことができます。
でも、やりたいのは。。。画面の名前を指定して制御したい!
こんな時は、以下のやり方を試してみてください。
<画面①>
var win_name;
// 子画面を開く処理
function preview() {
window.name = "parentWin"; //自画面に名前を付けておく win_name = window.open("about:blank","childWin","width=600,height=450,scrollbars=yes"); document.tochild_form.target = "preview"; document.tochild_form.submit(); }
<form action="child.html" method="post" name="tochild_form"></form>
<画面② : child.html>
// 親画面にアクションさせ、フォーカスを移す処理
function parentFocus() {
var fm = document.toparent_form;
var pwin = window.open("about:blank",fm.target);
fm.submit();
pwin.focus(); }
<form action="parent.html" target="parentWin" name="toparent_form" method="post"></form>
コマンドラインインタフェースを極めるシリーズ1
このシリーズの目的
長年LinuxとかAIXとかでコマンドライン操作やシェルを作ったりしていると、色々なテクニックが身についてきました。
せっかくなのでテクニックを公開していこうかと思い、書き始めます。
シリーズ1回目:エスケープ文字でかっこいい出力にできるんだ
コマンドラインの出力といえば、echoとかprintとかprintfとかを使っていると思います。
今回はechoを使って様々な出力方法について紹介していきます。
エスケープ文字は以下のようなものがあります。
| \a | ベルを鳴らす |
| \b | バック・スペース |
| \e | エスケープ文字 |
| \f | フォーム・フィールド文字 |
| \n | 改行 |
| \r | 復帰 |
| \t | 水平タブ |
| \v | 垂直タブ |
| \c | 改行しない |
| \数字 | 指定したASCIIコードの文字。数字は8進数3桁で表記する |
| \x数字 | 指定したASCIIコードの文字。数字は16進数3桁で表記する |
以下は同じ結果出力になりますね。
「\n」の例
echo "こんにちは"
printf "こんにちは\n"
「\c」の例
echo "こんにちは\c"
printf "こんにちは"
ところで、本日の魔法の呪文は「 \033[ 」です。
この呪文をつかって、いろいろな出力方法を紹介します。
\033[ は \e[ と書けるOSもあります。この呪文(文字列)はエスケープと呼ばれる特殊文字です。
通常echoで文字出力する時は次のように書きます。
echo "こんにちは"
これを実行すると、「こんにちは」と表示されます。
では、次のように入力して実行してみましょう。
echo "\033[0;34mこんにちは\033[0m"
すると、「こんにちは」と表示されます。
なんと、色がつきましたね。
このように、文字を飾る時に\033[?mを使います。
?はデコレーション指定の数字、複数指定時はセミコロン(;)で区切る、最後にm(デコレーションですよフラグ)を付けます。
では、上記のechoコマンドを解説しましょう。
\033[0;34m ・・・ここから青色文字でっていう意味です。
\033[0m ・・・ここから色をリセットっていう意味です。
echoで表示する文字に色を付ける場合は、\033[色指定の数字m という指示を出します。
最後に\033[0mを書かないと、以降全ての表示が指定した色になってしまうので、最後のリセットはお忘れないように。
つまり、\033[?m ~ \033[0m までがデコレーションされます。
色は次のように定義されています。
Black 0;30 Dark Gray 1;30 Blue 0;34 Light Blue 1;34 Green 0;32 Light Green 1;32 Cyan 0;36 Light Cyan 1;36 Red 0;31 Light Red 1;31 Purple 0;35 Light Purple 1;35 Brown 0;33 Yellow 1;33 Light Gray 0;37 White 1;37
0;は省くことができます。
30番台は文字の色です。
これを40番台にすると、背景色になります。
Black 0;40 Dark Gray 1;40 Blue 0;44 Light Blue 1;44 Green 0;42 Light Green 1;42 Cyan 0;46 Light Cyan 1;46 Red 0;41 Light Red 1;41 Purple 0;45 Light Purple 1;45 Brown 0;43 Yellow 1;43 Light Gray 0;47 White 1;47
echo "\033[1;34;44mこんにちは\033[0m" ・・・AIXの場合 Linuxの場合はecho -e "\033[1;34;44mこんにちは\033[0m"
のような形式で背景と文字色を同時に指定できます。

文字に下線を書くには 4を指定。たとえば、 \033[4m
色の反転は 7を指定します。たとえば、 \033[7m
\033[を使ってカーソル位置指定もできます。
表示位置を指定できることから、対話式のコマンドを作成するときに役立ちます。
- カーソルの位置をY行X列に決める。
\033[<Y>;<X>H
- カーソルを Y 行上に動かす。
\033[<Y>A
- カーソルを Y 行下に動かす。
\033[<Y>B
- カーソルを X 列右に動かす。
\033[<X>C
- カーソルを X 列左に動かす。
\033[<X>D
- カーソルの位置を記憶する。
\033[s
- 記憶していたカーソルの位置に戻す。
\033[u
\033[を使って画面表示を消すこともできます。
\033[2J 画面クリア(clearコマンドと同じ) \033[K カーソル位置〜行末迄をクリア
oracle初期化パラメータの内容を確認・更新する
オラクルデータベースの初期化パラメータの内容を確認してみよう。
select a.NAME,a.VALUE from v$parameter a
where a.NAME='sga_max_size';

初期化パラメータの内容を変更してみよう。変更する初期化パラメータはshared_pool_sizeにします。
まず、現在のパラメータを確認します。
select a.NAME,a.VALUE from v$parameter a
where a.NAME='shared_pool_size';

次のSQL文でshared_pool_sizeの値を変更します。
alter system set shared_pool_size = 4194304 scope = memory;
値が変更されました。

次にログバッファの値を変更してみよう。まず現在の設定内容を確認する。
select a.NAME,a.VALUE from v$parameter a where a.NAME='log_buffer';

先ほどshared_pool_sizeをalter system文で変更したので同様に変更してみると、
alter system set log_buffer = 6775360 scope = memory;

変更できませんでした。これはlog_bufferの値は動的に変更できないように制限されているからです。
変更するには、初期化パラメータ―ファイルを変更しインスタンスを再起動する必要があります。
どの初期化パラメーターが現行値を変更できて、どの初期化パラメータ―が変更できないのかは以下のSQLで確認できます。
select a.NAME,a.VALUE,a.ISINSTANCE_MODIFIABLE
from v$parameter a where a.NAME in ('log_buffer','shared_pool_size');

ISINSTANCE_MODIFIABLEの値がFALSEの初期化パラメーターは動的に変更ができません。
初期化パラメータファイルの値を変更しインスタンスを再起動する必要があります。
次に初期化パラメータ―の値を変更したためインスタンスの起動に失敗した時の対処方法を実際に確認してみます。
sga_max_sizeの値を変更してインスタンスの再起動に失敗するケースでみていきます。
現在のsga_max_sizeの値を確認します。
select a.NAME,a.VALUE,a.ISINSTANCE_MODIFIABLE
from v$parameter a where a.NAME in ('sga_max_size');

VALUE値はグラニュルという最小単位で変更します。sga_max_sizeが1GB以下の時はグラニュルは4MBになります。
1GBより大きい場合、16MBになります。32ビットWindowsの場合は8MBになります。
現在、sga_max_sizeは440MBに設定されているため、グラニュルは4MBです。
1[MB] = 1024×1024 = 1048576[Byte]
4[MB] = 4194304[Byte]
sga_max_sizeを444MBに変更してみよう。

初期化パラメータ―ファイルの変更は成功しました。
データベースをシャットダウンして再起動してみます。

初期化パラメータ―の変更が影響してインスタンスの再起動に失敗してしまいます。
初期化パラメータ―ファイルの値を元の値に戻します。
データベースはシャットダウンしているためalter system文を使用することはできません。
また、SPFILEはバイナリファイルのためテキストエディタ等で編集してもとの値に戻すこともできません。
まずSPFILEからPFILEを作成します。
PFILEはテキストファイルのためテキストエディタで内容の編集が可能です。

間違えて変更してしまったSPFILEは不要のため別の名称に変更しておきます。
spfile + SID名 + .ora というファイル名をリネームすればよい。
C:\app\Admin\product\11.2.0\dbhome_1\database>rename SPFILEORA1.ORA SPFILEORA1.ORA.OLD
init + SID名 + .ora というファイルを編集して、今回変更した初期化パラメータファイルPFILEをSPFILEに戻す。

オラクルを再起動します。正常に起動しました。

システム載せ替えの思わぬ罠?
大規模なシステム更改の案件があり、その際にORACLEのバージョンを上げることに
なったのですが、その旧バージョンから次期バージョンの間に、実はメンバーの
認識していなかった仕様変更が含まれていた事が発覚しました。
それは、『GROUP BY句、DISTINCT句の暗黙的ソートが廃止になった』とのこと。
ソート順序に影響はないか、全ソースの調査が必要になりました。
どうも10g以降で廃止になったようです。(この辺りを参照)
http://otn.oracle.co.jp/forum/thread.jspa?threadID=2002356
http://otn.oracle.co.jp/forum/thread.jspa?threadID=35004433
知っている人にとっては、何を今更、な話題ではあると思うのですが、
システムのバージョンを上げる時は注意しないと、予期しないところで
仕様変更のあおりを受けることがある、という話でした。
(そもそも暗黙的な挙動に頼らないORDER BY句をちゃんと書いていれば問題はない訳で、
まあ念の為の調査という事で、実際影響は殆どなかったのですが。)
セキュアな通信
良い記事を見つけたのでメモ的に。
エンジニアなら知っておきたい、絵で見てわかるセキュア通信の基本
http://qiita.com/t_nakayama0714/items/83ac0b12ced9e7083927
ネットワーク上では疎かにすることの出来ない、情報セキュリティの話について、
分かり易く解説されています。
google検索の便利技☆ブログ part1
アパレル販売からのまさかのIT業界に転職という異色の新入WAKAです!
私が今回記事にするのはゴリゴリのプログラミングや、サーバー構築のお話しではなく、、、
みなさんお馴染み、、、ズバリ "Google" についてです。
調べものなんかでは普通に使っている "Google" だと思いますが
普通に検索するだけではもったいない!
今回はそんな "Google" の便利な検索技を紹介したいと思います(^^)
① 完全に一致するワードだけ検索したいとき
この方法は皆さんもご存じかもしれませんが、、、
ホテルや会社など、同じような名前のHPが検索結果で表示されますが、
探すのがめんどう!
こんなときに、完全に一致するようにダブルクウォーテーションで
検索ワード囲ってあげれば一発で見たかった情報を見つけることが出来ます!
"検索ワード"

② どちらかのワードを含む検索結果がみたいとき
右の画像からも分かるように、今度は複数の単語を含む検索がしたいときの方法を紹介します。
ピカチュウ もしくは カビゴン
の情報が知りたい!
そんなときはワードとワードの間に "OR" を入れるだけです!
これは組み合わせも可能なので
”ピカチュウ サトシ” OR ”カビゴン ポケモンGO”だと
ピカチュウ サトシ と完全に一致するもしくは
カビゴン ポケモンGO と完全に一致する情報が表示されます!
検索ワード1 OR 検索ワード2

③ あるワード含まない検索結果がみたいとき
カビゴンの情報を単体でみたいときってありますよね、、、
ピカチュウだと情報が大きくなっちゃので(@_@)
通常のワード検索の末尾に "-除外ワード"
をするだけであっという間にカビゴンの特集ページです!
検索ワード -除外ワード

④ 途中のワードを忘れちゃったとき
あの決め台詞なんだったっけ???
ポケモンとったときの、、、
とまあこんなモヤモヤとしたときの調べ方は
分からないワードのところを "*" にしちゃえばいいですね!
もちろん、
ポケモン*だぜ!
でもいいですし
*ゲットだぜ!
でもよいですよ。
検索ワード前半*検索ワード後半

⑤ 似たような画像を探したいとき
これと同じような画像ないかなあ?
そんなときは画像をアップロードすることで
Googleさんが自動で似たような画像を検索してくれます!
検索窓にあるカメラマークを選択すると
画像をアップロードできますので
後は検索してくれるのを待つだけ!
画像検索すれば、一番右のように
同じような画像がずらーっと表示されちゃいます


⑥ 画像検索の色とか種類で絞りたいとき
画像検索のプラス技が実はあったんです!
検索窓に検索ワードを入力し、画像検索します。
検索ツールというところをクリックすると
いろいろなオプションがでてきます。
そこで色やサイズ、または画像の種類などを選択すると
自分が見たいテイストのものに絞れちゃいますよ!(^^)!

⑦ ふとしたとき食材のカロリーが知りたいとき
これは小技というか言われてみればそうだったかも!
といった感じですが、料理をする人は調べたくなる内容かもしれません!
Googleでは料理名を検索すると、右側に写真、原産地、名前の由来や語源といった情報、栄養成分表などが表示されます。
そしてそれは食材なんかでも表示されるようになっているんです!
トマトやきゅうりなんかの野菜や、右の画像ではキムチなんかも表示されていることが分かりますね!
カロリー調べたい場合はぜひ使ってみてください(^^)/

Google検索のプラス技を7個ほどご紹介しました。
意外と知らないことも多かったのではないでしょうか
情報検索のうまい人って仕事できるようなあ~というイメージから
今回このような内容を記事にしてみました。
いらない情報につかまって時間を無駄にすることなく
スムーズに一発で情報が見つけられるようになりたいものです。
part1は本当に役立つ内容でしたが、part2は少し遊び心を入れてみたいと思います!
↓
google検索の便利技☆ブログ part2
アパレル販売からのまさかのIT業界に転職という異色の新入WAKAです!
前回の記事では意外としらなかった検索技を紹介しましたが
( 前回の記事→ google検索の便利技 part1 )
今回の記事では少し遊び心もいれた "Google" について紹介したいと思います。
① Googleがぐるぐると回っちゃう珍現象
これは昔からあるようなので
ご存知の方もいるはず!!!!
検索ワードに "一回転" と入力していざ検索してみると
なんとまさしく、ページごと一回転してくれちゃいます。
ついつい何度も検索してしまいました、、、
検索ワード = 一回転

② 傾いてしまったGoogle
①番でもご紹介したように、検索ワードに何かを入力すると
ページが微妙に傾いてしまいました。
回転する方を先に紹介したのでインパクトには欠けますが
少しのイタズラをしておくと知らない人はビックリするかもしれませんね、、、
検索ワード = 斜め

③ 重力に負けたGoogle
Google検索のトップ画面で
" Google gravity "と検索すると
Google gravity Mr.doob が結果表示されます。
そのリンクをクリックすると
重力に負けていろんなものが落ちてきちゃうという。。。
まあ実践してみるのが一番です!!!
検索ワード = Google gravity

④ パックマンで遊べちゃう
2010年5月21日に「パックマン誕生30周年」を記念して公開された、
パックマン。検索ワードにパックマンとして検索すると一番上にパックマンのDoodleが表示されます。
Doodle公開期間が過ぎているのでもうできないと思いきや
なんと今でも遊べるようになっているようです。
検索ワード = パックマン

⑤ ブロック崩しで遊べちゃう
検索窓に「atari breakout」と入力し、画像検索をしてみると
なんと検索結果の画像がブロックに変化し、ブロック崩しを楽しむことができるようになります!
ビデオゲームのブームを作った「ブロック崩し」の元祖、米ATARI社の「Breakout」発売37周年を記念して作られたDoodleですね!
37周年記念の限定かと思われてましたが
今でも出来ちゃうのがいいですね!!
検索ワード = atari breakout

⑥ かわいかったGoogleアレンジ
グーグル検索のページで「Google」のロゴが、その日を祝うデザインになっているときがあります。
これに名前がついていることはご存知でしたか???
グーグルは「Doodle(ドゥードゥル)」と命名しているようです。
「doodle(ドゥードゥル)」には
「いたずら書き」という意味もあって
「Google」のつづりとも韻を踏んでいて遊び心に富んでますよね。
見過ごしていた方も多いと思いますが、デザイン性も豊かで
ムービーバージョンなんかもあるので過去のも見たくなります。
そんなときは、、、
googleトップ画面の I feeling lucky を押してみましょう!!!

画像編集フリーソフト paint.net
・paint.net で画像合成

画像の編集をしようと思ったとき、Windows付属のペイントではやりたいことが出来なかったり面倒だったりします。
例えば画像の合成をしようと思えば、ペイントではいろいろと面倒です。
ペイントの場合の手順は、まず下地にする画像を編集状態で読み込みます。
そして、合成したい画像(背景が透過されているpng画像)を貼り付けの「ファイルから貼り付け」を選択します。
「ファイルから貼り付け」をした画像が選択状態のままで「透明の選択」を選びます。
この時に、「透明の選択」を選ばなければ透過部分が白い背景となってしまうので注意が必要です。
以上の手順でペイントでも画像の合成は可能なのだが、選択状態を解除してしまうと位置の調整が出来なくなってしまいます。
さて、それでは今回紹介するpaint.netでの画像合成の方法を紹介します。
まずは、フリーソフト「paint.net」をインストールするところから始めましょう。
インストールなどは、以下のURLからすることができます。
① 合成する画像の準備
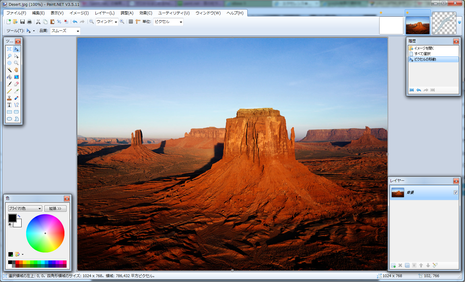
では今回は、右の画像に適当なフリーの画像を合成してみようかと思います。
まず、paint.netにて下地にする画像を開きます。
そしてさらに、合成させる画像を開きます。
今回使用した画像は、フリーで拾ってきた背景が既に透過されているpng画像ファイル。
右の画像の右上にpaint.netで開いた画像の一覧が表示されます。
下地用の砂漠画像と、合成するプテラノドンの画像ですね。
② 2種類の画像を合成
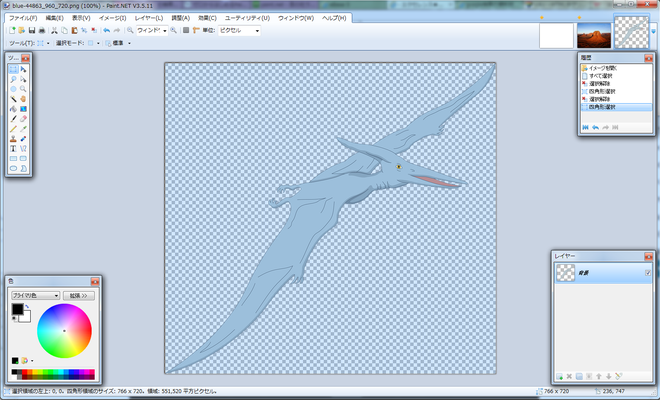
次に、右上の開いているプテラノドンの画像を選択してアクティブにします。
そして画像全体を選択して、コピーをしましょう。(左下の画像参照)
コピーをしたら、下地画像をアクティブにして右下にあるレイヤーというサブウィンドウを操作します。
レイヤーサブウィンドウの最下部にある「×」マークの左側にある選択項目をクリックすればレイヤーを追加することが出来ます。(中央の画像参照)
そして、追加されたレイヤーにチェックが入っていることと、一番上に来ていることを確認したら、先ほどコピーしたプテラノドン画像を貼り付けます。(右下の画像参照)


③ 合成した画像のサイズ調整

さて、コピーした画像を貼り付けたものの、サイズが大きくて変な感じになっているので、サイズを調整しましょう。
貼り付けた画像の右下の角にある○マークにカーソルを合わせてサイズを調整します。
ここで普通にサイズを変更しようとすると、縦と横の比率がおかしくなってしまうのでshiftボタンを押しながら調整してみましょう。
shiftボタンを押しながら調整すると、縦と横の比率を維持しながらサイズを調整することができます。
こうすることによって、右画像のように砂漠の上空を飛ぶプテラノドン画像の出来上がりとなります。
④ 画像の保存

それでは最後に、合成した画像を保存してしまいましょう。
保存を選択すると右のような画面になると思います。
この「pdnファイル」というのは、paint.netで行った画像編集作業の編集状況を保存するというものです。
つまり、1枚の画像として保存するのではなくてプロジェクトを保存するという感じでしょうか。
このpdnファイルを開けば、編集作業の再開や修正を行うことが出来ます。
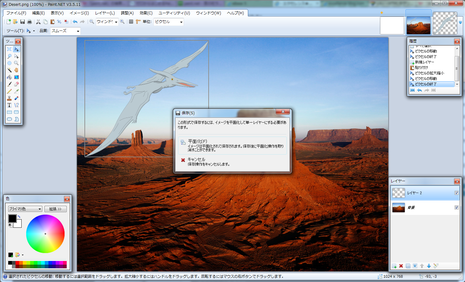
というわけで、編集した内容を1枚の画像として保存するには、保存をするときに「ファイルの種類」から保存したいファイル形式を選択します。
ファイル形式を選択した後、保存ボタンを押す。
すると、「構成の保存」というサブウィンドウが出てくるので、ここで「OK」を選択。
そして最後に、「平面化」と「キャンセル」を選ぶ画面になるので、「平面化」を選択します。
これにて、1枚の画像として編集した画像を保存することが出来ます。
以上で、paint.netを使った画像の合成方法の紹介を終了します。
他にもpaint.netには様々な機能があるので、試してみてはいかがでしょうか。
C→C# 移殖MEMO
移殖作業は、答えとなる稼働中システムがあるため作業難度は低いんですが、
2つの言語仕様を理解していないとちょっとした勘違いではまってしまうことが、、、
そんな移植作業(C言語からC#)で発見したちょっとしたネタを紹介。
1.int int_array??(5??) = ??< 1, 2, 3, 4, 5 ??>;
見出しの処理はC言語で書かれたコード。
なんだこれ、普通に読めない。
??はC#ではnull合体演算子だけど、C言語でそんなのあったっけ?
文字化けしたんかな?
チーム内で誰も知らないし、ちょっと調べてみることに
実はトライグラフという機能を使ってコーディングしたものだと判明。
同じソースをトライグラフを使わずにコードすると次の通り。
int int_array[5] = { 1, 2, 3, 4, 5 };
トライグラフは「ISO 646 に共通して含まれる文字だけでソースコードを書くための表記法」だそうで、
3文字の組み合わせでISO 646 に足りない範囲の文字を表現しようというもの。
うーんわかりにくい。
※トライグラフの一覧
??= → #
??( → [
??/ → \
??) → ]
??' → ^
??< → {
??! → |
??> → }
??- → ~
2.-1が1より大きい?
int a = -1;
uint b = 1;
if (a > b) { ① }
else { ② }
実は上のコード、C言語とC#で結果が変わります。
C言語 : 処理①が実行
C# : 処理②が実行
-1 > 1 だから「偽」になるべき(C#の動作)では?
何で①に?
よくわからないので調べてみることに、
比較する際にデータ型が異なる場合、暗黙の型変換を行いますが、
変換仕様が異なるためにこんな現象が発生しています。
C言語では uint > int の優先順位のため、intからuintに変換して判断されます。
例の場合、aの-1がuintに変換されるため、
4,294,967,295 > 1 となり「真」と判断されます。
C言語では、データ型の異なる変数同士の比較はやめておきましょう。
VC++ソフトは実行環境の確認が大切!
最近すこし嵌ったこと
ミッション:よそのチームが管理しているVC++で作成されたDLLの動作を調査する
前提:
・私のPCにはVisualStudio2010、2012がインストールされている
・これまでの開発でバージョンに起因する問題は発生していない
・DLLのソースコードは一部しかなく、自分でビルドすることはできない
・DLLは動的呼び出しをすることになっていて、呼び出すだけのテストプログラムは作成済み
・そのDLLは他メンバーのPC上では呼び出せているので、あとは入出力パスなどの環境を整えるだけのハズ
事件:
私のPCではなぜかDLLの動的読み込みに失敗
DLLはバージョン違い(A.dll、B.dll)があり、B.dllは読めたが、A.dllが読み込めない
さらに、VM上のテスト環境で実行すると、両方とも読み込めない
メインの調査対象はB.dllなので一応動作確認を進められるが、最新のテストデータを入力すると正常動作しない
調査:
自分のVisualStudio2012で簡単なIFでDLLを作成し同じように呼び出してみると、やっぱりVMでは失敗する
VMには開発環境が入っていないので、それが開発環境に付随するコンポーネントが足りないと推測
google先生にDLLが足りないならDependency Walkerを使いなさいと教えてもらったので使ってみる
なんかエラーがあると表示しているが、使い慣れないツールは見方がさっぱりわからず、、、
ここで、VM上のWindowsのイベントログを確認(Windowsメニューからアクセサリのイベントビューアーを選択)
B.dll呼び出し時に発生したエラーとして、MSVC?80?.dllが無いというエラー発見!!
調べてみると、どうやらVC++2005でビルドしたC++アプリ用のコンポーネントらしい
というわけで、VC++2005再配布可能パッケージというものを探す
x86/x64用があるのはまだわかるが、さらにSP1用まであったりして、とりあえず片端からインストール
ここまででやっとVM側でもB.dllが読める状態になったけど、やっぱりA.dllは読み込めない
次にA.dll呼び出し時のイベントログを確認
足りないのは?????.Debug.dllだそうな
つまりA.dllはデバッグビルドなので、再配布可能パッケージではなく開発環境そのものがなければ実行できない
自分のPCには開発用にいろいろインストールしていて、認識しないままVC++2005再配布可能パッケージも
含まれていたけど、VC++2005の開発環境ではないので、A.dllが読み込めなかった
他メンバーはたまたま別件でVC++2005の開発環境をインストールしていて読み込めていたというわけ
おまけ:
結局B.dllは読み込めることが確認できたけど、特定のバージョンのテストデータでないと動作しない
つまり最新のテストデータ用のDLLが別途必要なのでは?
というわけで、最新のバージョンのDLL(C.dll)をもらってやっと動作確認できる状態になりました
考察:
さんざんVisualStudioで開発してきたが、あまり実行環境を意識していなかったことを反省
これがEXEや静的呼び出しのDLLなら、起動エラーダイアログが出るのでこの問題にはすぐ気づいたはず
⇒★なんかよくわからない異常が発生したときは、Windowsのイベントビューアーが役に立つことがある
Excel/Word/PowerPoint VBA の比較
Windows 7, Office 2013 を想定。
CreateObjectの挙動
早速だけどVBAとは直接関係がない。
Excel/Word/PowerPointを外部から利用する場合の話(オートメーション)。
PowerPointだけ挙動が異なる。
CreateObject("Excel.Application")
→新たにExcelを起動し、その(Application インスタンスへの)ポインタを返す。
CreateObject("Word.Application")
→新たにWordを起動し、その(Application インスタンスへの)ポインタを返す。
CreateObject("PowerPoint.Application")
→既にPowerPointが起動されている場合、(新たにPowerPointを起動することなしに)既存インスタンスへのポインタを返す。
起動されていなければ、新たにPowerPointを起動し、その(Application インスタンスへの)ポインタを返す。
どうしてこうなるのか?
→PowerPointは多重起動できない仕様とのこと。
PowerPoint の Application オブジェクトを理解する - MSDN - Microsoft
Outlook 以外の Office アプリケーションとは異なり、同時に使用可能な PowerPoint のインスタンスは 1 つのみです。PowerPoint のインスタンスが実行中に New キーワード、CreateObject 関数、または GetObject 関数を使用して PowerPoint オブジェクト変数のインスタンスを作成する場合、そのオブジェクト変数は現在実行されている PowerPoint のインスタンスをポイントします。
これで困ること
CreateObjectして最後にQuitするようなコードを書くと、最初から開いていたPowerPointまで勝手に終了されてしまう。
Dim pptApp As Object
Set pptApp = CreateObject("PowerPoint.Application") ' ←ここで、既存のPowerPointインスタンスが取得される
' ... pptAppを使った何らかの処理
pptApp.Quit ' ←既存のPowerPointインスタンスを終了する
対策
事前にGetObjectを使って、PowerPointが起動しているかどうかを確かめる。
起動していなかった場合のみ、Quitで終了させるようにする。
(既に起動していた場合、既存のPowerPointインスタンス上で処理が行われるという点は変わっていないので注意)
Dim pptAppIsNewInstance As Boolean
Dim pptApp As Object
On Error Resume Next
Set pptApp = GetObject(, "PowerPoint.Application") ' ←ここで、PowerPointが起動していなかった場合エラーが発生する
pptAppIsNewInstance = Err.Number
On Error GoTo 0
If pptAppIsNewInstance Then
Set pptApp = CreateObject("PowerPoint.Application")
End If
' ... pptAppを使った何らかの処理
If pptAppIsNewInstance Then
pptApp.Quit
End If
ちなみに↓ここで「別のユーザーとして実行することでPowerPointを多重起動できる」という回答がある。
2つめのPowerPoint ファイルを別ウィンドウで開きたい - 教えて!goo
頑張れば既に起動しているのとは別のPowerPoint上で処理を実行できるかもしれない。
パスワード付きのファイルを開く
(ここでいうファイルとは、Excelブック、Wordドキュメント、PowerPointプレゼンテーションのこと)
単にファイルを開くだけならそれぞれ
Workbooks.Open(FileName)
Documents.Open(FileName)
Presentations.Open(FileName)
でいける。これだと、パスワードで保護されたファイルを開くときダイアログが表示される。
ダイアログなしで開きたい場合はパスワードを指定する必要がある。
(コードにパスワードを埋め込むことになるので、あまり使用機会はないかもしれない)
Excel
Workbooks.Open メソッドの Password パラメータと WriteResPassword パラメータを指定する。
Excelブックには読み取り用パスワードと書き込み用パスワードを別々に設定できるので、読み取り用パスワードを Password に、書き込み用パスワードを WriteResPassword に指定することになる。
Workbooks.Open FileName, _
Password:="読み取り用パスワード", _
WriteResPassword:="書き込み用パスワード"
Word
Documents.Open メソッドの PasswordDocument パラメータ、WritePasswordDocument パラメータ、PasswordTemplate パラメータ、WritePasswordTemplate パラメータを指定する。
WordドキュメントもExcel同様、読み取り用パスワードと書き込み用パスワードを別々に設定できる。それに加えて、Wordではドキュメントにテンプレートが紐付けられ、テンプレートにも読み取り用パスワードと書き込み用パスワードが設定される可能性がある。
Documents.Open FileName, _
PasswordDocument:="ドキュメントの読み取り用パスワード", _
WritePasswordDocument:="ドキュメントの書き込み用パスワード", _
PasswordTemplate:="テンプレートの読み取り用パスワード", _
WritePasswordTemplate:="テンプレートの書き込み用パスワード"
PowerPoint
PowerPointも同様に Presentations.Open メソッドのパラメータを指定すればいいのかと思いきや該当するものがない。
ファイルパスの後に :: (コロン2つ)で区切って、読み取り用パスワード→書き込み用パスワード の順に指定してやればいいとのこと。
Presentations.Open FileName & "::" & "読み取り用パスワード" & "::" & "書き込み用パスワード"
sshで穴掘って内部のWEBサーバーに接続する
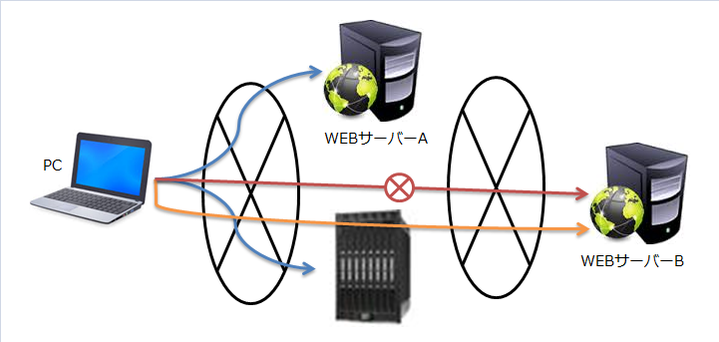
下図のようなネットワーク環境になっている環境でPCから直接アクセスできない
WEBサーバーのWEBコンテンツを閲覧する方法を紹介しようと思います。
例)
・PCからWEBサーバーAはネットワークでつながっているのでWEBコンテンツの閲覧ができる。(図中青線)
・PCからWEBサーバーBは異なるネットワークとなっており、直接WEBコンテンツは閲覧することができない。(図中赤線)
・異なるネットワークの両方に繋がるマシンがある。(図中中央下にあるマシン)
異なるネットワークの両方に繋がるマシンにPCからSSH(ポート22)で接続することが可能であれば、両方に繋がるマシンをトンネルにして、PCからWEBサーバーBのWEBコンテンツを閲覧することが可能になる。(図中橙線)

今回使うのは「Putty」というフリーのTelnetツール。
このツールはTelnetやSshという方法でリモート接続するツールです。
http://hp.vector.co.jp/authors/VA024651/download.html
Step1:まずは穴掘り(SSHトンネル)準備
puttyを起動したら、左メニューからConnection>SSH>Tunnelsを選択します。
DynamicのラジヲボタンとAutoのラジヲボタンにチェックし、Source portに適当なポート(自分のPCで使っていないネットワークサービスポート)を入力し、Addボタンをクリックします。

Step2:穴掘り開始(SSH接続)
次に左メニューよりSessionをクリックし、HostName欄に接続可能なIPアドレスを入力し、ポート欄に22を入力します。SSHのラジヲボタンにチェックし、下部のOpenボタンをクリックします。
接続できた後、ログオンして放置してください。

Step3:穴を使ってWEBサーバに接続する(Socks)
次に、ブラウザを起動し、プロパティを開きます。
FireFox :
ツール>オプション>詳細>ネットワーク
接続設定ボタンをクリックすると、以下の画面になります。
SOCKSホスト欄にlocalhostか、127.0.0.1と入れ、ポートに先ほどPuttyで登録したポートを入力して、OKをクリックします。
IE:
ツール>インターネットオプション>接続
LANの設定をクリック
次にプロキシを使用するにして、詳細設定ボタンをクリック
Socksにlocalhostか、127.0.0.1を入力し、ポートにputtyで登録したポートを入力後、OKをクリックし、登録します。
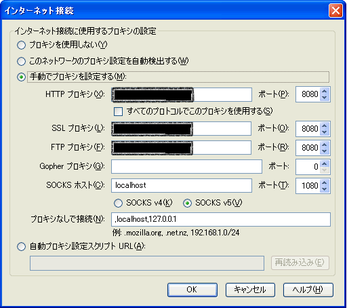
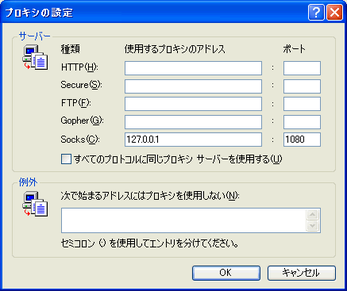
Step4:ブラウザで閲覧する
ステップ3までできていれば、あとは、通常のWEB閲覧のようにURLを入力すれば、WEBアクセスができます。
PC側ブラウザはPCがそのままWEB接続しているかのように処理をします。
一方でWEBサーバー側ではトンネルしているサーバーがアクセスしてきているように処理します。
Ajaxでドラッグ&ドロップのファイルアップロード
よく見かけるドラッグアンドドロップでファイルをアップロードする方法を試してみた。
画面側での実装を記載しておく。
もちろん、サーバー側でアップロードのリクエストを処理する必要はあるが、ここでは割愛する。
HTML
<html>
<head>
<title>画像をドラッグ&ドロップで一括アップロード</title>
</head>
<body>
<div id="image_upload_section">
<div id="drop" style="width:700px; height:150px; padding:10px; border:3px solid;"
ondragover="onDragOver(event)" ondrop="onDrop(event)" >
ファイルをドラッグアンドドロップしてください。複数ファイル同時も対応しています。
</div>
</div>
</body>
</html>
JavaScript(jQueryは使える前提)
<script type="text/javascript">
// File APIに対応していない場合はエリアを隠す
if (!window.File) {
document.getElementById('image_upload_section').style.display = "none";
}
// ブラウザ上でファイルを展開する挙動を抑止
function onDragOver(event) {
event.preventDefault();
}
// Drop領域にドロップした際のファイルのプロパティ情報読み取り処理
function onDrop(event) {
// ブラウザ上でファイルを展開する挙動を抑止
event.preventDefault();
// ドロップされたファイルのfilesプロパティを参照
var files = event.dataTransfer.files;
for (var i=0; i<files.length; i++) {
// 一件ずつアップロード
imageFileUpload(files[i]);
}
}
// ファイルアップロード
function imageFileUpload(f) {
var formData = new FormData();
formData.append('image', f);
$.ajax({
type: 'POST',
contentType: false,
processData: false,
url: 'http://example.com/image/upload',
data: formData,
dataType: 'json',
success: function(data) {
// メッセージ出したり、DOM構築したり。
}
});
}
</script>
htmlのキャッシュについて
久しぶりにrewrite定義を追加してコンテンツのfailbackを考える機会がありました。
rewriteをすると、いつもproxyキャッシュやブラウザキャッシュでトラブルなぁと苦い思い出があります。
その際の対応として、キャッシュをさせない設定をHTMLに埋め込むのですが、毎回調べるので、
メモしておきます。
前置きとしてWEBのキャッシュとは。
ブラウザからWEBサイトにリクエストを発行すると、コンテンツがレスポンスされます。
この挙動によりWEBサイトを閲覧しているのですが、WEBサイトのコンテンツは大きいものから小さいものまであります。特に毎回大きいサイズのWEBコンテンツを表示するために通信を行うと、非効率です。
そのため、Proxy(プロキシ)やブラウザは、過去にアクセスしたWEBコンテンツを一時保存しておいて、アクセスするたびにコンテンツを要求しないようにして効率的に通信します。。これがWEBキャッシュ。
WEBキャッシュはhtmlや画像(gif、jpg等)、静的コンテンツと呼ばれる、毎回アクセスする度に変化が起きないものを一時保存します。
動的コンテンツ(asp、jsp、php等)は、毎回アクセスする度に変化が起きるためキャッシュされないようにアプリケーションサーバがキャッシュしない命令を埋め込んでくれています。
このようにキャッシュは便利に思えるのですが、一時的にコンテンツを置き換えた時など、キャッシュされてしまうと困ることもあります。
そのような場合、キャッシュをさせない方法があります。
HTTPヘッダーで制御する方式
キャッシュ制御の定義はRFC2616にて規定されています。
RFC2616に従うと、HTTP通信のリクエストヘッダー、および、レスポンスヘッダーに以下の定義を加えることでキャッシュをコントロールできます。
Cache-Control (HTTP/1.0では効果なし)
- public 共有のキャッシュとして使え
- private 非共有のキャッシュとして使え
- no-cache 再利用可能なキャッシュかどうか判断した上で使え(注意:キャッシュするなではない)
- no-store キャッシュするべからず
- max-age=? 指定した秒数がキャッシュの有効期限
- min-fresh=? 指定した秒数キャッシュが最新と判断する
- max-stale=? 指定した秒数は最新でなかろうと受け入れる
Pragma(HTTP/1.0でのみ効果)
- no-cache キャッシュを使うな
HTTPのMETAタグで制御する方式
(注意)
METAタグにて制御する方式は広くWEBで公開されているが、効果が確実なものではありません。
RFC2616によると、キャッシュの命令はレスポンスヘッダーにて定義するものと規定されているので、
ここから紹介するMETAタグ方式はブラウザやProxyが独自に取り入れているものと言えます。
つまり、この方式はブラウザやProxyに依存するもので、確実に効果があるとは言えません。
HTML4.xまでの書き方
<meta> 要素の http-equiv 属性に Pragma, Cache-Control, Expires などを指定して制御します。
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <!-- この設定でHTTP1.0プロトコルでProxyキャッシュさせない //--> <meta http-equiv="Pragma" content="no-cache"> <!-- この設定でHTTP1.1プロトコルでProxyキャッシュさせない //--> <meta http-equiv="Cache-Control" content="no-store"> <!-- この設定でキャッシュされたコンテンツの有効期限を即切れにする。ブラウザキャッシュ対応 //--> <meta http-equiv="Expires" content="0"> <title>page title here</title> </head> <body> ... </body> </html>
http-equiv="Pragma" はHTTP1.0プロトコルでしか判別できない古いProxyに対応するために記載する。値はno-cacheにすることで、キャッシュされない。
http-equiv="Cache-Control"はHTTP1.1プロトコルに対応したキャッシュ指定。値の候補は4種類あるが、キャッシュさせない設定はno-cacheとno-storeである。
no-cacheは間違えて紹介されているサイトが多いので注意が必要。キャッシュさせないのではなく、キャッシュされるが、If-Modified-Sinceをリクエストし、コンテンツが有効でない限りキャッシュを利用してはならないという意味である。
全くキャッシュさせないためにはno-storeを定義する。
http-equiv="Expires"はブラウザキャッシュに対応するために定義する。ブラウザのキャッシュの有効期限を0にすることで、即有効期限切れにするため、キャッシュしていない状態とほぼ同等になる。
ただし、これに対応されていないブラウザも存在するため、確実なものではない。
HTML5の書き方
<html> 要素の manifest 属性でキャッシュマニフェストファイルの URI を指定します。
manifest 属性は、キャッシュ対象にするすべてのページに指定する必要があります。 manifest 属性が含まれていないと、キャッシュマニフェストファイルで明示されていない限り、ブラウザはそのページをキャッシュしません。
<!DOCTYPE html> <html lang="ja" manifest="sample.appcache"> <head> <meta charset="UTF-8"> <title>page title here</title> </head> <body> ... </body> </html>
例)sample.appcashe
CACHE MANIFEST # version: 1.0.0 CACHE: sample.gif FALLBACK: /test.py /sorry.html NETWORK: *
この例では、 sample.gif というファイルはキャッシュされ、それ以外のリソースはキャッシュせずにサーバーから取得させるようにしています。
また、/test.py が取得できない時は /sorry.html をフォールバックリソースとして提供するようにしています。
CACHE MANIFEST
1行目の CACHE MANIFEST はキーワードで、必ずこの文字列を1行目に記述する必要がある。
コメント
# で始まる行はコメント。
キャッシュファイルを更新するようにブラウザに通知するには、マニフェストファイルが更新される必要がある ので、キーワードのすぐ後にバージョン番号等を入れる。
CACHE:
CACHE: セクション(または CACHE MANIFEST のすぐ下)に、キャッシングするリソースの URI を列挙する。
ワイルドカードは使用できない。
NETWORK:
NETWORK: セクションには、サーバーへの接続を必要とするリソースの URI を列挙する。
こちらは、ワイルドカードを使用できる。
FALLBACK:
FALLBACK: は、リソースにアクセス出来ない場合のフォールバックページを指定する。
ワイルドカードを使用ができる。
行の最初の URI は対象リソース(本丸)で、2つ目の URI がフォールバック(代替)。
自動化(T4 Template)
現在、C→C#の移植作業をしています。
手作業でちまちましている箇所を、自動化できたらいいなと思いました。
そこで、構造体をクラスに移植する場合を考えます。
使用するもの
方法
① テキストテンプレートを作成する。拡張子は.tt。
【説明】
<#@ ディレクティブの指定 #>
<# 複数のステートメント #>
<#= 単一の式 #>
<#+ 関数やクラス #>
<#>がない箇所はそのまま作成される。
<#@ template debug="false" hostspecific="true" language="C#" #> ←ポイント①ファイルを読み込むときはhostspecific="true"にする
<#@ assembly name="System.Core" #>
<#@ import namespace="System.Linq" #>
<#@ import namespace="System.Text" #>
<#@ import namespace="System.Collections.Generic" #>
<#@ output extension=".cs" #>
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Test
{
<#
string cName = string.Empty;
foreach (var line in System.IO.File.ReadLines(this.Host.ResolvePath("Data.txt"), Encoding.GetEncoding("shift_jis")))
{
var s = line.Split('\t').ToList();
if(cName == string.Empty)
{
cName = s.First();
#>
public class <#= cName #>
{
<# continue;
}
var data = new Data(s);
#>
/// <summary>
/// <#= data.Description #>
/// </summary>
public <#= data.Type #> <#= data.ItemName #> { get; set; }
<#
}
#>
}
}
<#+
private class Data
{
// クラス名
public string ClassName { get; set; }
// 型
public string Type { get; set; }
// 項目名
public string ItemName { get; set; }
// 説明
public string Description { get; set; }
private static Dictionary<string, string> TypDic = new Dictionary<string, string>()
{
{"UD", "int"}, ←ポイント②定義しておいたら後で迷わなくてすむ
{"DD", "uint"},
{"UW", "short"},
{"UB", "byte"},
};
public Data(List<string> s)
{
Type = TypParse(s[0]);
ItemName = ItemParse(s[1]);
Description = s[2];
}
private string TypParse(string str)
{
string ret;
if(!TypDic.TryGetValue(str, out ret))
{
return "string";
}
return ret;
}
private string ItemParse(string str)
{
return str.Substring(0, 1).ToUpper() + str.Substring(1).ToLower();
}
}
#>
② 新規ファイルを作成。一行目に作成したいクラス名、以降の行は型,項目名,説明をタブ区切りで定義する。
(そもそもこれを作るのが面倒ということは置いておく...)
(例)
学生クラス UD id 学籍番号 char name 氏名 UD age 年齢 UD schoolyear 学年
③ テンプレートを実行する。
実行結果は下記のようになる。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Test
{
public class 学生クラス
{
///
/// 学籍番号
///
public int Id { get; set; }
///
/// 氏名
///
public string Name { get; set; }
///
/// 年齢
///
public int Age { get; set; }
///
/// 学年
///
public int Schoolyear { get; set; }
}
}
まとめ
【メリット】
移植元ソースは独自の型が定義されているので、自分で確認して移植しないといけない。
ディクショナリーであらかじめ定義しておけば、悩まなくてすむし、忘れていても問題ない。
また、データが大量にある場合は、手作業で行うよりはミスが減るはず。
【デメリット】
移植元ソースをただ読み込むだけだと使用できないので、コピペしてファイルを作成しないといけない。
(読み込みを工夫したらいけますかね?)
結局そのひと手間が必要なので、自動化の道は遠い...。
現状関係ないが、エクセルを読み込むこともできるらしいので、エクセルの大量データを定義する場合は多少は使えるかもしれない。
openSSLを用いたAES暗号化
・openSSL
⇒オープンソースで開発・提供されるソフトウェア。
SSL(Secure Sockets Layer)はセキュリティ通信を行うプロトコル。
・AES暗号化(Advanced Encryption Standard)
⇒秘密鍵を用いた暗号方式。
鍵長:128bit/192bit/256bit
ブロック長:128bit/192bit/256bit
■暗号化処理
/* ①初期化 */
int EVP_EncryptInit_ex(EVP_CIPHER_CTX *ctx, const EVP_CIPHER *type, ENGINE *impl,
unsigned char *key, unsigned
char *iv);
⇒引数
・[ctx] 暗号コンテキスト
・[type] 暗号アルゴリズム(※)
・[impl] 暗号化用に初期化(NULLでデフォルト指定)
・[key] 共通鍵暗号の鍵
・[iv] 初期ベクトル
/* ②暗号化 */
int EVP_CipherUpdate(EVP_CIPHER_CTX *ctx, unsigned char *out, int *outl,
unsigned char *in, int inl);
⇒引数
・[ctx] 暗号コンテキスト
・[out] 暗号化後
・[outl] [out]のサイズ
・[in] 暗号化前(平文)
・[inl] [in]のサイズ
/* ③最後のブロックの暗号化 */
int EVP_CipherFinal_ex(EVP_CIPHER_CTX *ctx, unsigbed char *outm, int *outl);
⇒引数
・[ctx] 暗号コンテキスト
・[outm] 最終ブロックの暗号化
・[outl] [out]のサイズ
/* ④解放 */
void EVP_CIPHER_CTX_cleanup(EVP_CIPHER_CTX *ctx);
⇒引数
・[ctx] 暗号コンテキスト
■復号処理
/* ①初期化 */
int EVP_DecryptInit_ex(EVP_CIPHER_CTX *ctx, const EVP_CIPHER *type, ENGINE *impl,
unsigned char *key, unsigned
char *iv);
⇒引数
・[ctx] 復号用のコンテキスト
・[type] 暗号関数(EVP_aes_128_cbc)
・[impl] 暗号化用に初期化(NULLでデフォルト指定)
・[key] 共通鍵暗号の鍵
・[iv] 初期ベクトル
/* ②復号 */
int EVP_CipherUpdate(EVP_CIPHER_CTX *ctx, unsigned char *out, int *outl,
unsigned char *in, int inl);
⇒引数
・[ctx] 復号用のコンテキスト
・[out] 復号後(平文)
・[outl] [out]のサイズ
・[in] 復号化前(復号化)
・[inl] [in]のサイズ
/* ③最後のブロックの復号 */
int EVP_CipherFinal_ex(EVP_CIPHER_CTX *ctx, unsigbed char *outm, int *outl);
⇒引数
・[ctx] 復号用のコンテキスト
・[outm] 最終ブロックの復号
・[outl] [out]のサイズ
/* ④解放 */
void EVP_CIPHER_CTX_cleanup(EVP_CIPHER_CTX *ctx);
⇒引数
・[ctx] 復号用のコンテキスト
①初期化処理
(※)暗号アルゴリズム
・EVP_aes_128_cbc
⇒(aes)AES暗号化、(128)ビット、(cbc)CBCモード
・CBCモード(Cipher Block Chaining Mode)
⇒平文の各ブロックは前の暗号文のXOR(排他的論理和)を取る形式で
最も広く用いられている暗号利用モード。
・その他の暗号利用モード
ECPモード(Electronic Codebook)
CFBモード(Cipher Codebook)
OFBモード(Output Codebook)
②暗号化(復号)処理
[in]から始まる [inl]バイトのデータを暗号化 (復号)する。
[out]に出力する [out]に書き込まれたバイト長が [outl]に設定される。
連続するデータブロックを暗号化(復号)する際は当関数を複数回呼び出す。
③最終ブロックの暗号化(復号)処理
ブロック長に満たないデータをパディング処理し暗号化(復号)する。
④解放
暗号(復号用)コンテキストを解放する。
・補足
ヘッダファイル[openssl/evp.h]をインクルードする。
#include <openssl/evp.h>
以上
BIGIP(F5) Memo No.1 iRuleでAccessLog
私のBIGIPとの付き合いは、BIGIPv4のセットアップから始めて今年でキャリア15年。
v12をコツコツセットアップしながら過ごしている日々です。
培ったスキルを紹介していこうと思います。
BIGIP(LTM)でAccessLog(Apache風)を出す方法
ロードバランサの前後でWEB通信のレスポンスを計測したい時はtcpdumpを取得するのが正攻法ですが、
通信パケットをサーバー屋さんが解析するのは一苦労。ネットワーク屋さんにお世話になるはめになりますね。
サーバー屋さんは、Apacheのアクセスログみたいなの取りたいと思うことでしょう。
じゃあ、実現してあげましょうと、作ってみたiRuleです。
apacheのケース
CustomLog /../apache/logs/ssl_request_log "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\"
\"%{User-Agent}i\" %T %{JSESSIONID}C %{SSL_PROTOCOL}x %{SSL_CIPHER}x %D"
iRuleで書いた場合
when HTTP_REQUEST {
set http_request_time [clock clicks -milliseconds]
set request_log_line "\
[HTTP::request_num],\
[IP::remote_addr],\
[HTTP::method],\
[HTTP::version],\
[HTTP::host],\
\"[HTTP::uri]\",\
\"[HTTP::header value Referer]\",
\"[HTTP::header User-Agent]\",\
\"[HTTP::cookie value JSESSIONID]\",\
[SSL::cipher name],\
[SSL::cipher version],\
[SSL::cipher bits]"
}
when HTTP_RESPONSE {
set http_response_time [ clock clicks -milliseconds ]
log local0. "$request_log_line,\
[HTTP::status],\
[HTTP::payload length],\
[expr $http_response_time - $http_request_time]"
}
HTMLでカメラを作る
紹介内容
html5で追加された「WebRTC」の機能を使えば、ブラウザからカメラを起動して、写真を写すことができます。
今回はブラウザからカメラを起動して、写真を写して、jpeg画像としてダウンロードするところまで作ってみます。
概要
html5の「video」領域にWebカメラの映像を映し、それを「canvas」領域にコピーし、さらにそれを「img」領域に書き出します。
canvasは見せる必要がないため、隠します。
img領域を右クリックでダウンロードすれば、ファイルとして作成できるという流れです。
WebRTCの「getUserMedia」というメソッドによってカメラにアクセスします。
Chrome、Firefox、Operaなどが対応しています。一方でIEやSafariは未対応となっています。
ブラウザを使用しますが、http通信はlocalhostへのみ可能です。外部からアクセスして利用するにはhttps通信にしなければいけません。
ソース
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
</head>
<style>
#camera {
width: 350px;
height: 280px;
transform: rotateY(180deg);
}
#img {
width: 350px;
height: 280px;
}
</style>
<script src="//ajax.googleapis.com/ajax/libs/jquery/2.1.4/jquery.min.js"></script>
<script>
<!--
$(function() {
//videoタグを取得
var video = document.getElementById('camera');
//カメラが起動できたかのフラグ
var localMediaStream = null;
//カメラ使えるかチェック
var hasGetUserMedia = function() {
return (navigator.getUserMedia || navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia || navigator.msGetUserMedia);
};
//エラー
var onFailSoHard = function(e) {
console.log('Error!', e);
alert("Error !");
};
if(!hasGetUserMedia()) {
alert("Unsupported browser.");
} else {
window.URL = window.URL || window.webkitURL;
navigator.getUserMedia = navigator.getUserMedia ||
navigator.webkitGetUserMedia || navigator.mozGetUserMedia ||
navigator.msGetUserMedia;
navigator.getUserMedia({video: true}, function(stream) {
video.src = window.URL.createObjectURL(stream);
localMediaStream = stream;
}, onFailSoHard);
}
$("#snap").click(function() {
if (localMediaStream) {
var canvas = document.getElementById('canvas');
//canvasの描画モードを2sに
var ctx = canvas.getContext('2d');
var img = document.getElementById('img');
//videoの縦幅横幅を取得
var w = video.offsetWidth;
var h = video.offsetHeight;
//同じサイズをcanvasに指定
canvas.setAttribute("width", w);
canvas.setAttribute("height", h);
//canvasにコピー
ctx.drawImage(video, 0, 0, w, h);
//imgにpng形式で書き出し
img.src = canvas.toDataURL('image/png');
}
});
});
//-->
</script>
<body>
<video id="camera" autoplay></video><br>
<img id="img">
<div style="display:none"><canvas id="canvas"></canvas></div>
</body>
</html>
IE11でhttpsアクセスが遅い(Https access is slow in IE11)
事象(Event)
IE11でWEB通信が遅いっていう事象が発生。
通信パケットを解析すると、ブラウザからのアクセスの初回だけ10秒くらいかかっていた。
IE11 caused an event that WEB communication is delayed.
Analysis of the communication packet took about 10 seconds only for the initial access from the browser.
原因(Cause)
IE11のデフォルト設定では、どうやら発行証明書の取り消しを確認するようになっていて、
インターネットに繋がっていないLAN環境での通信では、発行元に問い合わせ通信がタイムアウトする間遅延するようだ。
これはアクセス先のドメインが変わらなければ、初回1回のみ発生する。
Apparently the default setting of IE 11 is to confirm the cancellation of issue certificate,
Communication in the LAN environment not connected to the Internet seems to be delayed while the inquiry communication to the issuer times out.
This occurs only once in the first time unless the domain of the access destination changes.
対応(Troubleshooting)
IEのオプション「Check for publisher’s certificate revocation」(発行元証明書の取り消しを確認する)の
選択を外す
Go to IE Options, advanced tab then locate security category and uncheck “Check for publisher’s certificate revocation” and “Check for server certificate revocation”.

VirtualBoxでWindows上で別OSを稼働させる
VirtualBoxの導入方法について
VirtualBoxを利用する
Windowsマシンしかなく、他OS(LinuxやMac OSなど)を試しに使ってみたいという時ってありますよね。
そういう時は仮想化技術を使ってWindowsマシン上で動く仮想マシンを作りましょう。
今回はVirtualBoxを使います。
ダウンロード
VirtualBoxのサイトにアクセスし、「Downloads」画面からダウンロードします。
VirtualBox 5.1.8 for Windows hosts x86/amd64 を今回は選択しました。

インストールしてみる
ダウンロードしたexeファイルを実行し、インストールします。
インストール後に起動すると、VirtualBoxが使えるようになります。
C言語でGarbage Collectorを使う
Boehm GCの紹介
C/C++では、mallocを使ったらfreeし、newしたら忘れずにdeleteしなければならない。
ガベージコレクタを使うと、メモリを解放する手間を省いてくれる。
C言語で使えるメジャーなガベージコレクタは、昔からBoehm GCが有名。
Boehm GCはJava等と同じマークスイープ方式で、循環参照も開放してくれる。
現在は、bdwgc (Boehm-Demers-Weiser Garbage Collector)として、GitHub上に最新のソースがある。
https://github.com/ivmai/bdwgc/
VisualStudioでビルドする方法
せっかくなので、最新のソースを取得しておきたい。
現在(2016-11-10)の最新版は7.7.0。
$ git clone git://github.com/ivmai/bdwgc.git $ cd bdwgc $ git clone git://github.com/ivmai/libatomic_ops.git
ビルドツールにはconfigureも使えるが、cmakeが便利。
C++で使う場合は、以下のおまじないをしておくとよい。
$ cmake -D enable_cplusplus=ON

gc.slnというソリューションファイルができるので、ビルドする。
32bitと64bitを間違えた場合は、cmakeからやり直す。

gcmt-dll.dllとgcmt-dll.libができれば完成。
使ってみる
まず、プロジェクトの設定を行う。
- includeパスに、bdwgc/include のパスを通す。
- libパスに、gcmt-dll.libの場所を追加する。
- 依存するライブラリに、gcmt-dll.libを追加する。
- gcmt-dll.dllをコピーする。
続いて、Cでサンプルプログラムを書いてみる。
#include <windows.h>
#include <gc.h>
int main()
{
for (i = 0; i < 1000000; i++) {
char *p = GC_malloc(1000000);
Sleep(1);
}
return 0;
}
動かしてみると、メモリ使用量が増えないことが分かる。
続いて、C++でサンプルプログラムを書いてみる。
#include <windows.h>
#include <gc_cpp.h>
int main()
{
for (i = 0; i < 1000000; i++) {
char *p = new(GC) char[1000000];
Sleep(1);
}
return 0;
}
クラスの場合、class gcを継承することで、ガベージコレクト対象となる。
#include <stdio.h>
#include <gc_cpp.h>
int Hoge_ctor;
int Hoge_dtor;
class Hoge : public gc
{
public:
Hoge() {
Hoge_ctor++;
}
~Hoge() {
Hoge_dtor++;
}
};
int main()
{
for (int i = 0; i < 1000000; i++) {
Hoge *h = new Hoge();
}
printf("Hoge ctor: %d\n", Hoge_ctor);
printf("Hoge dtor: %d\n", Hoge_dtor);
return 0;
}
実行結果...
Hoge ctor: 1000000 Hoge dtor: 0
メモリは解放されているが、デストラクタが動いていない。
デストラクタを起動して欲しい場合は、gc_cleanupを継承するとよい。
#include <stdio.h>
#include <gc_cpp.h>
int Hoge_ctor;
int Hoge_dtor;
class Hoge : public gc_cleanup
{
public:
Hoge() {
Hoge_ctor++;
}
~Hoge() {
Hoge_dtor++;
}
};
int main()
{
for (int i = 0; i < 1000000; i++) {
Hoge *h = new Hoge();
}
printf("Hoge ctor: %d\n", Hoge_ctor);
printf("Hoge dtor: %d\n", Hoge_dtor);
return 0;
}
実行結果...
Hoge ctor: 1000000 Hoge dtor: 999420
gc起動の閾値を超えない限り回収されないので、デストラクタが動く保証はない。
実行されるかどうか分からないので、使いどころはあまりないのかもしれない。
注意すること
Boehm GCの動作原理を知っておかないと、思わぬところで回収済みの領域にアクセスしてしまうことがある。
Boehm GCがマークスイープで探索する範囲は、以下の2つである。
- スタックにあるポインタをrootとして、
- GC_mallocやnew(GC)で確保した領域、gcやgc_cleanupを継承したクラスにあるポインタを辿っていく

上の図でいうと、①と②は回収されないが、③はアクセス可能にも関わらず、回収されてしまう。
普通のmallocと混ぜて使わないほうがよい。
SQLServerのテーブルロック状態を取得するSQL
SQL Serverでデッドロックの調査で苦労したので調査に使ったSQLなどをまとめておく。
SQL Serverにおいては、ロックの有無を確認するだけならsys.dm_tran_locksシステムビューですぐに確認できる。
SELECT * FROM sys.dm_tran_locks
しかし、sys.dm_tran_locksだけでは、テーブルロックや行ロックなどの情報がまとめて提供され、ロックされている対象も
オブジェクトIDでの表記になるため非常にわかりにくいものになっています。
ですので、単純にSELECTするのではなく、IDからオブジェクト名を取得したり、オブジェクトの種類によって
別のシステムビューから情報を取得する必要があります。
手を加えたSQLが以下のようになります。
SELECT
resource_type AS type --オブジェクトの種類
,resource_associated_entity_id as entity_id --エンティティID
,( CASE WHEN resource_type = 'OBJECT' THEN
OBJECT_NAME( resource_associated_entity_id )
ELSE
( SELECT
OBJECT_NAME( OBJECT_ID )
FROM
sys.partitions
WHERE
hobt_id=resource_associated_entity_id )
END)
AS object_name
,request_mode --ロックの種類
,request_type --要求の種類
,request_status --状態
,request_session_id AS Session_id --セッションID
,(SELECT hostname
FROM sys.sysprocesses
WHERE spid = request_session_id) AS ProcessName
FROM
sys.dm_tran_locks
WHERE
resource_type <> 'DATABASE'
ORDER BY
request_session_id
実行結果は以下のようになります。
他に必要な項目がある場合、SELECT文へ項目の追加を行ってください。

主なロックステータスの種類
主なロックステータスの種類として以下のものがあります。
| S | 共有ロック | 他のトランザクションからの読込は可能。更新は不可となる。 |
| X | 排他ロック |
他のトランザクションからの読込・更新が共に不可となる。 INSERT、UPDATE、DELETEを実行するとこのロックになる。 |
| U | 更新ロック |
他のトランザクションからの読込は可能。更新は不可となる。 SELECTで WITH( UPDLOCK )を指定するとこのロックになる。 |
使用したシステムビューについて
・sys.dm_tran_locks・・・ロック情報を参照できるビュー。
ビュー詳細情報<Micrsoft MSDN>
・sys.partitions・・・テーブルまたはインデックスで使用されているパーティション情報を参照できるビュー。
ビュー詳細情報<Micrsoft MSDN>
・sys.sysprocesses・・・接続されているProcess情報を参照できるビュー。
ビュー詳細情報<Micrsoft MSDN>
ロックエラーをわざと発生させる方法
異常系のテストを行いたい場合などで、テーブルのロックをかけたい場合の手順。
・以下のロック用SQLを実行(sleepしている間ロックされている)
BEGIN TRAN
SELECT * FROM TABLEA WITH(TABLOCKX)
WAITFOR DELAY '00:01:00' --任意の時間スリープ。
COMMIT TRAN
※SSMS(SQL Server Management Studio)などでデバッグ実行できるなら、
COMMIT TRANまでにブレークしておけばよい。
・エラーを起こすSQL
SET LOCK_TIMEOUT 0 SELECT * FROM TABLEA
⇒ロックタイムアウトの値を0にしているため、即時ロックエラーになる。
通信の暗号化をどうする?bigipのcipherを考える
暗号化通信を設定しようとするとcipher(暗号方式)について検討することになると思います。
これ、しっかり検討しておかないと、暗号方式の脆弱性を狙った攻撃を受けます。
IPA(情報処理推進機構)やセキュリティ会社もしょっちゅう、「この暗号方式について脆弱性が発見されました」というニュースを出していますね。
今回はWEB通信の証明書のやりとりで使われるcipherについてまとめたので紹介します。
まずは、簡単にcipherについて
WEB通信の暗号化はapacheなどのWEBサーバーで設定します。
暗号方式は、ミドルウェアのサポートしている範囲から有効にするcipherを定義します。
クライアントとなる端末のブラウザが要求するcipherがサーバー側で有効ならば暗号化通信が成立する仕組みになります。
流れ
1.Client(ブラウザ)→ClinetHelloパケット(このcipherかこのcipherかこの・・・で暗号できますかー?)→Server
2.Server→ServerHelloパケット(じゃあ、このcipherで暗号化しよう)→Clinet
てな流れでClinetとServerはご挨拶(SSLハンドシェーク)をして、cipherを決めます。
BigIP(F5社製ロードバランサ)で設定するcipherについて
私はBIGIP(F5社)のロードバランサを扱うことが多いので、今回はBIGIPに特化して紹介します。
cipher(暗号化方式)って何がサポートされていて影響受けるクライアントは何ってところを毎回調べています。
cipherを細かく設定するとClinetとなるブラウザが利用できなくなったりするので、きちんと調べる必要があります。
逆に大雑把に設定すると脆弱性をついた不正アクセスやアタックの原因になります。
1回調べたら資料にしておけば、楽なのでまとめました。
※BIGIPv12以降は対応していないのです。
※Cipherセット名はGlobalな名称で、BIGIPの定義では専用の定義名を使います。
添付の資料ではBIGIPでの定義名は記載していません。
・・・別途つくろうかな。。。
VirtualBoxでBIG-IPを稼働させる
はじめに
BIGIP(F5社)というロードバランサを検証するために仮想環境に導入してみようと思ったのですが、
VirtualBox(オラクル社)の仮想環境はサポートしていないようだ。
でもなんとか動かしたい!
やってやろうじゃないかと取り組むこと半日、やっと稼働させることができました。
せっかくなので紹介します。
※VirtualBoxでの稼働をBIGIPはサポートしていませんので参考になさる場合は自己責任でお願いします。
準備
- Windowsマシン(私はLenovo T440p & Windows7を使いました)
- VirtualBox(私はversion 5.1.10を使いました)
- 7-Zip(OVAファイルをカスタマイズするために使います)
- BIGIP VEトライアル(とりあえず、v11.3.0トライアル)
https://downloads.f5.com/esd/productlines.jsp※F5社のアカウントが必要です。
もちろんVirtualBox用のOVAは無いため、今回はBIGIP-11.3.0.39.0-scsi.ova(VMWare用)を使いました。
手順
①IntelチップのIntel Virtualization Technologyを有効化します。
- PCのBIOS画面でIntel Virtualization TechnologyをEnableにしてください。
デフォルトはDisableになっているはずです。
※この設定をしないとVirtualBoxで64bitOSを稼働できません。
②OVAファイルを編集しておきます。
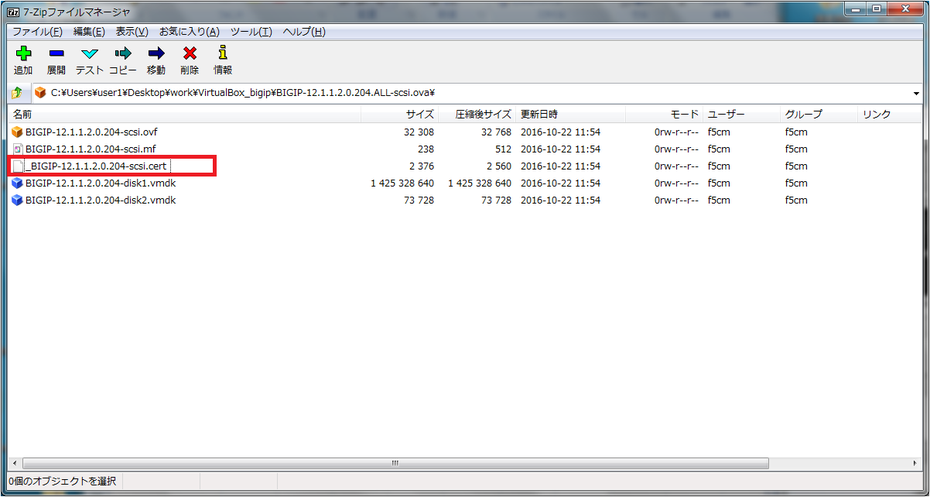
- OVAファイル内のcertファイル(証明書)の名前を編集します。
※私は頭にアンダースコアを付けただけで済ませました。
※この対応をしておかないと、OVAファイルをVirtualBoxにインポートするときに証明書エラーが発生します。 - OVAファイルを保存します。
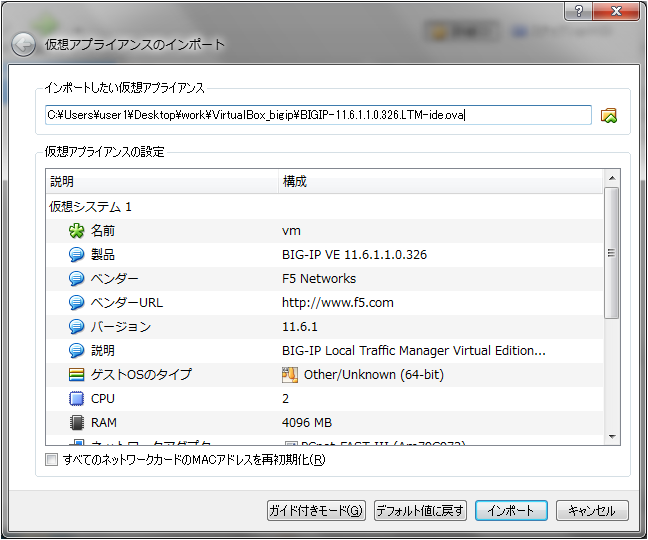
③VirtualBoxにOVAファイルをインポートします。

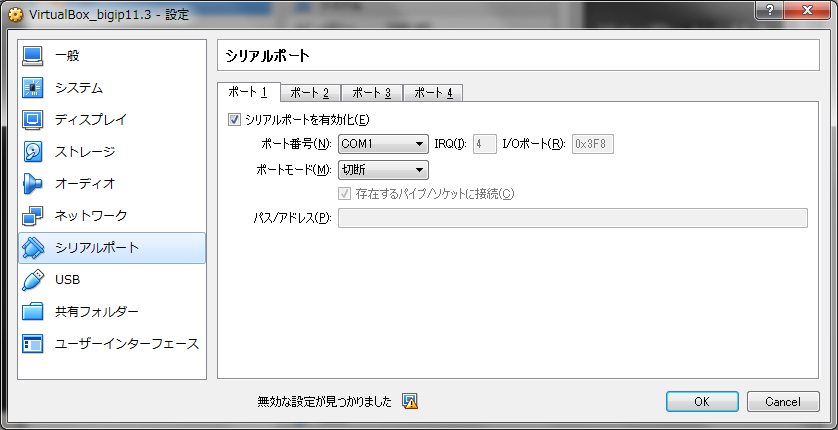
④インポートが成功したら、設定>シリアルポートでポート1の「シリアルポートを有効化」にチェックを入れます。
※この設定をしておかないと、起動時に「GRUB Loading stage2..」と表示された後にフリーズします。
⑤さっそくBIGIPを起動してみましょう。
- 起動すると、CUIの画面が開きます。
- 「localhost emerg logger: Re-starting chmand」というエラーメッセージが出力しつづけます。
- rootユーザー、パスワード「default」でログインします。
- 上記のエラーメッセージを止めたいので「bigstart stop chmand」とコマンドを実行します。
- 「/PLATFORM」というファイルをVIエディタで開き、以下のように編集します。
platformの値とhostの値を「Z99」にします。
familyの値を「0x80000000」にします。systypeの値を「0x71」を追記します。
※この値にしないと、後のトライアルライセンスの適用に失敗します。
ネット上にはZ100にする記載をよくみかけますが、私はこの設定にしなければ成功しませんでした。 - 「/tmp/platform_info」というファイルを消します。
- リブートします。(rebootコマンドを実行します。)
※この対応をすることで、chmandのエラーが出なくなります。
⑥管理コンソールへアクセスします。
- CUIの画面で「ifconfig -a | more」を実行し、IPアドレスを確認します。
- ブラウザを起動し、「https://[確認したIPアドレス]/」にアクセスします。
- 管理コンソールのログイン画面が表示されれば成功です。
※管理コンソールのログインユーザーはadmin、パスワードはadminです。
※TeraTermなどCUIコンソールではsshで、上記で確認したIPアドレスに接続してください。
CUIでのログインユーザーはroot、パスワードはdefaultです。

⑦トライアルライセンス(90日)を取得します。
-
https://www.f5.com/trial/secure/big-ip-ltm-virtual-edition.phpにアクセス
※F5社のアカウントが必要です。 - 「Generate Registration Key」ボタンをクリックします。
- アカウント情報で登録してあるメールアドレスにRegistration Keyが届きます。
※30分くらい後に届きます。

⑧ライセンスを適用します。
- CUIのコンソールで以下のコマンドを実行します。
tmsh install sys license registration-key [メールで受け取ったRegistration-Key] verbose - 成功すると、以下図のようにNO LICENSEステータスからACTIVEステータスに変わります。

⑨あとは、Setup Utilityで初期設定をして、環境を整えます。
参考
VirtualBoxでBIGIPを稼働させる その2
VirtualBoxでBIGIP VMを稼働させてみる
前回の記事では、BIGIP(F5社)というロードバランサを検証するために仮想環境にフリーライセンスの11.3.0トライアル版を導入してみました。
しかし、トライアル版はv11.3.0で最新バージョンではありません。
最近のバージョンの設定値とかコマンドとかを確認するため、お試ししてみたいなぁと思ってしまった私は、
むりやりVirtualBoxにBIGIP VMのv12.1.1を導入しようと試みました。
※VirtualBoxでの稼働をBIGIPはサポートしていませんので参考になさる場合は自己責任でお願いします。
準備
- Windowsマシン(私はLenovo T440p & Windows7を使いました)
- VirtualBox(私はversion 5.1.10を使いました)
- 7-Zip(OVAファイルをカスタマイズするために使います)
- BIGIP VE v12.1.1 HF2
https://downloads.f5.com/esd/productlines.jsp※F5社のアカウントが必要です。
もちろんVirtualBox用のOVAは無いため、今回はBIGIP-12.1.1.2.0.204.LTM-scsi.ova(VMWare用)を使いました。
手順
STEP1:端末の準備
IntelチップのIntel Virtualization Technologyを有効化します。
- PCのBIOS画面でIntel Virtualization TechnologyをEnableにしてください。
デフォルトはDisableになっているはずです。
※この設定をしないとVirtualBoxで64bitOSを稼働できません。

STEP2:VirtualBoxに仮想マシン作成
- VirtualBoxを起動します。
- 新規のボタンをクリックします。
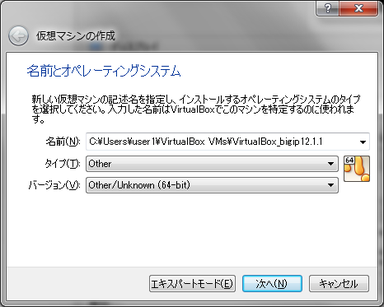
- 仮想マシンの種類を設定します。
名前は保存フォルダを指定します。
タイプはOtherを選びます。
バージョンはOther/Unknown(64-bit)を選びます。
※64bitが選択できない場合はSTEP1からやり直してください。
- メモリサイズは2048MBにしてください。
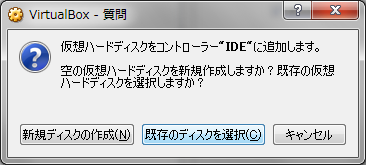
- ハードディスクは「仮想ハードディスクを追加しない」を選択します。

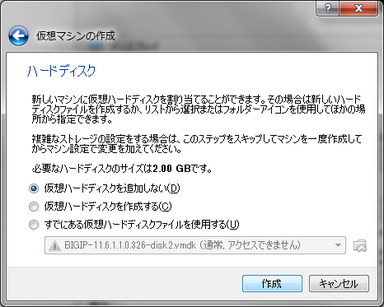

STEP3:仮想DISKをOVAファイルからコピーする
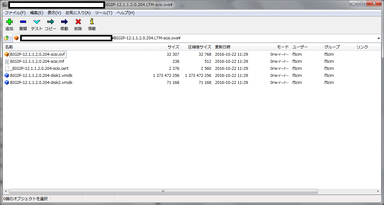
- 7-ZipでOVAファイルを開きます。
- vmdkファイル(BIGIP-12.1.1.2.0.204-disk1.vmdk)をSTEP2で指定した保存フォルダにコピーします。

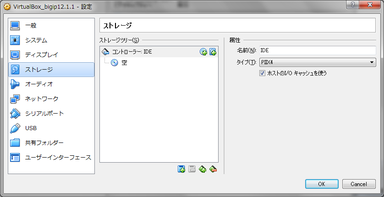
STEP4:仮想マシンを設定する
- VirtualBoxで作成した仮想マシンを選び、設定画面を開きます。
- ストレージを選び、仮想ハードディスクを追加します。
※STEP3で配置したvmdkファイルを追加します。
※空のDISKを除去します。
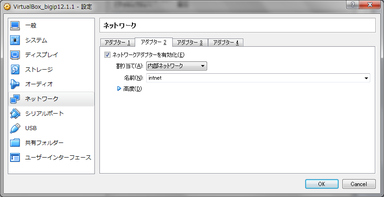
- ネットワークの設定画面を開き、アダプター1タブで、「ネットワークアダプターを有効化」にチェックします。
割り当ては、ブリッジアダプターを選択します。
- アダプター2のタブで「ネットワークアダプターを有効化」にチェックします。
割り当ては、内部ネットワークを選択します。
- アダプター3のタブで「ネットワークアダプターを有効化」にチェックします。
割り当てはブリッジアダプターを選択します。
- アダプター4のタブで「ネットワークアダプターを有効化」にチェックします。
割り当てはブリッジアダプターを選択します。
- シリアルポートを選択し、ポート1のタブで、「シリアルポートを有効化」にチェックします。
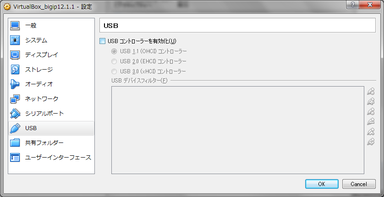
- USBを選択し、「USBコントローラーを有効化」のチェックを外します。





STEP5:仮想マシンを起動する
以上で準備は整いました。
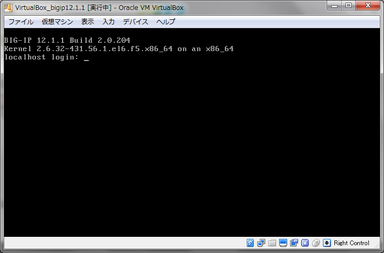
あとは、VirtualBoxから仮想マシンを起動してみてください。
上手くログインできる状態までいけば完了です。
※ユーザーはroot、パスワードはdefaultでログインできます。
※この後ライセンス適用を行えば、使うことが可能になると思います。私はコマンドと設定項目を知りたいだけなので、ここまでで作業をやめました。
BIGIPを証明書の認証局にする(1/3)
はじめに
BIGIPをLAN内のロードバランサとして使う時、https通信の暗号化につかう証明書は自己署名にしたいなーって思うことありませんか?
そんな時、BIGIPのサーバー証明書は管理コンソール(WEB画面)で自己署名の証明書を作成できるから簡単ですね。
でも。。クライアント証明書も使いたいぞってなると、どうやって作ろうかって考えてしまいますね。
認証局をつくらなければとなり、どこかOpenSSLの使えるサーバーを探して。。。って流れになります。
まてよ、BIGIPもOpenSSLがデフォルトで使えるじゃないか!じゃあ、やってみようと思って設定してみました。
環境
- BIGIP LTM v11.5.3 ~ v12.1.1
- BIGIP LTM VE v11.3.0
認証局をつくる
1.BIGIPに管理ユーザーでログインする
2.ワークディレクトリを作成する
BIGIPには/sharedというワーク用ファイルシステムがあります。
/sharedに認証局用のディレクトリを作成します。
# mkdir /shared/CA
# mkdir /shared/CA/certs /shared/CA/crl /shared/CA/newcerts /shared/CA/private
# echo "01" > /shared/CA/serial
# touch /shared/CA/index.txt
3.openssl.cnfを用意する
BIGIPで利用されているopenssl.cnfがあるのでコピーして使う方が手っ取り早いということで、コピーします。
# cp /etc/pki/tls/openssl.cnf /shared/CA/openssl.cnf
コピーできたことを確認する
# ls -l /shared/CA/openssl.cnf
コピーしたopenssl.cnfを編集する
dir = ./demoCA → dir = /shared/CA
4.認証局(CA)を作成
# openssl req -config /shared/CA/openssl.cnf -new -x509 -keyout /shared/CA/private/cakey.key -out /shared/CA/cacert.crt -days 5475 -sha256 -newkey rsa:2048
Generating a 2048 bit RSA private key
........................................+++
..........+++
writing new private key to '/shared/CA/private/cakey.key'
Enter PEM pass phrase: …①
Verifying - Enter PEM pass phrase: …②
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:JP …③
State or Province Name (full name) [Some-State]:Kyoto …④
Locality Name (eg, city) []:Nakagyo-ku …⑤
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Excellence Co., Ltd …⑥
Organizational Unit Name (eg, section) []:System Innovation …⑦
Common Name (e.g. server FQDN or YOUR name) []:1excellence.com …⑧
Email Address []: …⑨
①②はパスフレーズを入力します。①と②は同じ値を入力します。
③は国名を2文字のレターコードで入力します。日本はJP。
④は国名/州名なのですが、日本なので都道府県でいいかな。
⑤は都市名なので、市町村名や区名等。
⑥は組織名なので、会社名とか部署名等。
⑦は組織の単位名なので、部署名、チーム名等。
⑧はFQDN
⑨はメールアドレス(入力しなくてもいい)
5.認証局の完成
以下が作成されていれば完成です。
/shared/CA/cacert.crt …認証局の証明書(root証明書)
/shared/CA/private/cakey.key …認証局のキーファイル
6.署名する
BIGIPを証明書の認証局にする(2/3)
ここまでの流れ
前回までは認証局を作成しました。
せっかく認証局を作ったので自己署名のサーバー証明書を作ってみます。
環境
- BIGIP LTM v11.5.3 ~ v12.1.1
- BIGIP LTM VE v11.3.0
認証局をつくる
1.BIGIPに認証局を作成する
前回の手順を参照してください。
2.サーバー証明書のキーファイルを作成する
# openssl genrsa -des3 -out sample_server.key 2048
Generating RSA private key, 2048 bit long modulus
.................................................+++
.+++
e is 65537 (0x10001)
Enter pass phrase for /shared/CA/sample_server.key: …①
Verifying - Enter pass phrase for /shared/CA/sample_server.key: …②
①②はパスフレーズを入力します。①と②は同じ値を入力します。
/shared/CA/sample_server.keyが作成されたことを確認します。
3.パスフレーズを解除する
パスフレーズは設定したままでもいいのですが、私は忘れてしまうので覚えているうちに解除しておきます。
# openssl rsa -in /shared/CA/sample_server.key -out /shared/CA/sample_server_np.key
Enter pass phrase for /shared/CA/sample_server.key: …①
writing RSA key
①はsample_server.keyを作成時に入力したパスフレーズを入力します。
以下が作成されます。
/shared/CA/sample_server.key …パスフレーズ付きキーファイル
/shared/CA/sample_server_np.key …パスフレーズを解除したキーファイル
4.署名要求書を作成する
# openssl req -new -days 5475 -sha256 -key /shared/CA/sample_server_np.key -out /shared/CA/sample_server.csr
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:JP …①
State or Province Name (full name) [Some-State]:Kyoto …②
Locality Name (eg, city) []:Nakagyo-ku …③
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Excellence Co., Ltd …④
Organizational Unit Name (eg, section) []:System Innovation …⑤
Common Name (e.g. server FQDN or YOUR name) []:1excellence.com …⑥
Email Address []: …⑦
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []: …⑧
An optional company name []: …⑨
①は国名を2文字のレターコードで入力します。日本はJP。
②は国名/州名なのですが、日本なので都道府県でいいかな。
③は都市名なので、市町村名や区名等。
④は組織名なので、会社名とか部署名等。
⑤は組織の単位名なので、部署名、チーム名等。
⑥はFQDN
⑦はメールアドレス(入力しなくてもいい)
⑧はチャレンジパスワード(入力しなくてもいい)
⑨は会社名(入力しなくてもいい)
以下が作成されます。
/shared/CA/sample_server.csr
5.サーバー証明書用の認証局の設定をする
# cp /shared/CA/openssl.cnf /shared/CA/openssl-server.cnf
コピーしたopenssl-server.cnfの以下を編集する
default_days = 365 ← サーバー証明書の有効期限を書き換える(変更しない場合は1年)
#nsCertType = server ←コメントを外す
6.認証局で署名する
# openssl ca -md sha256 -days 365 -config /shared/CA/openssl-server.cnf \
-in /shared/CA/sample_server.csr \
-keyfile /shared/CA/private/cakey.key \
-cert /shared/CA/cacert.crt \
-out /shared/CA/sample_server.crt
Using configuration from /shared/CA/openssl-server.cnf
Enter pass phrase for /shared/CA/private/cakey.key: …「認証局のパスフレーズ」を入力
Check that the request matches the signature
Signature ok
Certificate Details:
Serial Number: 1 (0x1)
Validity
Not Before: Dec 6 15:31:49 2016 GMT
Not After : Dec 6 15:31:49 2017 GMT
Subject:
countryName = JP
stateOrProvinceName = Kyoto
organizationName =
Excellence Co., Ltd
organizationalUnitName = System Innovation
commonName = 1excellence.com
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Cert Type:
SSL Server
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX
X509v3 Authority Key Identifier:
keyid:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX
Certificate is to be certified until Dec 6 15:31:49 2017 GMT (365 days)
Sign the certificate? [y/n]:y …「y」を入力
1 out of 1 certificate requests certified, commit? [y/n]y …「y」を入力
Write out database with 1 new entries
Data Base Updated
7.署名されたサーバー証明書が作成されたことを確認する
# ls -l /shared/CA/sample_server.crt
署名されたサーバー証明書が作成されていれば完了です。
付録:こんな時は
署名処理(6の手順)で再度実行すると、以下のエラーになります。
failed to update database
TXT_DB error number 2
この時は、/shared/CA/index.txtをリネームして、touch /shared/CA/index.txtで作り直してから試してみてください。
BIGIPを証明書の認証局にする(3/3)
ここまでの流れ
前回までは認証局を作成して、サーバー証明書の自己署名をやってみました。
ここで、やっと当初の目的であるクライアント証明書も自己署名してみました。
環境
- BIGIP LTM v11.5.3 ~ v12.1.1
- BIGIP LTM VE v11.3.0
認証局をつくる
1.BIGIPに認証局を作成する
認証局の作成手順を参照してください。
2.クライアント証明書のキーファイルを作成する
# openssl genrsa -des3 -out sample_client.key 2048
Generating RSA private key, 2048 bit long modulus
...............+++
.+++
e is 65537 (0x10001)
Enter pass phrase for sample_client.key: …①
Verifying - Enter pass phrase for sample_client.key: …②
①②はパスフレーズを入力します。①と②は同じ値を入力します。
/shared/CA/sample_server.keyが作成されたことを確認します。
3.パスフレーズを解除する
パスフレーズは設定したままでもいいのですが、私は忘れてしまうので覚えているうちに解除しておきます。
# openssl rsa -in /shared/CA/sample_client.key -out /shared/CA/sample_client_np.key
Enter pass phrase for /shared/CA/sample_client.key: …①
writing RSA key
①はsample_client.keyを作成時に入力したパスフレーズを入力します。
以下が作成されます。
/shared/CA/sample_clientkey …パスフレーズ付きキーファイル
/shared/CA/sample_client_np.key …パスフレーズを解除したキーファイル
4.署名要求書を作成する
# openssl req -new -days 5475 -sha256 -key /shared/CA/sample_client_np.key -out /shared/CA/sample_client.csr
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:JP …①
State or Province Name (full name) [Some-State]:Kyoto …②
Locality Name (eg, city) []:Nakagyo-ku …③
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Excellence Co., Ltd …④
Organizational Unit Name (eg, section) []:System Innovation …⑤
Common Name (e.g. server FQDN or YOUR name) []:1excellence.com …⑥
Email Address []: …⑦
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []: …⑧
An optional company name []: …⑨
①は国名を2文字のレターコードで入力します。日本はJP。
②は国名/州名なのですが、日本なので都道府県でいいかな。
③は都市名なので、市町村名や区名等。
④は組織名なので、会社名とか部署名等。
⑤は組織の単位名なので、部署名、チーム名等。
⑥はFQDN
⑦はメールアドレス(入力しなくてもいい)
⑧はチャレンジパスワード(入力しなくてもいい)
⑨は会社名(入力しなくてもいい)
以下が作成されます。
/shared/CA/sample_server.csr
5.クライアント証明書用の認証局の設定をする
# cp /shared/CA/openssl.cnf /shared/CA/openssl-client.cnf
コピーしたopenssl-server.cnfの以下を編集する
default_days = 365 ← サーバー証明書の有効期限を書き換える(変更しない場合は1年)
#nsCertType = client, email ←コメントを外す
6.認証局で署名する
# openssl ca -md sha256 -days 365 -config /shared/CA/openssl-client.cnf \
-in /shared/CA/sample_client.csr \
-keyfile /shared/CA/private/cakey.key \
-cert /shared/CA/cacert.crt \
-out /shared/CA/sample_client.crt
Using configuration from /shared/CA/openssl-client.cnf
Enter pass phrase for /shared/CA/private/cakey.key: …「認証局のパスフレーズ」を入力
Check that the request matches the signature
Signature ok
Certificate Details:
Serial Number: 1 (0x1)
Validity
Not Before: Dec 6 15:31:49 2016 GMT
Not After : Dec 6 15:31:49 2017 GMT
Subject:
countryName = JP
stateOrProvinceName = Kyoto
organizationName =
Excellence Co., Ltd
organizationalUnitName = System Innovation
commonName = 1excellence.com
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Cert Type:
SSL Server
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX
X509v3 Authority Key Identifier:
keyid:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX
Certificate is to be certified until Dec 6 15:31:49 2017 GMT (365 days)
Sign the certificate? [y/n]:y …「y」を入力
1 out of 1 certificate requests certified, commit? [y/n]y …「y」を入力
Write out database with 1 new entries
Data Base Updated
7.署名されたクライアント証明書が作成されたことを確認する
# ls -l /shared/CA/sample_client.crt
署名されたクライアント証明書が作成されていれば完了です。
付録:こんな時は
署名処理(6の手順)で再度実行すると、以下のエラーになります。
failed to update database
TXT_DB error number 2
この時は、/shared/CA/index.txtをリネームして、touch /shared/CA/index.txtで作り直してから試してみてください。
tomcatのmanagerにlocalhost以外からつながらない
状況
Linux(今回はRedhat7.4)をインストール時にtomcat8を同時インストールさせてみたのだが、
manager(http://IP:8080)がLocal以外からアクセスできないという事象が発生した。
Linuxサーバには外部からsshでログインできる状態、pingも可能であった。
対応
原因はLinux-Firewall。
1.firewallが稼働しているかも。。
[root@localhost]# firewall-cmd --state
running
2. 稼働しているなら、アクティブなゾーンは何かな?
[root@localhost]# firewall-cmd --get-active-zones
public
interfaces: enp0s3
3. 何が許可されているかな?
[root@localhost]# firewall-cmd --zone=public --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: dhcpv6-client ssh
ports:
protocols:
masquerade: no
forward-ports:
sourceports:
icmp-blocks:
rich rules:
4. 8080/tcpが許可されていないから、許可しちゃおう。
※ラインタイムで変更する場合
[root@localhost]# firewall-cmd --zone=public --add-port=8080/tcp
success
[root@localhost]# firewall-cmd --zone=public --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: dhcpv6-client ssh
ports: 8080/tcp ・・・これが追加された
protocols:
masquerade: no
forward-ports:
sourceports:
icmp-blocks:
rich rules:
※永久保存する場合
[root@localhost]# firewall-cmd --zone=public --add-port=8080/tcp --permanent
success
[root@localhost]# firewall-cmd --reload
success
[root@localhost]# firewall-cmd --zone=public --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: dhcpv6-client ssh
ports: 8080/tcp ・・・これが追加された
protocols:
masquerade: no
forward-ports:
sourceports:
icmp-blocks:
rich rules:
5. これで対応完了。
Net-SNMP で受けたTrapをMariaDBに記録する
Issue
RedhatでSNMPTrapの受信サーバを作ろうとしました。
Redhat7ではMySQLが標準DBから外され、互換性のあるMariaDBに変わっています。
Net-SNMPの標準機能であるMySQL出力機能をMariaDBに置き換えて利用できるかなと試してみました。
Environment
- Redhat EL 7.3
[root@localhost ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.3 (Maipo) - MariaDB
[root@localhost ~]# mysql -V
mysql Ver 15.1 Distrib 5.5.52-MariaDB, for Linux (x86_64) using readline 5.1 - Net-SNMP
[root@localhost ~]# rpm -q net-snmp
net-snmp-5.7.2-24.el7_2.1.x86_64
Resolution
1.Redhatのインストール
インストール、インストール後の初期設定については割愛します。
※インストール時に次のようにパケージを選択しておけば、後から追加パケージを導入しなくてもよいですね。

2.snmpd.confを設定
/etc/snmp/snmpd.confを以下のように編集します。
# com2secディレクティブ:コミュニティ名とリクエスト元のペアにセキュリティ名を付ける
# com2sec "セキュリティ名" "リクエスト元" "コミュニティ名"
com2sec localhost localhost public
com2sec localnet 192.168.1.0/24 public
# groupディレクティブ:セキュリティ名とセキュリティモデルのペアにグループ名を付ける
# group "グループ名" "セキュリティモデル" "セキュリティ名"
group MyROGroup v1 localnet
group MyROGroup v2c localnet
group MyROGroup v1 localhost
group MyROGroup v2c localhost
# viewディレクティブ:MIBツリーの範囲を定義して名前を付ける
# view "ビュー名" "includedまたはexclude" ツリーの基点 マスク
view all included .1 0
# accessディレクティブ:グループ名とビュー名を紐付ける
access MyROGroup "" any noauth exact all none none
syscontact [email protected]
syslocation Kyoto
3.snmptrapd.confを設定
/etc/snmp/snmptrapd.confを以下のように設定します。
snmpTrapdAddr udp:162,tcp:162
doNotRetainNotificationLogs yes
doNotLogTraps no
doNotFork no
pidFile /var/run/snmptrapd.pid
# authCommunity TYPES COMMUNITY [SOURCE [OID | -v VIEW ]]
authCommunity log public
disableAuthorization no
sqlMaxQueue 5
sqlSaveInterval 0
4.trapを発行、受信できるかテスト
- systemctlでsnmpdとsnmptrapdを起動します。
# systemctl start snmpd
# systemctl start snmptrapd
- テストトラップを発行してみます。
# snmptrap -v 2c -c public localhost '' .1.3.6.1.4.1.8072.99999 .1.3.6.1.4.1.8072.99999.1 s "v2c send test" - システムログに出力されたことを確認します。
# tail /var/log/messages
Dec 12 14:58:00 localhost snmptrapd[2643]: 2016-12-12 14:57:59 <UNKNOWN> [UDP: [192.168.1.X]:50131->[192.168.1.X]:162]:#012.1.3.6.1.2.1.1.3.0 = Timeticks: (49834) 0:08:18.34#011.1.3.6.1.6.3.1.1.4.1.0 = OID: .1.3.6.1.4.1.8072.99999#011.1.3.6.1.4.1.8072.99999.1 = STRING: "v2c send test"
※もし、上手く受信できない時はfirewallを確認ください。
# firewall-cmd --get-active-zones …アクティブゾーンの確認
# firewall-cmd --zone=[アクティブゾーン名] --list-all …定義情報確認
必要に応じて、162/udp、161/udpで通信ができるようにしてください。
5.MariaDBにtrap受信用テーブルを作成
- MariaDBを起動する
# systemctl start mariadb
- 初期設定
# mysql_secure_installation
- MariaDBにログインし、データベースとアカウントを作成
# mysql -u root -p
MariaDB>CREATEDATABASEnet_snmp;Query OK, 1 row affected (0.04 sec)MariaDB>CREATEUSERtrapperIDENTIFIEDBY'trapass';Query OK, 0rowsaffected (0.08 sec)MariaDB>GRANTALLONnet_snmp.*TOtrapper;Query OK, 0rowsaffected (0.03 sec)
MariaDB>selectHost,Db,User,Select_priv,Insert_priv,Update_priv,Delete_privfromdbwhereUser="trapper";+-----------+----------+---------+-------------+-------------+-------------+-------------+| Host | Db |User| Select_priv | Insert_priv | Update_priv | Delete_priv |+-----------+----------+---------+-------------+-------------+-------------+-------------+| localhost | net_snmp | trapper | Y | Y | Y | Y |+-----------+----------+---------+-------------+-------------+-------------+-------------+1 rowinset(0.02 sec)MariaDB> \qBye
- 作成したアカウントで再ログイン
# mysql -u trapper -p net_snmp
- Trap受信用テーブル作成
MariaDB> sourceschema-snmptrapd.sqlDatabasechangedQuery OK, 0rowsaffected, 1 warning (0.02 sec)Query OK, 0rowsaffected (0.18 sec)Query OK, 0rowsaffected, 1 warning (0.00 sec)Query OK, 0rowsaffected (0.08 sec)MariaDB> show tables;+--------------------+| Tables_in_net_snmp |+--------------------+| notifications || varbinds |+--------------------+2rowsinset(0.00 sec)
※schema-snmptrapd.sqlがマシン上に存在しない場合
Net-SNMPの本家からソースファイルをダウンロードして、zipファイル内から取得します。
https://sourceforge.net/projects/net-snmp/files/net-snmp/5.5.2.1/net-snmp-5.5.2.1.zip
6.Net-SNMPからMariaDBへ接続する設定
/etc/my.cnfに追記
[snmptrapd]
user=trapper
password=trapass
host=localhost
/etc/snmp/snmptrapd.confのsqlMaxQueueとsqlSaveIntervalを修正
snmpTrapdAddr udp:162,tcp:162
doNotRetainNotificationLogs yes
doNotLogTraps no
doNotFork no
pidFile /var/run/snmptrapd.pid
# authCommunity TYPES COMMUNITY [SOURCE [OID | -v VIEW ]]
authCommunity log public
disableAuthorization no
sqlMaxQueue 140
sqlSaveInterval 9
MariaDBを再起動
# systemctl restart mariadb
snmptrapdを再起動
# systemctl restart snmptrapd
7.trapを発行してMariaDBに書きこむテスト
- trapを発行
# snmptrap -v 2c -c public localhost '' .1.3.6.1.4.1.8072.99999 .1.3.6.1.4.1.8072.99999.1 s "v2c send test" - MariaDBにログインし、テーブル内容を確認
# mysql -u trapper -p net_snmp
MariaDB [net_snmp]> SELECT trap_id,date_time,type,version,snmpTrapOID,transport,security_model from notifications;
+---------+---------------------+-------+---------+-------------------------+-----------------------------------------------+----------------+
| trap_id | date_time | type | version |
snmpTrapOID |
transport
| security_model |
+---------+---------------------+-------+---------+-------------------------+-----------------------------------------------+----------------+
| 1 | 2016-12-12 10:21:20 | trap2 | v2c | .1.3.6.1.4.1.8072.99999 | UDP:
[127.0.0.1]:60008->[127.0.0.1]:162 | snmpV2c |
---+-------------------------+-----------------------------------------------+----------------+
1 rows in set (0.00 sec)
MariaDB [net_snmp]> select * from varbinds;
+---------+---------------------------+-----------+-----------------------------------------------+
| trap_id | oid |
type |
value
|
+---------+---------------------------+-----------+-----------------------------------------------+
| 1 | .1.3.6.1.2.1.1.3.0 | timeticks | Timeticks: (344061)
0:57:20.61 |
| 1 | .1.3.6.1.6.3.1.1.4.1.0 | oid | OID:
.1.3.6.1.4.1.8072.99999 |
| 1 | .1.3.6.1.4.1.8072.99999.1 | octet | STRING: "v2c send
test" |
+---------+---------------------------+-----------+-----------------------------------------------+
3 rows in set (0.00 sec)
MariaDB [net_snmp]> \q
Bye
Troubleshoot
①SELinuxを停止する
以下で一時的にSELinuxを停止できます。
# setenforce 0
②/var/log/messagesなどのログファイルでエラーが出力されていないか確認
③サービスが稼働しているか確認
# systemctl status snmptrapd
# systemctl status mariadb
④firewallを確認し、mariadb、162/udpが解放されているか確認
# firewall-cmd --zone=[アクティブゾーン名] --list-all
Linuxでのサービスやデーモンの起動順
Issue
Linuxでサービスの起動停止はsystemctlコマンドを使います。
systemctl enable [サービス名] で自動起動を登録した時に、サービスUnit同士の依存関係に起因するエラーが発生することがあります。
この時、起動順序を制御する方法があります。
Resolution
1.サービスUnitの自動起動の順序を確認する
# systemctl list-dependencies

このコマンドを実行すると、自動起動に登録したサービスUnitの起動順が一覧化されます。
# systemd-analyze plot > unitstart.html

このコマンドを実行すると、実際にサービスUnitがどういう順で起動してどれくらい時間がかかったをHTMLファイルで出力できます。
# systemd-analyze plot > unitstart.html
# firefox unitstart.html
2.サービスUnit同士の依存関係を設定する
依存関係を設定するには、サービスの定義ファイルにパラメータを追加します。
サービスの定義ファイルは、/etc/systemd/system ディレクトリ内にあります。
たとえば、mariadbのサービスファイルは、
[root@testserver ~]# find /etc/systemd/system -name mariadb.service
/etc/systemd/system/multi-user.target.wants/mariadb.service
[root@testserver ~]#
serviceファイルには、 [Unit] というUNIT間の依存関係を設定するディレクティブがあります。
このディレクティブに設定を追加することで、起動時のUnit同士の依存関係を設定できます。
もし、serviceファイルが見つからない場合は、/usr/lib/systemd/systemにインストール時のデフォルト設定のserviceファイルがありますから、そちらを探します。
見つかったserviceファイルを/etc/systemd/systemに配置して設定します。
関係
分類
設定方法と解説
After
前後関係
先行起動するサービスを定義する
■ 「Aよりも前にBを起動する」の定義方法
A.service -------------------------------------------
[Unit]
After=B.service
---------------------------------------------------
”B.serviceより後に自分を起動してください”という設定
Before
前後関係
後続起動するサービスを定義。
■ 「Aの後にBを起動する」の定義方法
A.service -------------------------------------------
[Unit]
Before=B.service
---------------------------------------------------
”A.serviceより後にBserviceを起動してください”という設定
Wants
同時起動依存関係
強制力の無い依存関係。
Systemdはサービスの同時起動を試みるが、依存先の起動に失敗した場合であっても、依存元の起動は引き続き実施する。
■「 AはBに依存する」の定義方法
A.service -------------------------------------------
[Unit]
Wants=B.service
---------------------------------------------------
Requires
同時起動依存関係
強制力のある依存関係。
Systemdはサービスの同時起動を試み、依存先の起動に失敗した場合は、依存元は起動しない。
■「 AはBに依存する」の定義方法
A.service -------------------------------------------
[Unit]
Requires=B.service
---------------------------------------------------
Conflict
同時起動依存関係
競合する関係。
Systemdは関係が定義されたサービスと同時に起動しない。
■「AとBは競合する」の定義方法
A.service -------------------------------------------
[Unit]
Conflicts=B.service
---------------------------------------------------
Troubleshoot
実際に発生した自動起動時の依存関係のためにエラーが発生したケースで解決するまでの記録です。
自動起動登録~サービス稼働状態確認まで
snmptrapd.serviceとmariadb.serviceに依存関係があるケースで、以下のように自動起動を登録して、リブートします。
# systemctl enable snmptrapd.service
# systemctl enable mariadb.service
# reboot
起動後にサービスの稼働状態を以下コマンドで確認します。
# systemctl status snmptrapd.service
mariadbに関係するエラーが発生しました。

起動順の前後関係で問題が発生していることの確認まで
mariadbのサービス稼働状態を確認してみると、正常に稼働していました。
# systemctl status mariadb.service

snmptrapd.serviceを再起動してみると、正常起動しています。
# systemctl restart snmptrapd.service
# systemctl status snmptrapd.service
このことから、起動順の前後関係が解決すれば、snmptrapd.serviceが正常稼働できることがわかりました。

実際の起動順をグラフ化してみると、snmptrapd.serviceがmariadb.service起動前に始まり、mariadb.serviceが起動完了前に実行完了していることがわかります。
# systemd-analyze plot > unitstart.html
# firefox unitstart.html

起動前後関係設定~解決まで
snmptrapd.serviceをmariadb.service起動完了後にはじまるように設定します。
# vi /etc/systemd/system/multi-user.target.wants/snmptrapd.service
Unitディレクティブに
After=mariadb.service
を追記します。

マシンを再起動してみると、前回起動時にはエラーであったsnmptrapd.serviceが正常に稼働したことがわかります。
# systemctl status snmptrapd.service

実際の起動順を確認してみると、mariadb.serviceが稼働後にsnmptrapd.serviceが起動されたことがわかります。
# systemd-analyze plot > unitstart2.html
# firefox unitstart2.html

TomcatでMariaDBへの接続Poolを使う
Introduction
使用するデータベースがMySQLの後継であるMariaDBに決まった。
ServletアプリケーションからアクセスするときにTomcatで定義したデータソースのDB接続Poolを使いたい。
Environment
- Tomcat 7.0.69
- MariaDB 5.5.52
Procedure
前提
- TomcatとMariaDBがインストールされ、いずれも正常稼働できる状態である
サーバでの手順
①JDBC接続でMariaDBへ接続するためのドライバを入手する
https://downloads.mariadb.org/connector-java/
②入手したドライバをTomcatのライブラリに配置する
/usr/share/java/tomcatにmariadb-java-client-x.x.x.jarを配置
③Tomcatのコンテキストに接続Poolの定義を追記
/etc/tomcat/context.xml に追記する
- パターンA Commons DB Connection Poolを利用するパターン
<Resource name="jdbc/MariaDB" auth="Container" type="javax.sql.DataSource"
maxActive="100" maxIdle="20" maxWait="-1" username="ユーザー" password="パスワード"
driverClassName="org.mariadb.jdbc.Driver"
url="jdbc:mysql://localhost:3306/データベース名?zeroDateTimeBehavior=convertToNull"
validationQuery="SELECT 0" factory="org.apache.commons.dbcp.BasicDataSourceFactory"/>
- パターンB Tomcat Jdbc Connection Poolを利用するパターン tomcat 7.0.19以降
<Resource name="jdbc/MariaDB" auth="Container" type="javax.sql.DataSource"
maxActive="100" maxIdle="20" maxWait="-1" username="ユーザー" password="パスワード"
driverClassName="org.mariadb.jdbc.Driver"
url="jdbc:mysql://localhost:3306/データベース名?zeroDateTimeBehavior=convertToNull"
validationQuery="SELECT 0" factory="org.apache.tomcat.jdbc.pool.DataSourceFactory"/>
④Tomcatの再起動
systemctl restart tomcat
Java Sample
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.sql.DataSource;
/**
* コネクションプールを利用したDB接続
*
*/
public class DBConnectionUsePool {
private PreparedStatement pstmt = null;
private Connection conn = null;
public synchronized boolean connect(){
try {
InitialContext ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("java:comp/env/jdbc/MariaDB");
this.conn = ds.getConnection();
} catch (NamingException e) {
return false;
} catch (SQLException e) {
return false;
}
return true;
}
/**
* SQLをセットする
*
* @param sql
* @return
*/
public synchronized boolean sqlSet(String sql){
if(this.conn == null) {
return false;
}
try {
this.pstmt = this.conn.prepareStatement(sql);
} catch (SQLException e) {
return false;
}
return true;
}
/**
* ステートメントを取得
* @return
*/
public synchronized PreparedStatement getStatement(){
return this.pstmt;
}
}
音と映像の同期[max/msp -> Processing]_その1
開発環境
言語
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、
ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/172
- java 1.8.0_9
Processingで使用しているバージョン
ソフトウェア
- Ableton Live 9.7.1
- Max 7.3.1
- java 1.6.0_65
Max for Liveで使用しているバージョン
補足
最新のバージョンでは利用できないため、1.6を使用する
JAVA_HOMEの切り替え手順
OS
- macOS sierra 10.12.2
Processingでアウトプットとなるイメージを作成する
四角形をランダムに表示するアニメーションを作成します。
値をランダムに指定している箇所は以下となります。
四角形の描画数、表示位置、横幅、縦幅、線(stroke)の彩度。
コード
package rectangle;
import java.util.Calendar;
import processing.core.PApplet;
public class RandomRect_Base extends PApplet{
public void settings() {
fullScreen();
smooth();
}
public void setup() {
noCursor();
frameRate(30);
background(0);
}
public void draw() {
background(0);
//四角形の数
int rectNum = (int)random(1,30);
pushMatrix();
translate(width/2, height/2);
for(int i=0;i<=rectNum;i++){
//四角形の表示位置
int x = (int)random(50);
int y = (int)random(50);
//四角形の横幅と縦幅
int rectWidth = (int)random(500);
int rectHeight = (int)random(500);
//図形の色を透明に設定
noFill();
//線の彩度
int rectAlpha = (int)random(255);
//図形の線を白色に設定
stroke(255,rectAlpha);
rectMode(CENTER);
//四角形を描画
rect(x, y, rectWidth, rectHeight);
}
popMatrix();
}
public void keyReleased(){
if(key == 's' || key == 'S')
saveFrame("./src/" + timestamp()+"_##.png");
}
String timestamp(){
Calendar now = Calendar.getInstance();
return String.format(
"%1$ty%1$tm%1$td_%1$tH%1$tM%1$tS",
now);
}
public static void main(String[] args) {
PApplet.main(RandomRect_Base.class.getName());
}
}
実行結果
音と映像の同期[max/msp -> Processing]_その2
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、
ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/172
- java 1.8.0_9
Processingで使用しているバージョン
ソフトウェア
- Ableton Live 9.7.1
- Max 7.3.1
- java 1.6.0_65
Max for Liveで使用しているバージョン
補足
最新のバージョンでは利用できないため、1.6を使用する
JAVA_HOMEの切り替え手順
OS
- macOS sierra 10.12.2
Max for Liveが提供しているConnection Kitを利用して、ProcessingへMIDIデータを送信する
MAX/MSPでOSC送信パッチを一から作成しようと試みましたが、Max for Liveが提供しているConnection Kitの存在を発見したので利用してみます。
ただし、基礎は理解しておいた方が良いので、以下サイトを参考にサンプルをパッチ作成したうえで利用することを
お薦めします。
- MAX/MSPのOSC連携を紹介するサイト
http://neralt.com/max-processing-osc-relation/
MAXとProcessingのOSC連携について基礎から説明されているのでわかりやすいです。
具体的なイメージスケッチが紹介されているので、真似っこして作成するだけで楽しめます。
ballクラスの構造については、ボーンデジタルが刊行している
Nature of Code -Processingではじめる自然現象のシミュレーション-
の序盤を勉強しておくと理解が深まると思います。
- Connection Kitのダウンロード
次のURLよりダウンロードできます。紹介映像を見るだけでワクワクします。
https://www.ableton.com/ja/packs/connection-kit/
Connection KitのOSC MIDI Sendを修正
OSC MIDI SendはMIDIノートとベロシティデータをProcessingスケッチへOSCメッセージとして送信するパッチです。
利用するにあたり、OSCデータが次のようなレイアウトで、Processingでコントールする仕方が思いつかなかったので、
パッチ修正しレイアウトを変更しています。
以下、Connection Kitで提供しているOSC_Monitorの出力結果です。
---修正前のレイアウト-
次のようにレイアウトを変更しています。
/Note + ボイスナンバ + SPACE + キーナンバ
/Note + ボイスナンバ + SPACE + ベロシティ
↓
/Note + キーナンバ + SPACE + ベロシティ
---修正後のレイアウト-

パッチについては修正箇所のみを載せておきます。簡単かつ自分に都合の良い修正で、Connection Kit作者に申し訳ないです。

ableton liveでトラックを作成する
Drumkitを利用しoperatorで作成した音色を割り当てしています。
映像との同期といえばと言うことで、alva noto風の音源を作成してみました。
音作りは初心者のため、以下サイトを参考にして自分好みの音にしています。
https://music.tutsplus.com/tutorials/how-to-synthesize-a-glitch-drum-kit-with-operator--audio-10397


Drum Rackには次のように音源を割り当てしています。
※使用する音源の抜粋
beep Note44
drone Note40
kick Note41
click Note36
hihat Note50

音を奏でたときのモニター内容です。
音はその3でProcessingと同期した映像で紹介します。
音と映像の同期[max/msp -> Processing]_その3
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、
ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/172
- java 1.8.0_9
Processingで使用しているバージョン
ソフトウェア
- Ableton Live 9.7.1
- Max 7.3.1
- java 1.6.0_65
Max for Liveで使用しているバージョン
補足
最新のバージョンでは利用できないため、1.6を使用する
JAVA_HOMEの切り替え手順
OS
- macOS sierra 10.12.2
Ableton liveより送信したOSCデータをProcessingで受信しイメージに反映する
OSCデータを受信
1.oscP5をインポート
次のサイトにライブラリが公開されています。
http://www.sojamo.de/libraries/oscP5/
Processing IDEのメニューより、スケッチ->ライブラリをインポート->ライブラリを追加
でダウンロードも可能です。
2.setupメソッドに受信ポートを設定
Ableton Liveのデフォルトポート2346を指定します。
Ableton LiveのOSC Monitorを使用しているとOSC Monitorがポートを使ってしまい受信できないので注意してください。
public void setup() {
//〜〜〜〜〜省略〜〜〜〜〜〜〜〜〜〜
//2346ポートでOSCデータを受信
o = new OscP5(this, 2346);
}
3.OSCデータを受信
OSCデータを受信するたびに呼び出されるメソッドoscEventを使用して
メッセージのタグに応じてデータの値を取得します。
受信したデータは適切な値にマッピングしておきます。
public void oscEvent(OscMessage theMsg) {
//〜〜〜〜〜省略〜〜〜〜〜〜〜〜〜〜
//Note41[kick]の音で四角形の数、位置、横幅、縦幅を増加値を設定
if(theMsg.checkAddrPattern("/Note41")==true) {
float note41 = theMsg.get(0).intValue();
oscRectNum = map(note41, 0, 127, 1, 30);
oscPlace = map(note41,0,127,1,150);
oscRectWidth = map(note41, 0, 127, 1, 600);
oscRectHeight = map(note41, 0, 127, 1, 600);
}
//〜〜〜〜〜省略〜〜〜〜〜〜〜〜〜〜
}
4.OSCデータをイメージに反映
次の例は、四角形の横幅と縦幅に反映しています。
public void draw() {
//〜〜〜〜〜省略〜〜〜〜〜〜〜〜〜〜
//四角形の横幅と縦幅
int rectWidth = (int)random(5,100 + oscRectWidth);
int rectHeight = (int)random(5,100 + oscRectHeight);
//〜〜〜〜〜省略〜〜〜〜〜〜〜〜〜〜
}
音とイメージは次のようにリンクさせています。
beep Note44 -> 横幅を増加、縦幅を減少
drone Note40 -> 描画をスタート
kick Note41 -> 四角形の数を増加、位置の範囲を増加、横幅を増加、縦幅を増加
click Note36 -> 使用していない。(今後,Phillips Hueと連携予定)
hihat Note50 -> 背景と図形の色を反転
コード
package rectangle;
import oscP5.OscMessage;
import oscP5.OscP5;
import processing.core.PApplet;
public class RandomRect_MaxMsp extends PApplet{
//描画のスタートを制御
boolean start;
//色の反転を制御
boolean flash;
//---------------- OSC ---------------------
OscP5 o;
//OSCデータのベロシティ値
float note37,note40,note44,note50;
//OSC値で可変とする四角形の値
float oscRectNum = 1F; //表示数
float oscPlace = 0; //表示位置
float oscRectWidth = 0; //横幅
float oscRectHeight = 0; //縦幅
public void settings() {
fullScreen();
smooth();
}
public void setup() {
noCursor();
println("width:"+width);
println("height:"+height);
frameRate(30);
//背景を黒色
background(0);
//2346ポートでOSCデータを受信
o = new OscP5(this, 2346);
}
public void draw() {
//背景を黒色にし図形を初期化
background(0);
//図形を白色
int baseColor = 255;
//flashフラグがオンでイメージカラーを反転
if (frameCount / 5 % 2 == 0 && flash == true) {
//白と黒を反転
background(baseColor);
baseColor = 0;
}
if(start){
//四角形の数
int rectNum = (int)random(1,oscRectNum);
pushMatrix();
translate(width/2, height/2);
for(int i=0;i<=rectNum;i++){
//四角形の表示位置
int x = (int)random(-10-oscPlace,10+oscPlace);
int y = (int)random(-10-oscPlace,10+oscPlace);
//四角形の横幅と縦幅
int rectWidth = (int)random(5,100 + oscRectWidth);
int rectHeight = (int)random(5,100 + oscRectHeight);
//図形の色を透明に設定
noFill();
//線の彩度
int rectAlpha = (int)random(0,255);
stroke(baseColor,rectAlpha);
rectMode(CENTER);
rect(x, y, rectWidth, rectHeight);
}
popMatrix();
}
}
public void oscEvent(OscMessage theMsg) {
//Note40[drone]の音で描画を開始、停止
if(theMsg.checkAddrPattern("/Note40")==true) {
float note40 = theMsg.get(0).intValue();
if(note40 == 0){
start = false;
}else{
start = true;
}
}
//Note41[kick]の音で四角形の数、位置、横幅、縦幅を増加値を設定
if(theMsg.checkAddrPattern("/Note41")==true) {
float note41 = theMsg.get(0).intValue();
oscRectNum = map(note41, 0, 127, 1, 30);
oscPlace = map(note41,0,127,1,150);
oscRectWidth = map(note41, 0, 127, 1, 600);
oscRectHeight = map(note41, 0, 127, 1, 600);
}
//Note44[beep]の音で四角形の、横幅の増加値、縦幅の減少値を設定
if(theMsg.checkAddrPattern("/Note44")==true) {
float note44 = theMsg.get(0).intValue();
oscRectHeight = map(note44, 0, 127, -10, -100);
oscRectWidth = map(note44, 0, 127, 1, 1700);
}
//Note50[hihat]の音でイメージカラーの反転を制御
if(theMsg.checkAddrPattern("/Note50")==true) {
float note50 = theMsg.get(0).intValue();
if(note50 == 0){
flash = false;
}else{
flash = true;
}
}
}
public void keyPressed() {
switch (key) {
case 's':
start = !start;
break;
case 'f':
flash = !flash;
break;
default:
break;
}
}
public static void main(String[] args) {
PApplet.main(RandomRect_MaxMsp.class.getName());
}
}
実行結果
awkで色々な処理を行う。
UNIX/Linuxでシェルスクリプトじゃ出来ないけども、ちょっと複雑なことをしたい。
でも、Javaとかで作りこむほどではない。
そんなときにawkを使うと便利だ。
例えばこんな感じのアクセスログがあって、平均の応答時間を求めたい場合時など。
# 末尾の数字を応答時間(秒)とする。
111.22.33.44 - - [11/Jan/2017:09:00:00 +0900] "GET /index.html" 200 1472 10
111.22.33.44 - - [11/Jan/2017:09:01:00 +0900] "GET /index.html" 200 1472 5
111.22.33.45 - - [11/Jan/2017:09:02:00 +0900] "GET /index.htm" 404 1472 0
111.22.33.45 - - [11/Jan/2017:09:02:00 +0900] "GET /index.html" 200 1472 3
awkを使えば一行で処理ができる。
awk 'BEGIN { i=0 } { i=i+$NF } END { print "avg " i/NR " sec"}' <入力ログファイル名>
簡単に解説すると、以下のようなことをしている。
BEGIN { i=0 } : 処理を開始する前の初期設定
{ i=i+$NF } : awk は入力ファイルを1行ずつ読み込んで処理をする。
読み込んだパラメータは、区切り文字(デフォルトでは半角スペース)に従い自動的に分割し、変数に格納される。
$0 は行全体、$1以降はそれぞれ数字の分の要素になる。
NF は行全体の要素数が自動的に入る。したがって、$NFは自動的に末尾の数字になる。
ここでは、1行ごとに読み込んで変数「i」に加算している。
END { print "avg " i/NR " sec" } :
END は、全ての行を読み込んだ後に処理される。
NR は、処理を行った行数が自動的に入る。ENDまで来ると、自動的にファイルの行数になる。
なので、これで応答時間の合計を除算すると平均の時間になる。
これを実行すると、こんな感じの結果になる。
[root@localhost ~]# cat test.log
111.22.33.44 - - [11/Jan/2017:09:00:00 +0900] "GET /index.html" 200 1472 10
111.22.33.44 - - [11/Jan/2017:09:01:00 +0900] "GET /index.html" 200 1472 5
111.22.33.45 - - [11/Jan/2017:09:02:00 +0900] "GET /index.htm" 404 1472 0
111.22.33.45 - - [11/Jan/2017:09:02:00 +0900] "GET /index.html" 200 1472 3
[root@localhost ~]#
[root@localhost ~]# awk 'BEGIN { i=0 } { i=i+$NF } END { print "avg " i/NR " sec"}' test.log
avg 4.5 sec
[root@localhost ~]#
4行程度ではわざわざこんなことする方が面倒なのだけども、実際のアクセスログだと何万行を軽く超えるような環境もあるので、
そんな場合ではいちいちローカルPCにダウンロードしてきてExcelとか使って解析するよりも、サーバー上でパパッと処理してしまった方が早い。サーバーリソースには要注意だけども……
また、awkは正規表現を使って特定行のみを処理するということも出来るので、特定IPからの平均応答時間のみを集計することなども可能。
awk 'BEGIN { i=0;j=0 } $1 == "111.22.33.45" { i=i+$NF;j=j+1 } END { print "avg " i/j " sec"}' <ログファイル名>
先ほどのawk文と比べると、変数が一個増えて、BIGIN{}の後に正規表現が追加されている。
こうすると、マッチングする行のみを対象として処理を行う用になる。
では、実行してみよう。
[root@localhost ~]# awk 'BEGIN { i=0;j=0 } $1 == "111.22.33.45" { i=i+$NF;j=j+1 } END { print "avg " i/j " sec"}' test.log
avg 1.5 sec
[root@localhost ~]#
先ほどと同じログに対して実行しても、違う結果が返ってきた。
このように、特定の条件にマッチングするリクエストのみに対して処理が出来たりもする。
IP以外にもHTTPレスポンスコードから抽出したり、一定以上の応答時間のアクセスを抽出したりもできる。
#404以外のアクセスを抽出
[root@localhost ~]# awk '$8 != "404" { print $0 }' test.log
111.22.33.44 - - [11/Jan/2017:09:00:00 +0900] "GET /index.html" 200 1472 10
111.22.33.44 - - [11/Jan/2017:09:01:00 +0900] "GET /index.html" 200 1472 5
111.22.33.45 - - [11/Jan/2017:09:02:00 +0900] "GET /index.html" 200 1472 3
[root@localhost ~]#
#5秒以上の応答時間のアクセスを抽出
[root@localhost ~]# awk '$NF >= 5 { print $0 }' test.log
111.22.33.44 - - [11/Jan/2017:09:00:00 +0900] "GET /index.html" 200 1472 10
111.22.33.44 - - [11/Jan/2017:09:01:00 +0900] "GET /index.html" 200 1472 5
[root@localhost ~]#
余分なデータを除外したり、特定のデータを抽出することを繰り返して解析の精度を上げたりしていける。
awk はコマンドラインから実行できるので、シェルに組み込むことも簡単だ。
一度実行した処理をまとめてシェルにしておけば、次回以降同じ作業を簡単に実施できる。
定例的な処理とか、何か問題が起きた時に使うモノを纏めておくと便利でかっこいいんじゃないかな。
awkで複数行処理を行う
awk は基本的に1行ずつ処理をするのだけども、XMLを見るときなんかはどうしても複数行処理したくなることがある。
そんなときに便利な関数が「getline」だ。
getline を引数なしで呼び出すと、今処理している行の次の1行読み込んで、$0とかNFとかに新しい値をセットする。
(前の$0とか消えてしまうけども、それが嫌ならgetlineに引数を渡すと、そこに格納してくれるようだ)
実際に試してみた方が早いと思うので、以下のようなXMLファイルから、特定の値をとりだすことをやってみる。
[root@localhost ~]# cat example.xml
<?xml version="1.0">
<gloup name="gloup1">
<menber>member1</menber>
<menber>member2</menber>
<menber>member3</menber>
</gloup>
<gloup name="gloup2">
<menber>memberA</menber>
<menber>memberB</menber>
<menber>memberC</menber>
</gloup>
<gloup name="gloup3">
<menber>memberX</menber>
<menber>memberY</menber>
<menber>memberB</menber>
</gloup>
[root@localhost ~]#
gloup1 と gloup3のmemberだけ取り出したい、というときに、getlineを使うと比較的簡単に処理が出来る。
awk '$1 == "<gloup" && $2 ~ /gloup(1|3)/ { print $2 ; while ( getline ) { if ($0 ~ /<\/gloup>/ ) { break } else { print $0 } } }' example.xml
while とか if は一般的なプログラム言語とだいたい同じ動きをする。
ここでは、gloup要素を発見すると、2カラム目を参照し、それがgloup1かgloup3だった時に、</gloup>が来るまで行を出力している。
実行結果はこんな感じ。
[root@localhost ~]# cat example.xml
<?xml version="1.0">
<gloup name="gloup1">
<menber>member1</menber>
<menber>member2</menber>
<menber>member3</menber>
</gloup>
<gloup name="gloup2">
<menber>memberA</menber>
<menber>memberB</menber>
<menber>memberC</menber>
</gloup>
<gloup name="gloup3">
<menber>memberX</menber>
<menber>memberY</menber>
<menber>memberB</menber>
</gloup>
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# awk '$1 == "<gloup" && $2 ~ /gloup(1|3)/ { print $2 ; while ( getline ) { if ($0 ~ /<\/gloup>/ ) { break } else { print $0 }
} }' example.xml
name="gloup1">
<menber>member1</menber>
<menber>member2</menber>
<menber>member3</menber>
name="gloup3">
<menber>memberX</menber>
<menber>memberY</menber>
<menber>memberB</menber>
[root@localhost ~]#
複数の機器でミドルウェアのセットアップとかした時、いちいち結果をGUIで確認すると時間がかかって仕方がない。
直接XMLを見るときに、こんな感じで該当箇所だけ抜き出せると良い感じ。
(sub 関数とか上手く使えば出力結果を綺麗に整形できると思うけども、今回は割愛)
ビッグエンディアンとリトルエンディアン
C言語(AIX)からの移植作業で問題となった事案を紹介
●バイトオーダー
コンピュータの内部ではデータは全て2進数で扱う仕組みになっている
2進数で 00000000 ~ 11111111 (16進数で 0x00~0xff)で表される単位、つまり8ビットを1バイト
コンピュータでデータをメモリに読み書きしたり、ディスクに読み書きするときには、1バイトを最小単位にして行う
例えば、0x12,0x34,0x56,0x78 という4つのデータがある。
これをメモリ中の0x1000番地から書き込む。
0x1000番地:0x12
0x1001番地:0x34
0x1002番地:0x56
0x1003番地:0x78
これよりも大きなサイズのデータ
例えば、0x12345678
これをメモリ中の0x1000番地から書き込む。
0x1000番地:0x12
0x1001番地:0x34
0x1002番地:0x56
0x1003番地:0x78
連続した4番地をひとかたまりのデータとして管理
世の中にはこのようなデータ格納方式を取らないものもある。
0x1000番地:0x78
0x1001番地:0x56
0x1002番地:0x34
0x1003番地:0x12
順番を逆転させて格納する方式がある。
このバイト並びの方式をエンディアン(Endian)と呼ぶ。
前者の、0x12(つまり桁の大きいほう)から順番に格納する方式をビッグエンディアン(Big Endian)
後者の、0x78(つまり桁の小さいほう)から順番に格納する方式をリトルエンディアン(Little Endian)
●CPUとエンディアン
エンディアンはCPUによって決まる。
PowerPCなどはビッグエンディアン。
Intel系などはリトルエンディアン。
MIPS や ARM、SHなど、どちらにもなれるプロセッサも存在していて、バイエンディアン。
●困ってたこと
メモリ上のデータの持ち方が変わっても特に問題なし
int a = 1;
(0x00000001)
・ビッグエンディアン
0x1000番地:0x00
0x1001番地:0x00
0x1002番地:0x00
0x1003番地:0x01
・リトルエンディアン
0x1000番地:0x01
0x1001番地:0x00
0x1002番地:0x00
0x1003番地:0x00
ビッグエンディアンが前提のコードで問題あり(バイト単位の比較)
int memcmp( const void *str1 , const void *str2, size_t len );
str1とstr2をlen文字分比較して等しい場合は0、
同様にstr1がstr2より大きい場合(str1>str2)は正の整数、
同様にstr1がstr2より小さい場合(str1<str2)は負の整数を返す。
0x00000001と0x00000100を比較
・ビッグエンディアン
0x1000番地:0x00
0x1001番地:0x00
0x1002番地:0x00
0x1003番地:0x01
0x1000番地:0x00
0x1001番地:0x00
0x1002番地:0x01
0x1003番地:0x00
・リトルエンディアン
0x1000番地:0x01
0x1001番地:0x00
0x1002番地:0x00
0x1003番地:0x00
0x1000番地:0x00
0x1001番地:0x01
0x1002番地:0x00
0x1003番地:0x00
●対策
typedef struct data
{
unsigned char a[4];
unsigned char b[4];
unsigned char c[4];
} DATA;
ビッグエンディアンのように変換して比較処理
unsigned char tmp[12] = {
a[3],
a[2],
a[1],
a[0],
b[3],
b[2],
b[1],
b[0],
c[3],
c[2],
c[1],
c[0]};
既存の処理をあまり変えないように対応する
●余談
ビッグエンディアンとリトルエンディアンという単語は、『ガリバー旅行記』の中のエピソードに由来する。
第1部「小人国」(ガリバーが浜辺で小さい人たちに、たくさんの細いロープで縛り付けられている絵本を覚えている人も多いだろう)では、
卵を丸い方(大きい方)の端から割る人々 (Big Endians) と、尖った方(小さい方)の端から割る人々(Little Endians) との対立が描かれている。
スウィフトが書いた風刺小説「ガリバー旅行記」に登場する「ビッグ・エンディアンとリトル・エンディアン」は、
キリスト教のカトリック(旧教)とプロテスタント(新教)を指しています。
つまり、「ゆで卵の割り方のような”ささいな違い”」から争いが続いている状況を、スウィフトはガリバー旅行記として風刺していたのです。
照明を制御[Processing -> Philips hue]_その1
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
Processingで使用しているバージョン
照明
- Philips Hue スターターセット v2
OS
- macOS sierra 10.12.2
hueのデバッグ画面にアクセスする。
hueのIPアドレスを調べる
[{"id":"xxxxxxxxxxxxxxxx","internalipaddress":"192.168.0.13"}]
hueのデバッグ画面を表示する
次のURLにIPアドレスをブラウザで指定しアクセスするとデバック画面が表示されます。
http://[hueのIPアドレス]/debug/clip.html

ユーザを作成
失敗例
サイトで紹介してくれている記事を参考に次の内容でユーザ作成すると
「Command Responseでparameter, username, not available」のエラーで失敗します。
以下、内容でPOST送信する。
URL:
/api
Message Body:
{"devicetype": "Procesing", "username": "test_user"}
Method:
post
Command Response:
[
{
"error": {
"type": 6,
"address": "/username",
"description": "parameter, username, not available"
}
}
]
エラーの原因を調べてみると、usernameのパラメータが使用できないようになったようです。
どのバージョンからは不明ですが、以下サイトを参照にしてください。
そのため、ランダムで設定されたユーザを使用します。
https://developers.meethue.com/documentation/important-whitelist-changes
api仕様
成功例
apiの仕様通り、devicetypeに<application_name>#<devicename>を指定しユーザを作成すると
link button not pressedのエラーが出力されるので
hueブリッジのリンクボタンを押してから、もう一度送信すると
ランダムなユーザネームを取得する事ができます。
URL:
/api
Message Body:
{"devicetype": "Processing_test_app#mac tetsu"}
Method:
post
結果:リンクボタンエラー Command Response:
[
{
"error": {
"type": 101,
"address": "",
"description": "link button not pressed"
}
}
]
結果:成功
[
{
"success": {
"username": "bqpn9A3MgqjglZ-oKpfHyOgA2sRsIJs4qOu7RvKH"
}
}
]
照明を制御
api仕様
ライトを点灯
次のURLで
/api/{ユーザ名}/lights/{電球のID}/state
Message Bodyに「"on": true」
を指定。
URL:
/api/bqpn9A3MgqjglZ-oKpfHyOgA2sRsIJs4qOu7RvKH/lights/2/state
Message Body:
{"on": true}
Method:
put
Command Response:
[
{
"success": {
"/lights/2/state/on": true
}
}
]

ライトの色を変更
Message Bodyに指定した「"on": true」に加えて
「"hue": 0, "bri": 255, "sat": 255」
を指定する事により、赤色で点灯します。
Hueでは、HSBカラーモデルのhue(色相:0~65535)、sat(彩度:0~254)、bri(明度:0~254)の3つの属性値でライトの色を指定します。
URL:
/api/bqpn9A3MgqjglZ-oKpfHyOgA2sRsIJs4qOu7RvKH/lights/2/state
Message Body:
{"on": true,"hue": 0, "bri": 254, "sat": 254}
Method:
put
Command Response:
[
{
"success": {
"/lights/2/state/on": true
}
},
{
"success": {
"/lights/2/state/hue": 0
}
},
{
"success": {
"/lights/2/state/sat": 254
}
},
{
"success": {
"/lights/2/state/bri": 254
}
}
]

LINQ to Objects を使ってみよう
LINQ to Objectとは?
LINQとは.NET Frameworkに含まれる技術で、クエリを行う1つのパターン。
LINQ to Objectは、メモリ上のオブジェクトをクエリするプロバイダ。
(他にも LINQ to SQL, LINQ to XMLなどがある)
LINQ to Objectは、コレクションに対して作用し一括して何かの処理を行うことができる。
厳密には、IEnumerable<T>インターフェースに作用するためListや配列に対しても利用できる。
何が嬉しいか?
反復処理がスマートに書ける。強引かつ簡単に表現するとfor文が消せる。
(for文は終了条件やインデックスアクセスでミスを誘発するので好きじゃない)
例)配列の値を2倍する
int[] a = { 1, 2, 3 }
for(int i = 0; i < a.Length; i++)
{
a[i] *=2;
}
↓
a = a.Select(n => n * 2).ToArray();
例)配列から奇数を取得
int[] a = { 1, 2, 3 }
var list = new List<int>();
for(int i = 0; i < a.Length; i++)
{
if(a[i] % 2 != 0)
{
list.Add(a[i]);
}
}
↓
var list = a.Where(n => n % 2 != 0).ToList();
こんな感じでソースコードの可読性が上がる。コード量も減る。
コード量が減ると生産性が上がり、ミスも減り、テストも減る。
ループ制御に使っていた神経が、もっと人間がやるべき大切なことに使える。
ここしばらく、業務でC言語に触れる機会が多かった。
改めて感じたがやっぱりC#は便利だ。
照明を制御[Processing -> Philips hue]_その2
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
Processingで使用しているバージョン
照明
- Philips Hue スターターセット v2
OS
- macOS sierra 10.12.2
HSBカラーモデルのパレットを作成
色のスペクトルを円形に配置した色相環を作成します。
扇形の図形を配置して作ります。それぞれの頂点は、対応する角度のコサインとサインから求めています。
また、マウスでクリックした色を取得し、Phillips Hue APIに対応するJSON形式に整形しコンソールに出力します。
コード
package colorPalette;
import org.json.JSONObject;
import processing.core.PApplet;
public class HSBcolorPalette extends PApplet{
//半径の長さ
int radius = 300;
//角度の増加量
int segmentCount = 360;
//HSBカラーの彩度
int saturation = 254;
//HSBカラーの明度
int brightness = 254;
//lightナンバー
int lightnum = 1;
//heuAPI連携用のJSONオブジェクト
JSONObject jsonObject;
public void settings() {
size(800, 800);
}
public void setup() {
noStroke();
//背景色に黒色を指定
background(0);
}
public void draw() {
//カラーモードをHSBモードで指定
//hue:色相を360°円周の範囲
//Saturation:hueの彩度の範囲
//brightness:hueの輝度の範囲
colorMode(HSB,360,254,254);
//角度の増加量
float angleStep = 360/segmentCount;
beginShape(TRIANGLE_FAN);
//頂点を中心に設定
vertex(width/2,height/2);
for(float angle=0;angle<=360;angle+=angleStep){
float vx = width/2 + cos(radians(angle))*radius;
float vy = height/2 + sin(radians(angle))*radius;
vertex(vx,vy);
//angleの値を色相に設定
fill(angle,saturation,brightness);
}
endShape();
}
public void mousePressed() {
//色情報を配列pixelsとして読み込む
loadPixels();
//マウスの座標位置を取得
int x = constrain(mouseX, 0, width-1);
int y = constrain(mouseY, 0, height-1);
//マウスクリックした位置の色を取得
int color = pixels[y*width + x];
//HSBカラーの形式に変換
//色相をhueの色相範囲にマッピング
int hue = (int)map(hue(color), 0, 360, 0, 65535);
//彩度を設定
int saturation = (int)saturation(color);
//輝度を設定
int brightness = (int)brightness(color);
//JSON形式に整形
hueLight(lightnum, true, hue, saturation, brightness);
//背景色をマウスクリックした色に設定
background(color);
}
//JSONのレイアウトに整形
public void hueLight(int lightnum,boolean on,int hue,int saturation,int brightness) {
jsonObject = new JSONObject();
jsonObject.put("on", on);
jsonObject.put("hue", hue);
jsonObject.put("sat", saturation);
jsonObject.put("bri", brightness);
println(jsonObject.toString());
}
public void keyPressed() {
//輝度を変更
if(keyCode == RIGHT) brightness += 10;
if(keyCode == LEFT) brightness -= 10;
brightness = max(brightness,0);
brightness = min(brightness,254);
//彩度を変更
if(keyCode == UP) saturation += 10;
if(keyCode == DOWN) saturation -= 10;
saturation = max(saturation,0);
saturation = min(saturation,254);
//角度の増加量を変更
if(key == 'a') segmentCount += 10;
if(key == 'd') segmentCount -= 10;
segmentCount = min(segmentCount,360);
segmentCount = max(segmentCount,1);
//制御するlightを設定
if(key == '1') lightnum = 1;
if(key == '2') lightnum = 2;
if(key == '3') lightnum = 3;
}
public static void main(String[] args) {
PApplet.main(HSBcolorPalette.class.getName());
}
}
結果
起動時

マウスクリック[青色をクリック]

コンソール出力内容
{"sat":254,"bri":254,"hue":44032,"on":true}
hueのデバッグ画面にコンーソルの出力内容を貼り付け

ライト点灯

セッションを手動で強制終了させる方法
残留セッション
データベースに接続中にあるセッションではSQL実行中にフリーズしたがセッションは生き残っている場合やデータベースをシャットダウンしたいが接続中のユーザが残っている場合などが想定される。後者の場合、 shutdown immediate なら、トランザクションが終了するのを待たずにロールバックしてセッションを切断するからよいが、normal や transactional では切断されるまで待ちが発生してしまう。このような時にセッションを手動で終了させる方法が有効である。
ユーザのセッションを強制終了させる例
SCOTTユーザでログイン
C:\work>sqlplus SCOTT/oracle
SQL*Plus: Release 11.2.0.1.0 Production on 金 2月 3 01:41:47 2017
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
に接続されました。
管理ユーザでログイン(別窓)
C:\work>sqlplus SYSTEM/oracle
SQL*Plus: Release 11.2.0.1.0 Production on 金 2月 3 01:54:56 2017
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
に接続されました。
v$sessionでSCOTTユーザの情報を取得
SQL> select sid, serial#, username, program from v$session where username = 'SCOTT';
SID SERIAL# USERNAME PROGRAM
---------- ---------- ------------------------------ -------------------
30 482 SCOTT sqlplus.exe
セッション強制終了
SQL> alter system kill session '30, 482';
システムが変更されました。
再度v$sessionでSCOTTユーザの情報を取得
SQL> select sid, serial#, username, program from v$session where username = 'SCOTT';
レコードが選択されませんでした。
SCOTTユーザーで検索を実行
セッションが強制終了されたためエラーになる。
SQL> select * from emp;
select * from emp
*
行1でエラーが発生しました。:
ORA-00028: セッションは強制終了されました。
その他
SQL> alter user scott account unlock;
ユーザーが変更されました。
SQL> alter user scott identified by "oracle";
ユーザーが変更されました。
見るメトロノーム
前書き
まだコードを書くことにあまり慣れていないので
とりあえず何かを作ってみようと思いました。
自分は音楽が好きなのでメトロノーム的なものを作ってみました。
具体的にどんなものかというと、
自分が欲しいBPMを入力すると ※BPM…Beats Per Minuteの略。
●がその速度で点滅するというものです。 1分間に何回のリズムが刻まれているかを示す。
コード
class Metronome
{
//任意のタイミングで終了させるためのもの
static bool End = false;
static void Main()
{
Console.WriteLine("BPMを入力してください。");
//BPMの入力
var BPM = int.Parse(Console.ReadLine());
Console.WriteLine("");
Console.WriteLine("設定したBPMで●が時を刻みます。");
Console.WriteLine("終了したい場合はEnterキーを押してください。");
Console.WriteLine("");
//3秒のカウントダウン
for (int timer = 3; 1 <= timer; timer--)
{
Console.CursorLeft = 0;
Console.Write("開始まで{0}秒", timer);
Thread.Sleep(1000);
}
Console.CursorLeft = 0;
Console.WriteLine("開始まで0秒");
Console.WriteLine("");
//処理の予約(実行可能な時に発動)
ThreadPool.QueueUserWorkItem(new WaitCallback(PushKey));
//キー入力があるまで設定BPMで点滅
while (true)
{
Console.CursorLeft = 0;
Console.Write("●");
Thread.Sleep(6000 / BPM);
Console.CursorLeft = 0;
Console.Write(" ");
Thread.Sleep(54000 / BPM);
if (End)
{
break;
}
}
}
//キー入力でEndをtrueに
static void PushKey(object State)
{
ConsoleKeyInfo keyInfo = Console.ReadKey(true);
End = true;
}
}

後書き
内容的にはシンプルですが、
一つ自分が作りたいものを作れたので
良かったなと思います。
次回も何か作るなら、
もう少し凝ったものを作りたいなと思います。
照明を制御[Processing -> Philips hue]_その3
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
Processingで使用しているバージョン
API
- Apache HttpComponets Http Client 4.5.2
https://hc.apache.org/httpcomponents-client-ga/index.html
maven pom.xml
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
- JSONObject 20160810
https://mvnrepository.com/artifact/org.json/json
maven pom.xml
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20160810</version>
</dependency>
照明
- Philips Hue スターターセット v2
OS
- macOS sierra 10.12.2
Apache HttpComponentsのHttpClientを利用してPhillips APIへ連携
JAVAでHttpClientを実装
上述のApache HttpComponets Http Client 4.5.2を利用します。
- コンストラクタ
HTTPClientを生成
- GETメソッド
指定したURLにGETリクエストを送信し、レスポンスコードが200か判定し、レスポンスの内容を返す
- PUTメソッド
指定したURLに、パラメータを付与しPUT送信し、レスポンスコードが200か判定し、
レスポンスの内容をコンソールに出力
コード
package http;
import java.util.List;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPut;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.message.BasicHeader;
import org.apache.http.util.EntityUtils;
import org.apache.http.Header;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
public class Http {
HttpClient client;
public Http() {
//ソケットタイムアウトに3秒を設定
int socketTimeout = 3000;
//コネクションタイムアウトに3秒を設定
int connectionTimeout = 3000;
//ユーザエージェント
String userAgent = "processing_app";
//設定を反映
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(socketTimeout)
.setConnectTimeout(connectionTimeout)
.build();
//ヘッダー情報
List<Header> headers = new ArrayList<Header>();
headers.add(new BasicHeader("Accept-Charset","utf-8"));
headers.add(new BasicHeader("Accept-Language","ja, en;q=0.8"));
headers.add(new BasicHeader("User-Agent",userAgent));
//HTTPクライアント生成
client = HttpClientBuilder.create()
.setDefaultRequestConfig(requestConfig)
.setDefaultHeaders(headers).build();
}
public String httpGet(String url) {
String responseStr = "";
HttpGet getMethod = new HttpGet(url);
try {
HttpResponse response = client.execute(getMethod);
int statusCode = response.getStatusLine().getStatusCode();
if(statusCode == HttpStatus.SC_OK){
HttpEntity entity = response.getEntity();
responseStr = EntityUtils.toString(entity,StandardCharsets.UTF_8);
}else{
System.out.println("failed access");
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return responseStr;
}
public void httpPut(String url,String param) {
HttpPut request = new HttpPut(url);
StringEntity params = new StringEntity(param,"UTF-8");
params.setContentType("application/json");
request.addHeader("content-type", "application/json");
request.addHeader("Accept", "*/*");
request.addHeader("Accept-Encoding", "gzip,deflate,sdch");
request.addHeader("Accept-Language", "en-US,en;q=0.8");
request.setEntity(params);
HttpResponse response;
try {
response = client.execute(request);
int statusCode = response.getStatusLine().getStatusCode();
if(statusCode == HttpStatus.SC_OK){
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity,StandardCharsets.UTF_8));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
ProcessingよりHTTPClientを使用し、hue APIへ連携
照明を制御[Processing -> Philips hue]_その2で作成したカラーパレットにコード追加し
hue APIと通信します。
1.setupメソッドでHttpClientを生成し、HueのIPアドレスを取得
public void setup() {
//-----省略--------------------------------------------
//httpClientを生成
http = new Http();
//hueのIPアドレスを取得
hueIPaddress = getIPAddress();
println(hueIPaddress);
}
2.IPアドレス取得するメソッドを作成
https://www.meethue.com/api/nupnpに対して、
GETリクエストでレスポンスを受信します。
レスポンス内容
[{"id":"xxxxxxxxxxxxxxxx","internalipaddress":"192.168.0.13"}]
「internalipaddress」キーにIPアドレスを設定されているのでJSONObjectを使用し取得します。
参照
public String getIPAddress() {
String response = http.httpGet(
"https://www.meethue.com/api/nupnp");
JSONArray jsonArray = new JSONArray(response);
JSONObject jsonObject = jsonArray.getJSONObject(0);
return jsonObject.getString("internalipaddress");
}
3.PUTメソッドでライトを点灯
マウスでクリックした色を取得し、Phillips Hue APIに対応するJSON形式に整形し
PUT送信します。
public void mousePressed() {
//-----省略--------------------------------------------
//HSBカラーの形式に変換
//色相をhueの色相範囲にマッピング
int hue = (int)map(hue(color), 0, 360, 0, 65535);
//彩度を設定
int saturation = (int)saturation(color);
//輝度を設定
int brightness = (int)brightness(color);
//JSON形式に整形
hueLight(lightnum, true, hue, saturation, brightness);
//-----省略--------------------------------------------
}
次のURLに対して、ライト点灯に必要な色相、彩度、輝度を送信します。
http://{hueIPアドレス}/api/{ユーザ名}/lights/{電球のID}/state
詳細のレイアウトについては、その1の照明を制御を参照
照明を制御[Processing -> Philips hue]_その1
//JSONのレイアウトに整形
public void hueLight(int lightnum,boolean on,int hue,int saturation,int brightness) {
jsonObject = new JSONObject();
jsonObject.put("on", on);
jsonObject.put("hue", hue);
jsonObject.put("sat", saturation);
jsonObject.put("bri", brightness);
println(jsonObject.toString());
String url = "http://" + hueIPaddress + "/api/" + hueUser +
"/lights/" + lightnum + "/state";
println(url);
http.httpPut(url,jsonObject.toString()+"\r\n");
}
結果
コード
package colorPalette;
import org.json.JSONArray;
import org.json.JSONObject;
import http.Http;
import processing.core.PApplet;
public class HSBcolorPalette extends PApplet{
//半径の長さ
int radius = 250;
//角度の増加量
int segmentCount = 360;
//HSBカラーの彩度
int saturation = 254;
//HSBカラーの明度
int brightness = 254;
//lightナンバー
int lightnum = 1;
//Http client
Http http;
//hue APIのIPアドレス
String hueIPaddress;
//hue APIのユーザ名
String hueUser = "bqpn9A3MgqjglZ-oKpfHyOgA2sRsIJs4qOu7RvKH";
//hue連携用のJSONオブジェクト
JSONObject jsonObject;
public void settings() {
size(600, 600);
}
public void setup() {
noStroke();
//背景色に黒色を指定
background(0);
//httpClientを生成
http = new Http();
//hueのIPアドレスを取得
hueIPaddress = getIPAddress();
println(hueIPaddress);
}
public void draw() {
//カラーモードをHSBモードで指定
//hue:色相を360°円周の範囲
//Saturation:hueの彩度の範囲
//brightness:hueの輝度の範囲
colorMode(HSB,360,254,254);
//角度の増加量
float angleStep = 360/segmentCount;
beginShape(TRIANGLE_FAN);
//頂点を中心に設定
vertex(width/2,height/2);
for(float angle=0;angle<=360;angle+=angleStep){
float vx = width/2 + cos(radians(angle))*radius;
float vy = height/2 + sin(radians(angle))*radius;
vertex(vx,vy);
//angleの値を色相に設定
fill(angle,saturation,brightness);
}
endShape();
}
public void mousePressed() {
//色情報を配列pixelsとして読み込む
loadPixels();
//マウスの座標位置を取得
int x = constrain(mouseX, 0, width-1);
int y = constrain(mouseY, 0, height-1);
//マウスクリックした位置の色を取得
int color = pixels[y*width + x];
//HSBカラーの形式に変換
//色相をhueの色相範囲にマッピング
int hue = (int)map(hue(color), 0, 360, 0, 65535);
//彩度を設定
int saturation = (int)saturation(color);
//輝度を設定
int brightness = (int)brightness(color);
//JSON形式に整形
hueLight(lightnum, true, hue, saturation, brightness);
//背景色をマウスクリックした色に設定
background(color);
}
//JSONのレイアウトに整形
public void hueLight(int lightnum,boolean on,int hue,int saturation,int brightness) {
jsonObject = new JSONObject();
jsonObject.put("on", on);
jsonObject.put("hue", hue);
jsonObject.put("sat", saturation);
jsonObject.put("bri", brightness);
println(jsonObject.toString());
String url = "http://" + hueIPaddress + "/api/" + hueUser +
"/lights/" + lightnum + "/state";
println(url);
http.httpPut(url,jsonObject.toString()+"\r\n");
}
public void keyPressed() {
//輝度を変更
if(keyCode == RIGHT) brightness += 10;
if(keyCode == LEFT) brightness -= 10;
brightness = max(brightness,0);
brightness = min(brightness,254);
//彩度を変更
if(keyCode == UP) saturation += 10;
if(keyCode == DOWN) saturation -= 10;
saturation = max(saturation,0);
saturation = min(saturation,254);
//角度の増加量を変更
if(key == 'a') segmentCount += 10;
if(key == 'd') segmentCount -= 10;
segmentCount = min(segmentCount,360);
segmentCount = max(segmentCount,1);
//制御するlightを設定
if(key == '1') lightnum = 1;
if(key == '2') lightnum = 2;
if(key == '3') lightnum = 3;
}
public String getIPAddress() {
String response = http.httpGet(
"https://www.meethue.com/api/nupnp");
JSONArray jsonArray = new JSONArray(response);
JSONObject jsonObject = jsonArray.getJSONObject(0);
return jsonObject.getString("internalipaddress");
}
public static void main(String[] args) {
PApplet.main(HSBcolorPalette.class.getName());
}
}
モーションセンサー[Kinect -> Processing]_その1
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
Processingで使用しているバージョン
モーションセンサー
Xbox 360® Kinect
API
SimpleOpenNI 1.96
Processing 3.x.xでSimpleOpenNIを利用する方法
Processing 3.x.xでSimpleOpenNIを利用するとExceptionが発生し利用できません。
対処方法が次のサイトに載っていたので参考し、対応しました。
registerDisposeメソッドの仕様が変わったみたいです。
https://forum.processing.org/two/discussion/13463/simpleopenni-fails-with-processing-3-0
Exception in thread "Animation Thread" java.lang.NoSuchMethodError: processing.core.PApplet.registerDispose(Ljava/lang/Object;)V
at SimpleOpenNI.SimpleOpenNI.initEnv(SimpleOpenNI.java:383)
at SimpleOpenNI.SimpleOpenNI.(SimpleOpenNI.java:255)
at kinnect.sample.Sample.setup(Sample.java:14)
at processing.core.PApplet.handleDraw(PApplet.java:2378)
at processing.awt.PSurfaceAWT$12.callDraw(PSurfaceAWT.java:1527)
at processing.core.PSurfaceNone$AnimationThread.run(PSurfaceNone.java:316)
対応方法
1 - SimpleOpenNIのソースをダウンロード
https://code.google.com/archive/p/simple-openni/source/default/source
2 - SimpleOpenNI.javaを修正
trunk/SimpleOpenNI-2.0/src/p5_src/SimpleOpenNI.javaの
parent.registerDispose(this) -> parent.registerMethod("dispose", this)
に置き換えます。
修正箇所は3箇所です。
3 - SimpleOpenNIMain.iのコメントを削除
trunk/SimpleOpenNI-2.0/src/SimpleOpenNIMain.iで#でコメントされている箇所を削除します。
#includeはコンパイルに必要なため、削除対象外とします。
「#+空白」を「//」に置換し、コメントアウトしました。
例)viで編集
%s/# /\/\//gc
4 - openNIをインストール
http://www.openni.org/downloadfiles/openni-binaries/20-latest-unstable
上記サイトよりopenNIをダウンロードし、任意のディレクトリに解凍しinstall.shを実行します。
/work/kinect/ディレクトリを作成し配置しました。
mkdir /work/kinect/ cd /work/kinect/ sudo ./install.sh
5 - NiTEをダウンロード
上記サイトよりNITEをダウンロードし、任意のディレクトリに解凍します。
/work/kinect/に配置しました。
6 - eigen3をインストール
MacPortでインストールしました。
sudo port install eigen3
7 - buildOsx.shを修正(その1)
trunk/SimpleOpenNI-2.0/buildOsx.sh記載の以下を変更します。
DOPEN_NI_BASE
openNIの配置先を指定
DOPEN_NI_LIBDIR
openNIのLibraryの配置先を指定
DNITE_BASE
NiTEの配置先を指定
DNITE_LIBRARY
NiTEのLibraryの配置先を指定
DEIGEN3D_INCLUDE
eigen3の配置先を指定
DP5_JAR
Processingのcore.jarの配置先を指定
DCMAKE_OSX_ARCHITECTURES
OSのビットを指定
私の環境では次のように修正しています。
echo "--- generate cmake ---"
cmake -DCMAKE_BUILD_TYPE=Release \
-DOPEN_NI_BASE=/Users/work/kinect/OpenNI-MacOSX-x64-2.2/ \
-DOPEN_NI_LIBDIR=/work/kinect/OpenNI-MacOSX-x64-2.2/Redisti/ \
-DNITE_BASE=/Users/work/kinect/NiTE-MacOSX-x64-2.2/ \
-DEIGEN3D_INCLUDE=/opt/local/include/eigen3/ \
-DP5_JAR=/work/.m2/repository/org/processing/core/3.1.1/core-3.1.1.jar \
-DCMAKE_OSX_ARCHITECTURES="x86_64" \
..
8 - buildOsx.shを修正(その2)
後述のjavadoc作成でエラーが発生するため、以下コメントアウトする。
# copy the doc #cp -r ./doc/* ../dist/all/SimpleOpenNI/documentation/
9 - buildOsx.shを修正(その3)
上記対応を行い、ビルドしたがSimpleOpenNI.jarが作成されずエラーとなったため
コンパイルしたクラスファイルをjarファイルで圧縮するコマンドを追加します。
追加したコマンド「jar cvf SimpleOpenNI.jar SimpleOpenNI/」
otool -L libSimpleOpenNI.jnilib echo "---create jar" jar cvf SimpleOpenNI.jar SimpleOpenNI/ echo "--- copy ---" # copy the library
10 - CMakeLists.txtを修正
次のように修正します。
ADD_CUSTOM_COMMAND(TARGET SimpleOpenNI
POST_BUILD
COMMAND cmake -E echo "-----------------------------"
COMMAND cmake -E echo "Compiling Java files..."
COMMAND cmake -E make_directory ./SimpleOpenNI
COMMAND cmake -E make_directory ${CMAKE_SWIG_OUTDIR}
#COMMAND cmake -E copy_directory ${P5_WRAPPER} ${CMAKE_SWIG_OUTDIR}
# cmake copy doesn't support wildcards, otherwise it just copies the hidden folder of svn, etc.
# doesn't works on windows backslash
COMMAND cp "${P5_WRAPPER}*.java" "${CMAKE_SWIG_OUTDIR}"
#COMMAND cmake -E copy ${P5_WRAPPER_FILE} ${CMAKE_SWIG_OUTDIR}
COMMAND ${JAVA_COMPILE2} -classpath ${P5_JAR} ${CMAKE_SWIG_OUTDIR}/*.java -d ./
)
#COMMAND cmake -E echo "-----------------------------"
#COMMAND cmake -E echo "Creating jar file..."
#COMMAND ${JAVA_ARCHIVE2} cvf SimpleOpenNI.jar SimpleOpenNI
#COMMAND cmake -E echo "-----------------------------"
#COMMAND cmake -E echo "Creating doc files..."
#COMMAND cmake -E make_directory ./doc
#COMMAND ${JAVA_DOC} -quiet -author -public -nodeprecated -nohelp -d ./doc -version ${P5_WRAPPER}/*.java -version ${CMAKE_SWIG_OUTDIR}/ContextWrapper.java
#COMMAND ${JAVA_DOC} -classpath ${P5_JAR} -quiet -author -public -nodeprecated -nohelp -d ./doc -version ${CMAKE_SWIG_OUTDIR}/*.java)
11 - ディレクトリを作成
trunk/SimpleOpenNI-2.0/に2つのディレクトリを作成
Redisti
lib
12 - ライブラリの配置
trunk/SimpleOpenNI-2.0/dist/all/SimpleOpenNI/library/osx/以下のファイルを全て
trunk/SimpleOpenNI-2.0/lib/
にコピーする。
13 - ビルド
trunk/SimpleOpenNI-2.0/buildOsx.shを実行すると
trunk/SimpleOpenNI-2.0/dist/all/SimpleOpenNI/libraryに
SimpleOpenNI.jar生成されます。
このSimpleOpenNI.jarに置き換えて使用する事でExceptionが回避されKinectを利用できるようになります。
./buildOsx.sh
補足
自分の環境では以下ライブラリを導入していなかったため
トライ&エラーで以下ライブラリをインストールしています。
1 - cmakeのインストール
sudo port install cmake
2 - Command Line Developer Toolsのインストール
terminalで以下コマンドを実行
xcode-select --install
3 - libtoolをインストール
sudo port install libtool
4 - libusbインストール
sudo port install libusb +universal
5 - pcreのインストール
https://sourceforge.net/projects/pcre/files/pcre/8.39/
./configure make sudo make install
pcre-config --version
7 - boostのインストール
sudo port install boost
音響解析[Processing]フーリエ変換->Sin波
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
API
OS
- Minim
- macOS sierra 10.12.2
ソフトウェア
次のソフトウェアでitunesなどの音源をオーディオ入力として扱うことができます
- LadioCast
https://itunes.apple.com/jp/app/ladiocast/id411213048?mt=12
- Soundflower
参考サイト、書籍
http://yoppa.org/cuc_proga11/2961.html
フーリエ変換の説明もあり、わかりやすかったです。
http://r-dimension.xsrv.jp/classes_j/frequency/
[特定の周波数に反応させる]の章で、Minimの具体的な利用方法を学べました。
概要
音声をフーリエ変換し、取得した周波数をサイン波で表示します。
フロー
1.オーディオ入力された音声をキャプチャ
2.フーリエ変換のFFTオブジェクトを生成
3.オーディオ入力された音声をフーリエ変換し、周波数情報をリストに格納
4.フーリエ変換の結果を棒グラフで表示
5.以下のカテゴリ毎に、最大音圧の周波数を取得
低域
中域
中高域
高域
全域
6.取得した最大音圧の周波数をSin波でそれぞれ表示
1.オーディオ入力された音声をキャプチャ
MinimのgetLineInメソッドでオーディオ入力された音声をキャプチャします。
後のフーリエ変換でより細かいブロックで周波数帯域を取得したいため、バッファサイズを4096に指定しています。
public void setup() {
//Minimの初期化
minim = new Minim(this);
//ステレオ,バッファサイズ4096でオーディオ入力音を取得するように指定
audioInput = minim.getLineIn(Minim.STEREO,4096);
2.フーリエ変換のFFTオブジェクトを作成
以下設定でFFTオブジェクトを生成します。
バッファサイズ :44100Hz
サンプリングレート :4096
上記設定により、ひとつひとつの周波数帯域は44100/4096の10.7666015625Hzとなります。
public void setup() {
//~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
//フーリエ変換のFFTオブジェクトを生成
fft = new FFT(audioInput.bufferSize(), audioInput.sampleRate());
//周波数帯域を出j力
for(int i = 0; i < fft.specSize(); i++)
{
println(i + " = " + fft.getBandWidth()*i + " ~ "+ fft.getBandWidth()*(i+1));
}
//窓関数にハミング窓を指定
fft.window(FFT.HAMMING);
コンソールの出力内容から、
10.7666015625Hz単位で周波数帯域のブロックが作成されていることが確認できます。
0 = 0.0 ~ 10.766602 1 = 10.766602 ~ 21.533203 2 = 21.533203 ~ 32.299805 3 = 32.299805 ~ 43.066406 //~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~ 2046 = 22028.467 ~ 22039.234 2047 = 22039.234 ~ 22050.0 2048 = 22050.0 ~ 22060.766
3.オーディオ入力された音声をフーリエ変換し、周波数情報をリストに格納
FFTクラスのforwardメソッドで解析を行い、
その結果を自前で作成したFFTSampleFrequencyクラスのリストに格納します。
public void draw() {
//~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
//オーディオ入力音をフーリエ変換
fft.forward(audioInput.mix);
sampleFrequencies = new ArrayList();
for(int i=0;i<fft.specSize();i++){
float hueColor = map(i, 0, fft.specSize(), 0, 180);
//周波数の情報をリストに格納
sampleFrequencies.add(new FFTSampleFrequency(
i,fft.getBandWidth()*i,fft.getBand(i),hueColor));
}
4.フーリエ変換の結果を棒グラフで表示
translateメソッドで画面下に移動し、画面の下から上に音圧に応じた長さのラインを描画します。
translate(0, height);
for (FFTSampleFrequency fftSampleFrequency : sampleFrequencies) {
float x = map(fftSampleFrequency.getNo(), 0,
sampleFrequencies.size(), 0, width);
stroke(fftSampleFrequency.getHueColor(),100,100);
strokeWeight(2);
println(fft.getBand(fftSampleFrequency.getNo()));
float high = map(fftSampleFrequency.getPressure(),
0.0F, 16.0F, 0, height/8);
line(x, 0,
x ,-high);
}

上段にサイン波を表示させるため、
グラフの高さは制限しています。
5.最大音圧の周波数を取得
周波数情報のリストより低域、中域、中高域、高域の周波数帯域で最大音圧の周波数を取得します。
| 周波数帯域 | 下限 | 上限 |
| 低域 | 0Hz | 300Hz |
| 中域 | 301Hz | 2000Hz |
| 中高域 | 2001Hz | 8000Hz |
| 高域 | 8001Hz | 22061Hz |
/**
* 指定したサンプリング周波数を抽出したリストを作成
* @param frequencies 周波数のリスト
* @param low 周波数の下限
* @param high 周波数の上限
* @return 指定した範囲の周波数リスト
*/
private List getRangeFrequencies(List frequencies,int low,int high) {
return
frequencies.stream()
.filter(sf -> sf.getFrequency() >= low)
.filter(sf -> sf.getFrequency() <= high)
.collect(toList());
}
/**
* 周波数のリストを降順でソートし、指定した要素の周波数を返す
* @param frequencies 周波数のリスト
* @param 取得したい要素のn番目
* @return 周波数情報
*/
private FFTSampleFrequency getFreq(List frequencies,int n) {
return
frequencies.stream()
.sorted(Comparator.comparingDouble(FFTSampleFrequency::getPressure).reversed())
.collect(toList())
.get(n)
;
}
6.取得した最大音圧の周波数をSin波でそれぞれ表示
//--------低域---------------------------
List lowFreqes =
getRangeFrequencies(sampleFrequencies, 0, 300);
FFTSampleFrequency freqLow = getFreq(lowFreqes, 1);
translate(0, height/8);
drawSine(width/4, freqLow,height/8);
/**
* サイン波を描画
* @param point 横幅
* @param freq 周波数
* @param maxAmp 振幅の最大
*/
private void drawSine(int point, FFTSampleFrequency freq,float maxAmp){
stroke(freq.getHueColor(),100,100);
beginShape();
int pointCount = point;
float angle;
for(int i=0;i<=pointCount;i++){
angle = map(i, 0, pointCount, 0, TWO_PI);
float y = sin(angle*freq.getFrequency()/440 + frameCount * 0.2F);
float amp = map(freq.getPressure(), 0.0F, 16.0F, 0, maxAmp);
amp = (amp > maxAmp)? maxAmp : amp;
y = y*amp;
vertex(i,y);
}
endShape();
}
コード
package music;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import static java.util.stream.Collectors.toList;
import ddf.minim.AudioInput;
import ddf.minim.Minim;
import ddf.minim.analysis.FFT;
import processing.core.PApplet;
public class FFTtoSine extends PApplet{
Minim minim;
//オーディオ入力
AudioInput audioInput;
//フーリエ変換
FFT fft;
//フーリエ変換したサンプル周波数情報
List sampleFrequencies;
//フーリエ変換のグラフ表示
boolean displayFFT = false;
//サイン波を表示
boolean displaySineWave = false;
public void settings() {
fullScreen();
//画面サイズを出力
println("fullWidth ::" + width);
println("fullHeight::" + height);
}
public void setup() {
//Minimの初期化
minim = new Minim(this);
//ステレオ,バッファサイズ4096でオーディオ入力音を取得するように指定
audioInput = minim.getLineIn(Minim.STEREO,4096);
//フーリエ変換のFFTオブジェクトを生成
fft = new FFT(audioInput.bufferSize(), audioInput.sampleRate());
//周波数帯域を出力
for(int i = 0; i < fft.specSize(); i++)
{
println(i + " = " + fft.getBandWidth()*i + " ~ "+ fft.getBandWidth()*(i+1));
}
//窓関数にハミング窓を指定
fft.window(FFT.HAMMING);
//HSBカラーモードを指定
colorMode(HSB,360,100,100,100);
}
public void draw() {
background(0);
stroke(255);
//オーディオ入力音をフーリエ変換
fft.forward(audioInput.mix);
sampleFrequencies = new ArrayList();
for(int i=0;i<fft.specSize();i++){
float hueColor = map(i, 0, fft.specSize(), 0, 180);
//周波数の情報をリストに格納
sampleFrequencies.add(new FFTSampleFrequency(
i,fft.getBandWidth()*i,fft.getBand(i),hueColor));
}
if(displayFFT){
translate(0, height);
for (FFTSampleFrequency fftSampleFrequency : sampleFrequencies) {
float x = map(fftSampleFrequency.getNo(), 0,
sampleFrequencies.size(), 0, width);
stroke(fftSampleFrequency.getHueColor(),100,100);
strokeWeight(2);
println(fft.getBand(fftSampleFrequency.getNo()));
float high = map(fftSampleFrequency.getPressure(),
0.0F, 16.0F, 0, height/8);
line(x, 0,
x ,-high);
}
}
if(displaySineWave){
resetMatrix();
fill(0);
stroke(255);
//--------低域---------------------------
List lowFreqes =
getRangeFrequencies(sampleFrequencies, 0, 300);
FFTSampleFrequency freqLow = getFreq(lowFreqes, 1);
translate(0, height/8);
drawSine(width/4, freqLow,height/8);
//--------中域---------------------------
List midFreqes =
getRangeFrequencies(sampleFrequencies, 301, 2000);
FFTSampleFrequency freqMid = getFreq(midFreqes, 1);
translate(width/4, 0);
drawSine(width/4, freqMid,height/8);
//--------中高域--------------------------
List midHighFreqes =
getRangeFrequencies(sampleFrequencies, 2001, 8000);
FFTSampleFrequency freqMidHigh = getFreq(midHighFreqes, 1);
translate(width/4, 0);
drawSine(width/4, freqMidHigh,height/8);
//--------高域----------------------------
List highFreqes =
getRangeFrequencies(sampleFrequencies, 8001, 22061);
FFTSampleFrequency freqHigh = getFreq(highFreqes, 1);
translate(width/4, 0);
drawSine(width/4, freqHigh,height/8);
//--------全域----------------------------
FFTSampleFrequency freqAll = getFreq(sampleFrequencies, 1);
resetMatrix();
translate(0, height/2);
drawSine(width, freqAll,height/4);
}
//リストに格納した周波数情報をクリア
sampleFrequencies.clear();
}
/**
* 指定したサンプリング周波数を抽出したリストを作成
* @param frequencies 周波数のリスト
* @param low 周波数の下限
* @param high 周波数の上限
* @return 指定した範囲の周波数リスト
*/
private List getRangeFrequencies(List frequencies,int low,int high) {
return
frequencies.stream()
.filter(sf -> sf.getFrequency() >= low)
.filter(sf -> sf.getFrequency() <= high)
.collect(toList());
}
/**
* 周波数のリストを降順でソートし、指定した要素の周波数を返す
* @param frequencies 周波数のリスト
* @param 取得したい要素のn番目
* @return 周波数情報
*/
private FFTSampleFrequency getFreq(List frequencies,int n) {
return
frequencies.stream()
.sorted(Comparator.comparingDouble(FFTSampleFrequency::getPressure).reversed())
.collect(toList())
.get(n)
;
}
/**
* サイン波を描画
* @param point 横幅
* @param freq 周波数
* @param maxAmp 振幅の最大
*/
private void drawSine(int point, FFTSampleFrequency freq,float maxAmp){
stroke(freq.getHueColor(),100,100);
beginShape();
int pointCount = point;
float angle;
for(int i=0;i<=pointCount;i++){
angle = map(i, 0, pointCount, 0, TWO_PI);
float y = sin(angle*freq.getFrequency()/440 + frameCount * 0.2F);
float amp = map(freq.getPressure(), 0.0F, 16.0F, 0, maxAmp);
amp = (amp > maxAmp)? maxAmp : amp;
y = y*amp;
vertex(i,y);
}
endShape();
}
public void stop() {
//Minimを停止
minim.stop();
super.stop();
}
public void keyReleased() {
if(key == 'f' || key == 'F'){
displayFFT = !displayFFT;
}
if(key == 's' || key == 'S'){
displaySineWave = !displaySineWave;
}
}
public static void main(String[] args) {
PApplet.main(music.FFTtoSine.class.getName());
}
}
package music;
public class FFTSampleFrequency {
private int no;
private float frequency;
private float pressure;
private float hueColor;
public FFTSampleFrequency(int _no,float _frequncy,float _pressure,float _hueColor) {
no = _no;
frequency = _frequncy;
pressure = _pressure;
hueColor = _hueColor;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
@Override
public String toString() {
return "No" + no + "freq:" + frequency + "\r\n" + "press:" + pressure;
}
public float getHueColor() {
return hueColor;
}
public void setHueColor(float hueColor) {
this.hueColor = hueColor;
}
public float getFrequency() {
return frequency;
}
public void setFrequency(float frequency) {
this.frequency = frequency;
}
public float getPressure() {
return pressure;
}
public void setPressure(float pressure) {
this.pressure = pressure;
}
}
エクセルが開かない
’XXXXX(ファイル名)’には読み取れない内容が含まれています。このブックの内容を回復しますか?ブックの発行元が信頼できる場合は「はい」をクリックしてください。
’XXXXX(ファイル名)’には読み取れない内容が含まれています。このブックの内容を回復しますか?ブックの発行元が信頼できる場合は「はい」をクリックしてください。
↓
「はい」をクリック
↓
読み取れなかった内容を修復または削除することによりファイルを開くことができました。
↓
修復されたレコード: /xl/drawings/drawing1.xml パーツ内のスケッチ (図形描画)
↓
クリックすると修復のログファイルが表示されます。
↓
<?xml version="1.0" encoding="UTF-8" standalone="true"?>
-<recoveryLog xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
<logFileName>error057160_01.xml</logFileName>
<summary>ファイル 'C:\Users\Owner\Documents\sample.xlsx' にエラーが検出されました
</summary>-<repairedRecords summary="修復の一覧:">
<repairedRecord>修復されたレコード: /xl/drawings/drawing1.xml パーツ内のスケッチ (図形描画)</repairedRecord>
</repairedRecords>
</recoveryLog>
線とか図とか消えてしまった。。。回復してないじゃん
ブックの内容を回復しない限り、壊れたエクセルは開きません。
でも、上記のようにdrawing1.xmlなるファイルを削除し回復されます。
drawing1.xmlには描画情報が記録されています。
これを削除するということは、描画全てを消して回復するということなんです。
壊れた部分を部分的に直す方法はないのでしょうか?
とまぁ、直せないのが仕様ですって。
具体的にいえば、図形描画はdrawing1.xmlに登録されているが、回復方法は、そのファイルを消すという方式なので、すべての描画が消えてしまうのですね。
じゃあ機能に頼らず、自力で直すしかない!
①/xl/drawings/drawing1.xmlってのを編集できる状態にする
ExcelはXML形式のファイルがZIP化されたものなので、複合化ツール(7-Zip)を使って、ZIPを解凍します。
②drawing1.xmlから壊れたところを見つける
Excelがここがおかしいって表示かログでも出してくれるといいのですが、不親切で出力されません。
自力で見つけるしかありません。
Excelを解凍して、drawing1.xmlを取り出します。
drawing1.xmlを高度エディタ(サクラエディタ等)で開きます。
→改行とかないので見難い。。。ブラウザで開くとわかり易いが、編集できない。。。ということで、見難いですがエディタで開く
drawing1.xmlは以下のような形式で記載されています。(・・・は割愛個所)
<?xml version= ・・・・ ?><xdr;wsDr xmlns:xdr="http://・・・・・ 2006/main"><xdr:twoCellAnchor>・・・</xdr:twoCellAncor></xdr:wsDr>
1つ1つの描画が<xdr:twoCellAnchor>・・・</xdr:twoCellAncor>で囲ってある。
これを一つずつ消していき、zipに戻し、excelで開くを繰り返しエラーの有無で壊れている場所が判断できる。
③壊れた個所のみ取り除く
壊れている<xdr:twoCellAnchor>・・・</xdr:twoCellAncor>部分を取り除けば、目的通り、問題個所だけを排除した形で復旧可能です。
クロスサイトスクリプティング
クロスサイトスクリプティングって
クロスサイトスクリプティング(XSS)ってよく聞きますが、実際どういうものなのかを体験してみようと思い試してみました。
実際にXSSを利用してサイトの脆弱性を理解すると、WEBサイトを作る時に気をつけようと思うようになりますね。
XSS攻撃とは、攻撃者の作成したスクリプトを脆弱性のある標的サイトのドメインの権限において閲覧者のブラウザで実行させる攻撃です。
サイトの脆弱性をついて、スクリプトを実行させ、情報を盗んだり、コピーサイトに誘導したりできます。
体験してみよう
JavaScriptでデータオブジェクト風に
JavaScriptで変数といえば「var」ですが、使用する変数が増えてくると取り扱いが面倒になってきます。
配列などで管理する方法もありますが、一長一短あるかと思います。
そこで、上手い方法はないかと模索していて辿り着いたのが、データオブジェクト風に扱う方法でした。
早速、例として、「名前」、「生年月日」、「年齢」という属性を持つ「人物」というデータオブジェクトを定義してみます。
/** 人物 */
function Person() {
/** 名前 */
var name = "";
/** 生年月日 */
var birthday = "";
/** 年齢 */
var age = 0;
/** 名前を設定する。 */
this.setName = function (_name) {
name = _name;
}
/** 名前を返却する。 */
this.getName = function () {
return name;
}
/** 生年月日を設定する。 */
this.setBirthday = function (_birthday) {
birthday = _birthday;
}
/** 生年月日を返却する。 */
this.getBirthday = function () {
return birthday;
}
/** 年齢を設定する。 */
this.setAge = function (_age) {
age = _age;
}
/** 年齢を返却する。 */
this.getAge = function () {
return age;
}
}
|
prototypeを使って記述していく方法などもあるかと思いますが、本職がJavaなので、
慣れた手触りで使えたら楽ちんだなあという要求から、私は今回の方法に落ち着きました。
setter/getterを介して内部変数にアクセスする、一般的なデータオブジェクトです。
使う時は以下のように。
var person1 = new Person();
person1.setName("山田 太郎");
person1.setBirthday("03/01");
person1.setAge(30);
var person2 = new Person();
person2.setName("山田 一");
person2.setBirthday("08/06");
person2.setAge(8);
person1.getAge(); // 30
person2.getBirthday(); // 08/06
person1.getName(); // 山田 太郎
|
関数にパラメータとして渡すことも出来ますし、
/** 加齢 */
function AddAge(person) {
person.setAge(person.getAge() + 1);
}
AddAge(person2);
AddAge(person2);
person2.getAge(); // 10
|
なので、こういった使い方も出来ます。
/** 家族 */ function Family() { /** 父 */ var father = null; /** 母 */ var mother = null; /** 子供 */ var child = null; /** 父を設定する。 */ this.setFather = function (_father) { father = _father; } /** 父を返却する。 */ this.getFather = function () { return father; } /** 母を設定する。 */ this.setMother = function (_mother) { mother = _mother; } /** 母を返却する。 */ this.getMother = function () { return mother; } /** 子供を設定する。 */ this.setChild = function (_child) { child = _child; } |
「父」、「母」、「子供」という「人物」型の属性を持つ「家族」というデータオブジェクトを作りました。
var yamada = new Family();
yamada.setFather(person1);
yamada.setChild(person2);
yamada.getFather().getBirthday(); // 03/01
yamada.getChild().getName(); // 山田 一
|
クラスを継承して新しいクラスを作ることも出来ます。例えば、「家族」に「弟」を追加します。
/** 弟のいる家族 */
function BigFamily() {
Family.call(this);
/** 弟 */
var brother = null;
/** 弟を設定する。 */
this.setBrother = function (_brother) {
brother = _brother;
}
/** 弟を返却する。 */
this.getBrother = function () {
return brother;
}
}
var tanaka = new BigFamily();
var person3 = new Person();
person3.setName("田中 花子");
person3.setBirthday("04/04");
person3.setAge(29);
var person4 = new Person();
person4.setName("田中 次郎");
person4.setBirthday("12/23");
person4.setAge(6);
tanaka.setMother(person3);
tanaka.setBrother(person4);
tanaka.getMother().getName(); // 田中 花子
tanaka.getBrother().getName(); // 田中 次郎
|
Javaと違って変数の型の扱いが緩いので、取り扱いには注意しなければいけないのが難点でしょうか。
特に、パラメータで渡す場合など、コンパイルエラー等を出してくれる訳ではないので、
実際に実行される段になってようやくエラーで止まる…ということがよくあります。
パラメータで渡ってきたオブジェクトの型チェックを行いたい場合は、typeofやprototypeを用いて
型を確認するのが良いようです。
// 標準的なオブジェクトの場合はtypeofで
typeof(person3.getName()) == 'string'; // true
typeof(person3.getAge()) == 'string'; // false
typeof(person3.getAge()) == 'number'; // true
// 今回作ったようなオブジェクトはprototypeで
Person.prototype.isPrototypeOf(person3); // true
Person.prototype.isPrototypeOf(tanaka); // false
BigFamily.prototype.isPrototypeOf(tanaka); // true
|
作り込みバグには気をつけなければいけませんね。
Firewall/IPS/WAFの防御対象の違い
会社のWEBサイトのサイバー攻撃対策はどのようにしていますか?
そう聞いてもサーバー管理会社に任せているって回答になりますよね。
サーバー管理会社はどのようにWEBサイトを守ってくれているのかまでは知らないことが多いと思います。
サーバーのセキュリティって皆さんのイメージはどのようなものでしょうか?
Firewall(ファイヤーウォール)をイメージされますよね。
OSに詳しい方なら、Firewall製品などアプライアンスやOSのIPセキュリティ、Windows Firewall、Linux Firewallなどを思い浮かべると思います。
ネットワークに詳しい方ならば、IPS、IDSといったものも思いつくかもしれませんね。
現在の日本におけるサーバー環境のセキュリティの大半はFirewall、より強固なところでIPSが導入されているといった状況です。
しかし、昨今のサイバー攻撃は多様化しており、これらの対策だけでは不十分になってきています。
ところが、日本企業において、セキュリティ強化はコスト増大と考えられ、上記のような対策にとどまっているのが現状です。
注目すべきは、昨今のサイバー攻撃はFirewallやIPSでは防げないSQLインジェクション攻撃、XSS、ランサムウェアが増えているということです。
これらを防ぐにはアプリケーションで対策をせねばならず、しかし対応がおいつかない、コストがかかるなどで対応が後手になっています。
そこで最近注目なのがWAF(Web Application Firewall)を用いたセキュリティ対策です。

Firewall
防御対象:ネットワーク
L4レイヤレベルで通信元、通信先の組み合わせで防御するもの。
通信における送信元情報と宛先情報(IPアドレス・プロトコルTCP/UDP等・ポート番号)を基にアクセス制御をおこなう。
IPS(Intrusion Prevention System)/ IDS(Intrusion Detection System)
防御対象:サーバーシステム
攻撃パターン(シグネチャ)に一致する通信をみつけて防御するもの。
OSの脆弱性を悪用する攻撃やファイル共有サービスへの攻撃を防御。
Active-Xを悪用したり、WEBサーバーの脆弱性を悪用する攻撃を防御。
IDSは検知し通知するまでの機能をもつもので、防御はおこなわない。
WAF(WEB Application Firewall)
防御対象:WEBアプリケーション
HTTP/HTTPSプロトコルの通信をL7レイヤレベルで防衛するもの。
SQLインジェクション、クロスサイトスクリプティング(XSS)などWEBアプリケーションへの攻撃を防御。
WEBアプリケーションのパラメータを悪用する攻撃を防御。
cookieを悪用する攻撃を防御。
サイバー攻撃されてからでは遅い
WAFはWEBアプリケーションに特化したL7レイヤーの防衛方法です。
WAF は、ウェブアプリケーションの脆弱性を悪用した攻撃などからウェブアプリケーションを 保護するソフトウェア、またはハードウェアです。
WAF は脆弱性を修正するといったウェブアプ リケーションの実装面での根本的な対策ではなく、攻撃による影響を低減する対策です。
WAF は、WAF を導入したウェブサイト運営者が設定する検出パターンに基づいて、ウェブサ イトと利用者間の通信の中身を機械的に検査することでサイバー攻撃を防ぎます。
サイバー攻撃を受けてからアプリケーションを対策修正していては、時間がかかります。
その間にシステムは利用できなくなり、攻撃もやみません。
WAFを導入しておけば、素早く対策が取れるというメリットがあります。
IPAからも紹介されていますので一度ご覧ください。
導入・運用コストが普及を妨げる
サイバー攻撃の対策はネットワーク技術者、サーバー技術者が主に対応しますが、
WAFはFirewallやIPSとは異なりネットワーク・サーバー技術者だけでは運用できません。
WEBアプリケーションへの攻撃を防ぐという特徴からWEBアプリケーションの開発者の協力が不可欠です。
対策をするWEBアプリケーションの特徴に合わせて防衛シグネチャを構築する必要があるためです。
アプリケーションは頻繁に更新されますから、都度シグネチャの見直しが発生します。
そのため、WAFを導入したら終わりというものではなく、導入してからの運用コストも考えなければなりません。
このことが普及を妨げている理由だと考えています。
CSS3でできるレスポンシブデザイン
プログラミング初心者がWEB画面を作らないといけなくなった状況で
CSSとはなんぞやにぶち当たったのが前回の記事”CSSとは?初心者は何を考える”でしたが、
今回は実際にデザイン通りに作っていくタイミングで検索検索した結果、これは便利そうと思った内容をご紹介。
前回の記事では、CSSとCSS3の違いに触れていましたが、
大きな違いはなく、バージョンが上がることでできること増えたよという内容でした。
そのCSS3でできることの一つに、
HTMLの記述順に関係なく自由に表示順を変更できるCSS
という情報を見つけました。
そもそもHTMLも初心者だったので、HTMLの順番で表示するというなんとなくの理解と
hidden使ってscriptで画面表示切替はできるなっていうアイデアしか頭になかった。。。。
最近はスマホの普及でレスポンシブデザインを知らぬ間に目にしていて
今回のWEB画面の用途はPCのみなので、特にこのレスポンシブデザインを組み込む予定は無いけれど
これできたら、自由自在だなあ。しかも簡単にできそうだなあ。ってなったので
ブックマークに追加して個人メモにしておいた。
flexbox(フレキシブルボックス)を追加するだけでできちゃうレスポンシブデザイン。
具体的な書き方はコチラ↓
CSS3のflexbox(フレキシブルボックス)の簡単な書き方
CSSとは?初心者は何を考える
WEBページを作成する上で理解が必要なCSSだが、そもそもCSSって何なの???
という状態の解消から、これ便利なんじゃない?にいたるまで
どんなページをみて、どんな理解をしたのかをずらずらずらとメモしていこうかなと。
まずは、CSSとは?というところからのスタート!
単純に検索するとこのページにたどり着く↓
http://www.htmq.com/csskihon/001.shtml
でもこれだとCSS単品の説明が黒い文字で、、、、、、、
初心者の私はそもそもイメージが沸かないと頭に入ってこない場合が多数。←単純に文章が苦手
検索→説明文ヒット→いまいちイメージつかない→そもそも全体像は?(全体の中の役割は?)
と実際なっていたので次に検索して理解しやすかったのはコチラ↓
http://www.cyber-concierge.co.jp/pc_tama/css/css.html
これをみると、なるほどそうか、それぞれが役割もってがんばって表示させているんだなとなんとなく理解。
HTML:WEBページの枠組みとか構造
CSS:色とか文字の大きさとか装飾

Javascript:クリックしたらどうとか
複雑な動き
ここまでくると、じゃあようやくCSSのできることできないこと云々かんぬんに進める状態。
じゃあ、WEBページを装飾していく中でCSSでできることは何だろう???
CSSでできることリスト↓
http://www.htmq.com/style/index.shtml
CSS3でできることリスト↓
http://www.htmq.com/css3/index.shtml
ここで出てきたCSSとCSS3。
初心者を悩ませるこのバージョンの違いは何なんだ、、、
という疑問を抱いてしまい、やっぱり検索。
https://allabout.co.jp/gm/gc/376450/
大きく3つの点で説明があった!
①従来の記述と混在が可能 (=書き直す必要がない)
②HTML5とセットではない
③今すぐ使える
ふむ。①と③から分かることはCSSとCSS3は別物という考え方ではなく、追加でできること増えましたっていうことですね。
(②についてはまた話が膨らむのでまた別記事で)
ってことは!
基礎を学ぼうと思えば、CSSで検索ヒットした内容をみていけばよいとすっきりしました。
初心者ってどの情報が正しいかの判断がまずつかないのが勉強方法難しいところだなあ。
CSSの基礎ってなんだろう?
まずは書き方かな。文法とそれぞれの意味を知らなくては読み解けないから、、、
http://www.d3.dion.ne.jp/~tiyoko01/style/style3.html
セレクタと属性と属性値なるものを書けばよい。
つまりは装飾する範囲と範囲のどの部分をどうするかを書けばよい。
これで大体読み解けそうだなってとこまでこれました。
ここで出てくる願望、、
実際に反映させてみたい。
そのほうが手っ取り早い!
ということで、どうやってHTMLのベースのところにCSSの装飾を反映させるの?ってなるんだけれども
反映のさせ方は種類があるようなのでまた検索。
http://qiita.com/kikako/items/580039de452de909d82d
3種類かあ~。
それぞれにメリデメがあるみたいだけれどそれはまあ追々。
今回はhtmlファイル1つとCSSファイル1つ作成して、htmlファイルに外部ファイルとしてCSSファイルを読み込ませる。
【HTMLファイル】
まずはメモ帳ひらいて、ファイル名.html として文字コードをUTF-8にして保存。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>サンプル1</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>背景を青</h1>
</body>
</html>
【CSSファイル】
次に新しくメモ帳をひらいて、htmlファイルで読み込ませたファイル名と同じ名前(style.css)のCSSファイルを作成して保存。
@charset "utf-8";
h1{
background-color: royalblue;
}

保存したhtmlファイルをクリックして実行すれば、CSSファイルの内容が反映された
背景の色が青い文字が登場します。
ここまででCSSについての理解は大体できました!
あとはどんなことできるのかなあ~~~~~
ってわくわくしながら調べてサンプル作っての楽しい時間です。
初心者の小ネタ情報↓
CSS3でできるレスポンシブデザイン
キャッシュをクリアせずにcssやjsファイルの変更を反映させる
とあるシステムのWEB画面を改修していたときのこと。
使っていたのはjavaのeclipseで、既存システムのjsファイルに新規システムの内容を追記して反映させようとした。
ところがどっこい、いざWEB画面を更新してみてもなんにも変化がない、反映されていない。
eclipseでソースをクリーンしてみたりしてみたものの、やはり変化がない。
これはなんだろう、見てるjsファイルはこいつじゃないのか?などと、んーんー唸って時間が過ぎていた。
まぁ、一人で唸っていても埒が明かないので人に聞いてみたところ、更新前のキャッシュが残っていてそのキャッシュを利用しているから変更が反映されていない、ということだった。
と言うことでひとまずの解決案として、ブラウザのキャッシュをクリアすることに。
それによってめでたくjsファイルの変更は反映されましたとさ、終わり!!
ってタイトル回収できてないよ!!
ブラウザのキャッシュをクリアしたら、変更したjsファイルが反映される。
でもいちいちそんなことしてたら面倒くさいよね、キャッシュを有効にしつつも変更したファイルを反映させる方法があるらしいよ!
やったことないけどね!!
と、私に教えてくれた人は言いました。
なるほど、これは調べてみるしかあるまいて。
本題の前に
そもそもキャッシュってなんだっけ?
こういう調べものをするたびに、ところどころに「これなんだっけ?」っていうのがある。
今回で言うと、キャッシュ。なんとなーくわかるんだけど、どういうものだっけ?ってなる。
以下、キャッシュに対する自分的解釈。
キャッシュとは、データへのアクセスを速くするために記憶領域にデータを一時的に保存しておくもの。
つまり、よく使うデータなどをキャッシュに保存しておくことでアクセスしたときに、
新たにデータを作成してという順序が必要なくなるので、その分だけ処理を速くすることができる。
今回の場合は、変更する前のjsファイルデータがキャッシュに保存されていて、
そのデータを使用して処理を行っていたために、変更したjsファイルデータが反映されていない状態となっていた。
つまり、普段のネットサーフィン時にはストレス無くページを表示する助けになるキャッシュだけれど、
開発をする際にはそのキャッシュが邪魔になってしまうということ。
そういうことで合っている、はず!
対象ファイルのみ修正する
そんなこんなで本題です。
調べてみたところ、変更したjavaファイルに変更日付を自動的に取得させてしまうという方法があった。
この仕掛けをjavaで作ってしまえばいいんですね?
ファイルの変更日付が変更されれば、パラメータも同時に変更されるというもの。
以下のjavaソースが、参考にさせてもらったサイトにあったものです。
public class Util {
/** 最終更新日時取得用書式定義 */
private static SimpleDateFormat timestampFormat = new SimpleDateFormat("yyyyMMddhhmmss");
/**
* ファイルの最終更新日時を返す
* @param path 対象となるファイル
* @return 最終更新日時(yyyyMMddhhmmss)
*/
public static String
getLastModified(String path) {
File file = new File(path);
Long lastModified = file.lastModified();
return timestampFormat.format(lastModified);
}
}
|
そして、読み込み側のjspを以下のようにする。
<link href="css/style.css?date='<%= Util.getLastModified(config.getServletContext().getRealPath("css/style.css")) %>'" rel="stylesheet">
これで、変更したファイルの日付が変わるとパラメーターも同様に変わるので、確実にファイルの変更が反映されることになる。
ということが出来るようなので、JSPやjavaで開発しているときには利用してみるとストレスがなくなると思う。
cssやjsファイルを変更する度にキャッシュのクリアなんてしていたら面倒ですもんね。
以下、参考にさせて頂いたサイト様。
2フェーズコミット
■トランザクションの概念
データベースの更新処理としては INSERT文や UPDATE文、DELETE文などがあるが
複数の更新処理を連続して実行し、1つの関連性のある集まりとして簡易する場合、
トランザクションという概念が必要になる。
■トランザクションが必要になるケース

例えば商品を10個注文を受けたので在庫から商品を10個減らす場合、
注文テーブルに商品数を登録し、在庫テーブルから商品数を減らす。
もしトランザクションを使わずこの処理を続けて実行し、在庫から商
品を減らす処理に失敗した場合、注文数は登録した一方、在庫から商
品数が減らずデータ(商品個数)に不一致が発生する。
このようなケースではトランザクションを使うと問題を解決すること
ができる。上の例では注文と在庫の管理を1つのトランザクションと
してまとめ全ての更新に成功した場合のみ、商品の注文/在庫の個数
を確定する。もし処理が途中で失敗した場合、全ての処理が取り消さ
れる。このため商品在庫数に変動はなく、データの整合性が保たれる。
これらはACID特性と呼ばれるトランザクション処理の信頼性を保証
する性質である。
■分散トランザクションの問題
分散トランザクションとは1つのトランザクションが複数のデータベース
に対してアクセスするトランザクションのことである。先のケースのよう
なトランザクション機能では複数のデータベースに対してアクセスする場
合、図Aのように原始性を損なう問題があった。データベースBに対して
コミットが成功し、データベースCに対してコミットが失敗した場合、
データベースCに対してロールバックを実行してもデータベースBに対す
る変更までもロールバックできない事態が考えられる。

■分散トランザクション(2フェーズコミット)
先の分散トランザクションの問題を解決するのが図Bに示す2フェーズコミットである。

フェーズ1では各データベースに対してコミット可能か状態を確認する準備の指示を送る。
これを受けたデータベースはコミット可否をアプリケーションに伝える。コミットできる
状態であればアプリケーションに「準備完了」を伝える。もしコミットできない状態で
あればアプリケーションに対して「拒否」を伝える。
フェーズ2では、フェーズ1の各データベースの返答をもとにデータベースに対して
コミットかロールバックの決定を行う。
全てのデーターベースから「準備完了」の返答を受け取った場合のみ、各データベース
に対してコミットの指示を送る。この指示によってトランザクションがコミットされる。
しかし1つでも「拒否」の返答があった場合、全てのデータベースに対してロールバック
の指示を送る。
このように2フェーズコミットはコミットのための準備とコミット処理を行う実行を
分けることによってトランザクションの原始性を保証している。
■トランザクションマネージャ
先に説明した分散トランザクションを実行するにあたってアプリケーションからトランザ
クションの制御を切り離し別のコンポーネントに任せたトランザクションマネージャと呼
ばれるものを照会する。

トランザクションマネージャの導入により、アプリケーションから2フェーズコミットの処理が
隠ぺいされたことにより、分散トランザクションを単一のデータベースにおけるトランザクショ
ン処理と同様な手順でコミットできるようになる。
■X/OPENのDTPモデル
複数のデーターベースを利用する場合、そのインターフェースが統一されていないと連携が
とれない。X/OPENの分散トランザクションは、分散トランザクションに関するインター
フェースを標準化することでこの問題を解決することができる。

●アプリケーション
システム利用者が高級言語で作成するプログラムのこと。
●トランザクションマネージャ
トランザクションを管理し、データベースの更新情報をもとに一貫性を保守する。
●リソースマネージャ
データベースのこと。
■TXインターフェース
アプリケーションからトランザクションマネージャへトランザクションの開始/終了を指示する。
■XAインターフェース
トランザクションマネージャとリソースマネージャでデータベースの更新情報の同期をとる。
■SQL
データベースを操作するSQLのこと。
- おわり -
フォルダ削除処理は本当に注意が必要!
C++でWindowsのファイル操作を行うとき、意外と困るのが「フォルダの削除」です。
まず、Windowsの一番基本的なAPIから、以下の機能を組み合わせて使用します。
- 指定フォルダ内のフォルダ、ファイルを1つずつ取り出す(FindFile()、FindNextFile())
- ファイルを削除する(DeleteFile())
- "空の"フォルダを削除する(RemoveDirectory())
ここで重要なのは、フォルダ削除に使用するAPIが、"空の"フォルダしか扱えないということです。
そこで、基本的なプログラミングの技術である再帰呼び出しがわかっている人は、
「フォルダの中にある全てのファイルを削除してから親フォルダを削除する」ということは
すぐに思いつくでしょう。
フォルダ削除()という関数にして、中にある要素がファイルなら削除、フォルダならそのフォルダパスを引数にしてフォルダ削除()と呼ぶだけです。
あとちょっと面倒くさそうなのは、「指定フォルダ内のフォルダ、ファイルを1つずつ取り出す」
という部分だと思います。FindFile()の引数にフォルダパスをそのまま渡してもファイルを列挙してくれません。
"\\*.*"というワイルドカードをフォルダパスの後ろに付けることで、そのフォルダ内の全ファイルを列挙してくれるようになります。
ここまでの部分を理解したうえで、「こういうパターン化された処理は、誰かがソースコードを公開しているだろう」と
検索をするのはよくあることではないでしょうか。そして、そのほうが自分でひとつずつコーディングするよりも
はるかに速くできるということを、経験している人も多いと思います。
そこで、Googleで「C++ フォルダ削除」と検索すると、そのようなことをしているソースコードが
すぐに見つかります。
ただし、ここで見つかったソースコードを手元でそのまま使用しては、絶対にいけません。
呼び出し元のプログラムがしっかりと作られているときは、いらないフォルダを削除するために
このフォルダ削除処理を呼び出し、問題なく指定したフォルダの削除に成功するでしょう。
しかし、プログラムの開発段階において、そういつも正しく実行できるとは限りません。
もし、このフォルダ削除呼び出しの引数に「空文字」を指定したらどうなるでしょうか?
フォルダの削除を目的とする処理なのに引数にフォルダパスになる文字列が来なければ
何もせずに処理を終わればいいと思うのですが、検索して見つかるソースコードにそのような
チェック処理はほとんど入っていません。
FindFile()の引数が"\\*.*"だけとなるのですが、これはどこかのフォルダ内ではなく、
ドライブの最上位パスから検索を開始するという動作になります。
というわけで、単にフォルダ削除処理の呼び出しをミスしただけのことが、
ドライブ内全ファイル削除という暴走処理になってしまうことがあるのでした。
私ではないのですが、これをやらかしたメンバーは、動作確認中に応答待ちになって待っていて
「なんとなくファイルが減っていっている気がする」と言い出して気づいたときには
数割のファイルが消えた後だったということです。
みなさん本当に気をつけましょう。
WPFに触れてみる
はじめに
プログラムに関わりはじめてから2年ぐらい経つ。しかし、画面があるプログラムに関わったことは一度もない。
画面があるプログラムについて知りたい。C#の知識が主なので、C#で作成したい。
そこで、WPFについて学んでみようと思った。
目標
・WPFの概要を知る。
WPFとは何か?
WPF(Windows Presentation Foundation)は.NET Framework 3.0以降に含まれるプレゼンテーション層技術(GUI開発ライブラリ)。
◆特徴
・コアの部分にグラフィックス・ハードウェア(GPU)を活用したベクター・ベースのレンダリング・エンジンを採用。
→ベクタ形式で画像処理を行う。拡大縮小や画像サイズが見た目の大きさに依存しない。
・ボタンやリストボックスなどのコントロール、ラスター画像やベクター・グラフィックス、頂点メッシュを用いた3D描画、
動画などのメディア、リッチテキスト(RTF)などの整形済み文書に対して、統一的な開発機能を提供。
→とにかく幅広く対応できる。
・XAML(Extensible Application Markup Language)と呼ばれる、XML形式の宣言的言語を用いて
ユーザー・インターフェイスを記述する。
→見た目(=外観デザイン)に関する部分をXAML言語で記述し、ロジックをC#言語などを用いて記述することで、
アプリケーションの見た目に関する部分をロジックから完全に切り離す構造になっている。
◆プログラミング・モデル
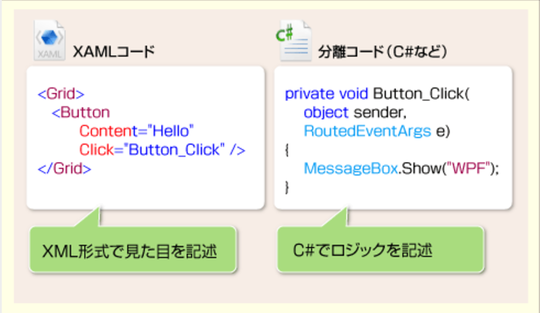
・XAMLコード+分離コード
<利点>
・外観デザインが容易
・階層構造を把握しやすい
<メモ>
画面レイアウトで、ボタンとかをドラッグ&ドロップで置いたら、XAMLコードが自動生成される。
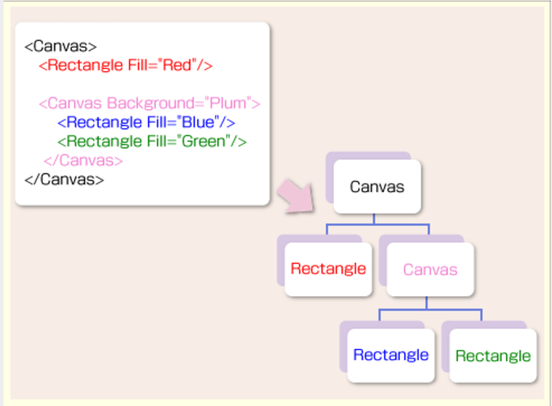
・ツリー構造のUI要素
<利点>
・要素の親子関係によって柔軟に変更可能
<メモ>
例えば、親要素が回転したら、子要素も回転する(親の位置に依存する)ということらしい。
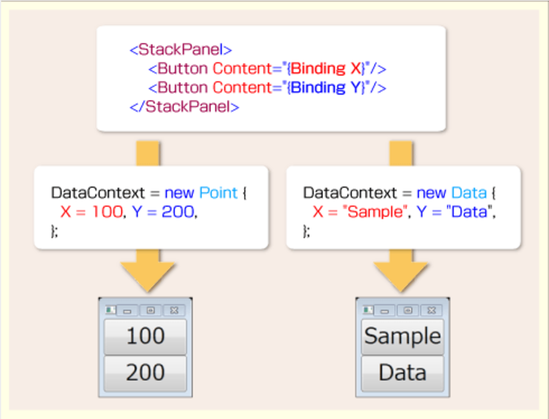
・データ・バインディング
(ビューとモデルを分離するための仕組み)
<利点>
・ビューとモデルの接点が1点(DataContext)で済む
・ビューの内部には一切ロジックを持つ必要がない
<メモ>
例えば、画面の色変えたいときに、内部ロジックで色を使用していたら、画面とロジックの両方で修正が必要になってしまう。
→拡張性低い、保守性低い
DataContextはobject型でなんでも入るらしい。
なぜWPFか?
少し話が変わるが、C#で画面といえばWindows Formsを思いつくと思う。
ではなぜ、Windows FormsではなくWPFを選んだのか?
両者を簡単に比較してみる。
| Windows Forms | WPF | |
| 実行環境 | 旧いOSや旧い.NET Frameworkでも動作 | NET Framework3.0以降 |
| レンダリング | ラスタ形式 | ベクタ形式 |
| 機能 | カスタマイズが困難 |
カスタマイズが容易 タッチパネル対応 |
カスタマイズが容易に越したことはないので、やはり、WPFの特徴でもあるバインディング機能が、魅力的にみえる。
しかし、初心者で画面を作成するなら、なんとなく馴染みがあるWindows Formsのほうがよいとも思っていた。
(書籍などもたくさんあるので)
ところが、、
Windows Formsは
・バグが放置されている
・公式のサポートがほぼ終わっている
・WPF, Silverlight, Windows 8 ストアアプリ(Windowsストアアプリ), UPWなどが全部XAMLを使っている
ということがわかってきたので、今後のことを踏まえWPFを選択した。
MVVMとは?
話を戻す。
WPFの特徴がなんとなく掴めたところで、ビュー、モデルといった単語が出てきた。
プログラムの構成を、ビューやモデルとして分けて考えることが大事なようだ。
プログラムの構成モデルにはMVC,MVVMなどがあるが、WPFは、MVVMを基本とする。
では、MVVMとは何か?
・MVVM(Model-View-ViewModelの3つの部分に分割して設計・実装するもの。)

正直、まだこの部分については理解できていない、、。
画面とロジックは完全に分離、ロジックだけで単体テストが通ることが望ましいという感じか?
以下サイトで、MVVMパターンで作成されたサンプルコードを見ることができる。
イメージは掴めるかもしれない。
MVVM入門 その1「シンプル四則演算アプリケーションの作成」
https://code.msdn.microsoft.com/windowsdesktop/MVVM-d8261534
サンプルで学ぶ~百聞は一見に如かず~
ここからは自分でサンプルを作成し、理解を深めてみる。
①とりあえず安定のHello World(-ω-)/
新規プロジェクトの状態。MainWindow.xamlとMainWindow.xaml.csが勝手に作成されてる。
あと、すでに初期のXAMLコードが作成されてる。
まず、この時点のXAMLから理解していきたい。HTML, CSS, JavaScriptの知識があると難易度が下がるそうだが、あいにく
どの知識もないため、XML風の謎言語といった感じである。
そこで、調べたことを整理していく。
基本的には
・タグ名がクラス名
・属性がプロパティ
・XML名前空間がC#の名前空間に対応(URLに対して複数のC#の名前空間を紐づけることが出来る)
上記のことを踏まえてみていくと、
<Windows …> … タグなので、Windowsクラス。
xmlns … XML名前空間なので、名前空間(※)。(xmlns:xなどはXMLの決まり事)
Title, Height, Width … 属性なので、プロパティ(すでに値が設定されている)。
<Grid> … タグなので、Gridクラス。
ということがわかる。
※XAMLは、XML タグと .NET Framework クラスを結びつけるための機構で、XAMLの仕様自体が持っているタグと、
WPFのライブラリ中で定義されているタグ(= クラス群)の2種類のタグがある。
http://schemas.microsoft.com/winfx/2006/xaml/presentation の方が WPFで定義されたタグ(クラス群)。
http://schemas.microsoft.com/winfx/2006/xaml の方が XAMLの仕様自体に含まれるタグをあらわす XML 名前空間。
では、試しにLabelをドラッグ&ドロップ。
バインディング機能を使用したいので、ContentをBinding Helloにしてみる。

次に、Helloプロパティを追加。DataContextがビューとモデルの接点とのことなので、DataContextに自分を設定。
(自分を設定するのはHelloを自分が持っているから。別クラスならそのクラスを設定する)
ちなみに、Bindingできるのはプロパティだけなのでフィールドとかはダメらしい。
あと、publicじゃないとダメらしい。

最後に実行。

おわりに
本当はもう少しアプリらしいサンプルも作成する予定であったが、なかなか難しく作成まで至らなかった。
次は、MVVMを意識して、アプリ作成に挑戦してみたいと思う。
参考
「WPF入門」http://www.atmarkit.co.jp/ait/articles/1005/14/news105.html
「MVVMパターンの常識」http://www.atmarkit.co.jp/fdotnet/chushin/greatblogentry_02/greatblogentry_02_01.html
SVGを使ってみよう
SVGという画像フォーマット
SVGは、XMLベースのベクター形式画像フォーマットです。
要するに、以下の特徴があります。
- 基本図形(矩形、折れ線、ベジエ曲線、テキスト…)の組み合わせ
- JPGやPNGと違い、拡大しても「ギザギザ」にならない
- 単純な図形であれば容量を小さくできる
使い方
普通の画像ファイルと同じように使えます
<img src="hoge.svg" alt="ほげほげ">
body {
background: url(hoge.svg);
}
HTMLに埋め込む
HTML5では、 svgタグをHTML中に埋め込むことができます。
<svg x="0" y="0" width="400" height="300"> <circle cx="200" cy="150" r="100" fill="black" /> </svg>
JavaScriptで動かす
JavascriptでDOM操作をすることで、動的に変更することができます。
<svg x="0" y="0" width="400" height="300" onclick="document.getElementById('svg3').setAttribute('fill','red')">
<circle cx="200" cy="150" r="100" fill="black" id="svg3" />
</svg>
CSSを適用する
SVGの要素自体にCSSを適用できます。
<svg x="0" y="0" width="400" height="300""> <circle cx="200" cy="150" r="100" id="svg4" /> </svg>
#svg4 {
fill:red;
}
Excel VBA オートフィルターの挙動を調べた
使用環境: MS Office Excel 2010
VBA で Excel のオートフィルターを操作する方法について調べる機会があったので、その内容をここにまとめておく。
(基本的な使い方はぐぐったり Microsoft の公式ページを読んだりすればわかるので、ここではより細かな点について触れる)
オートフィルターを設定する
オートフィルターを設定するには、Range オブジェクトの AutoFilter メソッドを使う。
(レシーバーとなる Range オブジェクトの選定方法については後述。ここではとりあえず表の左上セルとしておく)
ActiveSheet.Range("A1").AutoFilter Field:=1, Criteria1:=">10"
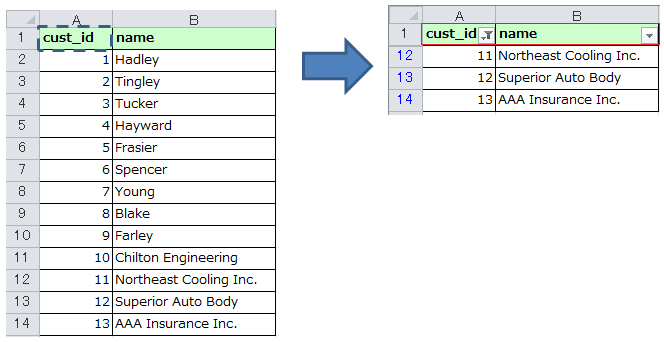
ただこれだけだと、ワークシート内で既にオートフィルターが設定されている場合に問題が起こる。
指定した Range オブジェクトが無視され、設定済みのオートフィルターでフィルタリングが行われてしまう。
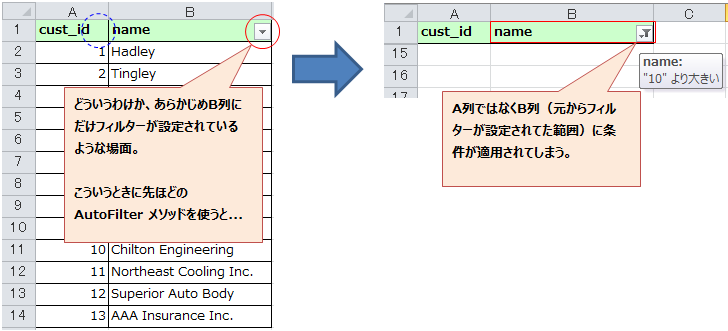
こういう場面にも対応するには、事前に「オートフィルターを解除する」コードを忍ばせておく。
With ActiveSheet
.AutoFilterMode = False ' オートフィルターが設定されていた場合、解除する
.Range("A1").AutoFilter Field:=1, Criteria1:=">10"
End With
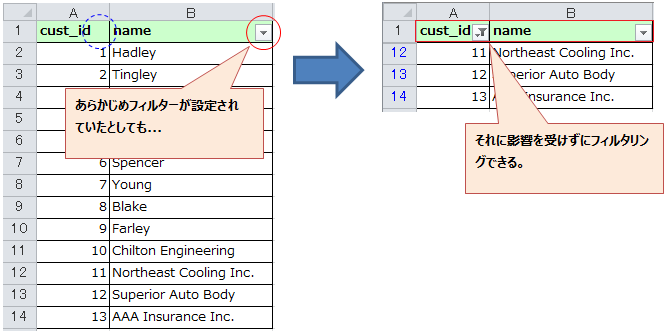
オートフィルターの範囲
先ほどの例では、表の左上のセル(A1)を指定して AutoFilter メソッドを呼び出していた。
そうすると、結果的に A1:B14 の範囲がフィルタリングされるのであった。
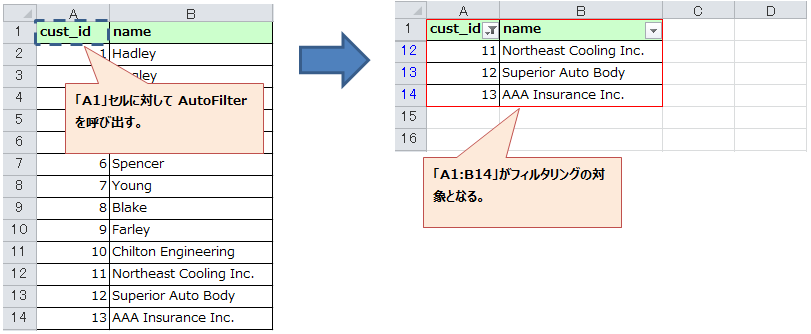
これは、表内の別のセル(たとえばB7とか)を指定しても同じである。

この挙動は「データ範囲の自動認識」によるもの。
セルの書式とか、セルに値が入っているかどうかなどを見て自動的にどこからどこまでが表かを判断してくれている。
詳しい仕様は以下のページを参照
https://support.microsoft.com/ja-jp/help/814229
http://www.eurus.dti.ne.jp/~yoneyama/Excel/yakusoku/range.html
「データ範囲の自動認識」は、セルを1つだけ選択してオートフィルターを適用した場合にのみ働き、セルを2つ以上選択してオートフィルターを適用した場合は働かない。
With ActiveSheet
.AutoFilterMode = False
.Range("A1").AutoFilter Field:=1, Criteria1:=">10"
End With
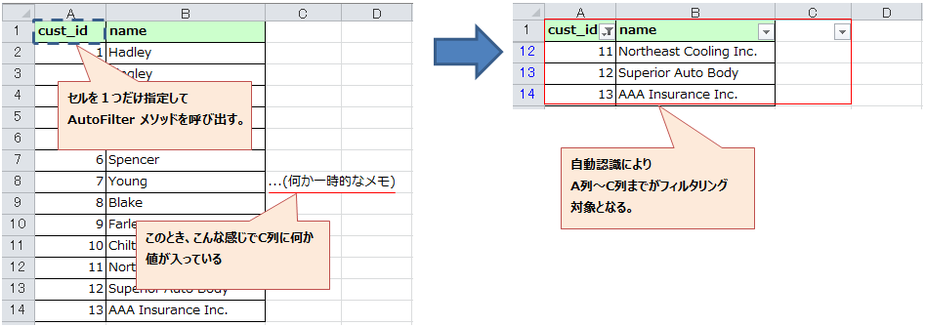
With ActiveSheet
.AutoFilterMode = False
.Range("A1:B1").AutoFilter Field:=1, Criteria1:=">10"
End With

オートフィルターの条件
オートフィルターの条件(Criteria1, Criteria2)には、以下6種類の比較方法を指定できる。
| 1. xx と等しい | "=xx" |
| 2. xx と等しくない |
"<>xx" |
| 3. xx より大きい |
">xx" |
| 4. xx 以上 |
">=xx" |
| 5. xx より小さい |
"<xx" |
| 6. xx 以下 |
"<=xx" |
また、ワイルドカードと組み合わせて以下のような条件も表現できる。
| 7. xx で始まる | "=xx*" |
| 8. xx で始まらない |
"<>xx*" |
| 9. xx で終わる |
">*xx" |
| 10. xx で終わらない |
">=*xx" |
| 11. xx を含む |
"<*xx*" |
| 12. xx を含まない |
"<=*xx*" |
これはおそらく、COUNTIF 関数の条件式に指定できる内容と同じ。
=COUNTIF(A1:A30, ">30") ←これ
ところで、少し気になったことがあったので実験。
かなりわざとらしいが、以下のようなデータを用意(ちなみに、昇順にソートしてある)。

これを、(まずはVBAを使わず手動で)「=b(イコール・ビー)」「より大きい」でフィルタリングしてみる。
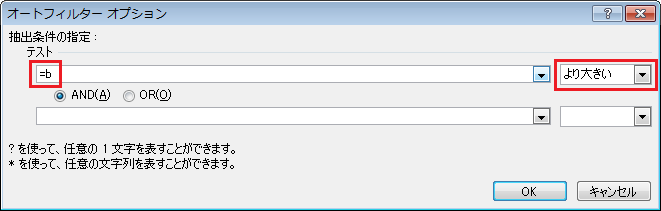
予想では、昇順に並べて「=b」「より大きい」データ…即ち「=c」「a」「b」「c」の4つが引っかかるはずである。
しかし実際は、「b」「c」の2つしか引っかからなかった。

フィルターオプションを開き直してみると、さっきと内容が違っている。

マクロの記録で VBA コードを吐かせてみると原因ははっきりしており、当初「=b」「より大きい(>)」のつもりで設定した条件が、実際は「b」「以上(>=)」と解釈されてしまうため。

| >=b |
「=b」「より大きい(>)」 |
|
| >=b | 「b」「以上(>=)」 | ←Excel による解釈はこっち |
エスケープする方法とかないのかと探してみたが見つけられず。
(まぁ、これができないからといって困る場面なんてそう多くはなさそうだが)
どうしてもこのような条件でフィルタリングしたければ、以下のように AND 条件を指定してやることになるか。


VBA で書くなら以下の通り。
With ActiveSheet
.AutoFilterMode = False
.Range("A1").AutoFilter Field:=1, Criteria1:=">==b", Operator:=xlAnd, Criteria2:="<>=b"
End With
SQL Serverへ大量のデータを高速で追加する
SQL Serverの負荷テストで大量のデータを作成しないといけなくなり、できるだけ高速で作成する方法を探してみました。
まず、単純にループを使用して100万件のデータを作成するSQLを作成してみました。
・ループを使用して100万件のデータを作成するSQL
SET NOCOUNT ON
DECLARE @RowCount INT
SET @RowCount = 0
WHILE @RowCount < 1000000
BEGIN
INSERT INTO T_Test (Data1,
Data2,
Data3,
Data4,
Data5)
VALUES
(@RowCount,
'DATA' + right('0000000000' + convert(varchar, @RowCount), 10),
'0',
'0',
'0')
SET @RowCount = @RowCount + 1
END
上記SQLを実行した結果。

ループ処理で100万件データを作成した結果、処理時間は3分6秒でした。
もし1000万件のデータを作成しようとした場合、単純計算で30分かかります。
テーブル数が多い場合やデータ件数が増えてしまうと、実用的には厳しい感じです。
他にいい方法がないかと調べた結果、再帰クエリを使用した場合、飛躍的に高速でデータが作成できました。
・再帰クエリを使用し、大きなSELECTデータをINSERTするSQL
DECLARE @p_NumberOfRows Bigint
SELECT @p_NumberOfRows=1000000;
WITH Base AS
(
SELECT 1 AS n
UNION ALL
SELECT n+1 FROM Base WHERE n < p_NumberOfRows
),
Nums AS
(
SELECT Row_Number() OVER(ORDER BY n) AS n FROM Base
)
INSERT INTO T_Test
SELECT n,
'DATA' + right('0000000000' + convert(varchar, n), 10),
'0',
'0',
'0'
FROM Nums WHERE n <= @p_NumberOfRows
OPTION (MaxRecursion 0);
上記SQLを実行した結果。

再帰クエリを使用して100万件のデータを作成した結果、処理時間は9秒でした。
この方法だと、1000万件のデータでも90秒で作成できます。
1億件でも約15分程度で作成できることになり、実用的なレベルで使用できると思います。
上記SQLでも十分かなと思っていたのですが、もう一工夫することでもっと早く作成できることができました。
・再帰クエリを修正したSQL
DECLARE @p_NumberOfRows Bigint
SELECT @p_NumberOfRows=1000000;
WITH Base AS
(
SELECT 1 AS n
UNION ALL
SELECT n+1 FROM Base WHERE n < CEILING(SQRT(@p_NumberOfRows))
),
Expand AS
(
SELECT 1 AS C FROM Base AS B1, Base AS B2
),
Nums AS
(
SELECT Row_Number() OVER(ORDER BY C) AS n FROM Expand
)
INSERT INTO T_Test
SELECT n,
'DATA' + right('0000000000' + convert(varchar, n), 10),
'0',
'0',
'0'
FROM Nums WHERE n <= @p_NumberOfRows
OPTION (MaxRecursion 0);
上記SQLを実行した結果。

先ほどの再帰クエリを修正して実行したところ、100万件のデータを作成する処理時間は4秒でした。
1000万件でも約40秒で作成できることになり、ループを使用して作成するより圧倒的に高速で
データが作成できるようになりました。
ストアドプロシージャにしてテーブル名や作成する件数を変数化してやればもっと汎用的に
使用できるようにもなり、データ作成も高速に行えると思います。
C言語
1.C言語は時代遅れの言語か?
●なぜいまだにC言語がつかわれるのか
C言語が世に出たのは、1972年で、現在使われている言語のなかでは、かなり古い言語に分類されます。また、パソコンやWeb、スマートフォンなどといった分野でも、JavaやPHP、C#などといった新しい言語が主流になり、ともすれば、C言語は必要ではない古い言語ではないか、と思われがちです。
ただ、C言語というのは不思議な言語で、C言語が世に出た当時も、そして、その後今に至るまで、数多くの「C言語よりも優れている」と思われる言語が出現してきたものの、結局生き残っているのです。
つまり、C言語と同時期、もしくはそのあとに出てきて、一時的にC言語よりも広く使われていても、その後廃れてしまったり、ほとんど使われなくなった言語は非常にたくさんあるのです。ではいったい、どうしてそんなにC言語は長い間使われ続けているのでしょうか?
●C言語の歴史
まずは、そもそもC言語とはいつ、どのようにして開発されたかということについて説明しましょう。前述のように、C言語は1972年に開発されました。開発者である、Dennis M. Ritchieは、当時Ken
Thompsonらと共同で、ミニコンピュータのオペレーティングシステムであるUNIXの開発に携わっていました。このOSは、初期の段階ではアセンブリ言語を用いて開発されましたが、その後、C言語で書き直されました。
つまり、UNIXを移植するために開発されたのがC言語なわけです。そのためC言語はUNIXの副産物であると言えるでしょう。そういったこともあり、UNIX上で動作する多くのアプリケーションも、C言語で開発されることになりました。またその勢いはとどまるところを知らず、次第に大型コンピュータやパーソナルコンピュータの世界にも普及していったのです。
●C言語はこまわりがきく
この当時、C言語以外にも様々なプログラミング言語が存在していました。ではなぜ、それにもかかわらずC言語がこのように爆発的に普及したのでしょう?理由の一つは、C言語の「コンパクトさ」にあるでしょう。JavaやC#などといった言語は、C言語の欠点を補う様々な改良がなされていますが、実行に独自のフレームワークを必要としたり、同じような処理を行うにしても、C言語にはスピードの速さや、コードのコンパクトさの面でかなわない、という特徴があります。もう少し詳しく言うと、C言語によって生成されるアセンブラのコードのサイズが小さいため、スピードが速いうえに、メモリの使用も最低限で済ませることができるからで、これに関してC言語に取って代われる言語はほかにないでしょう。
そういったことから、OSなどの心臓部分を記述するのは、相変わらずC言語です。また、組み込みプログラミングと言って、家電製品や自動車の制御装置など用いられているコンピュータは、相変わらずC言語が用いられています。
小回りが利いて、スピーディーであり、それでいてアセンブラほど難しくないというのがC言語の特徴であり、その利点を生かせる分野では、C言語はまだまだ現役バリバリで活躍中です。
●OSも、プログラミング言語も最後はC言語が必要
そういったことから、Ruby、Java、PHPなどといった言語のようなC言語よりもかなり後にできた言語のコンパイラーやインタープリタも、実はC/C++言語で記述されています。同様に、サーバー系のOSとして主流である、Linuxも、「カーネル」と呼ばれる核になる部分はC言語でなくては記述できません。その他、WindowsやMacOSなどといった、主要なOSも、期間部分はC言語で記述されています。
つまり、こういったことからも、C言語がまだまだ必要であり、かつ現役のプログラミング言語であることがよくわかると思います。
●過去の蓄積も豊富
またもう一つの理由は、「過去の遺産の多さ」です。C言語は、後継言語であるC++言語によって、オブジェクト指向という新しい考え方のプログラミングでも用いることができるようになりました。
C++言語の最大の特徴は、C言語のソースコードをそのまま流用できることにあり、過去の遺産を継承しつつ、オブジェクト指向という新しい技術に対応できるようになっているのです。そういったこともあり、C言語は、長い間使いづけられ、その結果、ソースコードやノウハウが蓄積し、よりプログラマーにとって利用しやすい言語となって生き残ってれこれたのです。
2.なぜ、C言語っていうの?
●C言語の名前の由来
C言語という名前を聞いて、「なぜそんな名前なの」と、疑問を持った人も少なくないでしょう。実は、この「C」という言葉が言語に採用された理由は、「その前にB言語という言語があったから」ということが大きな理由です。
B言語とは、1970年にケン・トンプソンという人が、PDP-7というコンピュータ上で最初のUNIXシステム用に開発したプログラミング言語です。となると、「もしかしたら、B言語はA言語という言語をもとにして作られたのか?」と思われたかもしれませんが、B言語は、もともとBCPL(Basic Combined Programing
Language)という言語を元に開発されたものなので、この推理は間違いです。
ただ、C言語は、明らかにB言語の後継の言語として作られたもので、その点に関しては、C言語の作者自身が明らかにしているので、間違いないでしょう。
●B言語との違い
B言語には、実行環境に依存しないという特徴があり、その点はC言語で受け継がれています。ただ、B言語は、もともとC言語と違い、「型の指定」がありませんでした。これは、現代の様々な言語の先取りをしているといえますが、C言語はあえてこの考え方を捨てました。
これにより、B言語のプログラマーが意識しなくてもよかったデータの「型」というものをプログラマーが自分で意識しながらプログラムをする必要が出てきました。これは一見、言語としてはB言語よりある意味では後退している、と言えなくもありません。しかし、結果的にこれがC言語を普及させるうえでプラスになった、と言っても過言ではありません。
なぜなら、れこによりプログラマーは、よりアセンブラに近いコードが記述できるようになり、コンパクトで効率的なプログラムを記述できるようになったのです。当時のコンピュータの性能は現在のものとは比較にならないほど低かったため、こういった現実的な対応が、結果としてはC言語の普及に拍車をかけたといえるでしょう。
●かつて全盛を極めたC言語
C言語が誕生したときには、すでに沢山のプログラミング言語が存在し、C言語よりもはるかに普及していたものもありました。しかし、C言語はそれらを押しのけて、やがてプログラミング言語の中でもっとく普及する、いわば「プログラミング言語の王者」となります。
しかし、この時、言語としてはC言語よりも完成度が高い言語はほかにも生地にも存在していたにもかかわらず、です。では一体、なぜそのようなことになったのでしょうか?
理由はいろいろありますが、その一つはC言語がUNIXとセットになっていた点にあるでしょう。その後、UNIXはコンピュータのOSの主流として大いに普及していき、それとともに、C言語もそれと伴い、広く使われるようになりました。
また、UNIXをまねて作られたマイクロソフト社のMS-DOSの普及もまた、それに拍車をかけました。MS-DOSは、当時主流だったパーソナルコンピュータ、IBMのIBM-PCの主要OSとして普及し、そのプログラミング言語としてもっともよくつかわれていたのが、C言語でした。この、マイクロソフトのMS-DOS(または、PC-DOS)と、C言語の組み合わせは世界中に普及し、ほぼ「デファクトスタンダード」と言ってもいいような組み合わせとして存在していました。
当時のパーソナルコンピュータは、現在のコンピュータほど性能が良くなかったために、高級言語で高パフォーマンスの言語を作れるC言語は非常に重宝されていたのです。
●C言語の後継言語
現在、C言語は、いわば「歴史的役割」を終えて、主要なプログラミング言語の第一線を退いていると言えます。しかし、その後継の言語はまだまだ現役で使用されており、そういった意味でC言語の存在感は失われていないと言えるでしょう。
C言語の直接の後継言語は、C言語にオブジェクト指向の考え方を導入したC++言語です。また、同じような意味でアップル社で開発されたObjective-Cもまた、オブジェクト指向のC言語の直接の後継言語といえるでしょう。
さらに、直接の関係はありませんが、Java言語も、文法の仕様などでC言語の営業をかなり受けており、C言語を覚えたプログラマーにとっては非常にとっつきやすい言語使用になっています。
また、マイクロソフト社が開発したC#言語も、C/C++言語の後継言語として開発され、現在では主流のプログラミング言語として君臨しています。このように、現在使用されている主要なプログラミング言語はほぼすべて、C言語の後継か、強く影響を受けた言語だということがよくわかります。
3.バッファーオーバーフロー
●バッファーオーバーフローとは何か?
アプリケーションソフトにセキュリティホールが見つかって、「悪意のあるコードが実行される可能性がある」というような内容のニュースを聞いたことがある人は少なくないでしょう。そもそも、この「悪意のあるコード」とは一体何なのでしょうか?
コンピュータウイルスやワーム、バックドア、キーロガーなどが代表的で、情報システムや提供するサービスの妨害など、悪影響を及ぼすコードが含まれるプログラムのことで、文字通りシステムに「害悪」をもたらすことを目的とした者によって作成されたプログラムのことです。
そしてそういった悪意のあるコードが、システムを攻撃する手段としてよく用いられるのが、この「バッファーオーバーフロー」という手法なのです。
●バッファーとその仕組み
バッファーオーバーフローについて説明する前に、そもそも「バッファー」とは何かということから説明しましょう。
コンピュータのプログラムは、情報を格納するための領域をメモリ上に確保します。特に、文字情報を格納する場合、その文字数に応じて連続したメモリ領域を確保します。このように、同じ形式のデータを複数個格納するためにメモリ上に確保する領域のことをバッファ領域と言います。
バッファへの情報の格納方法としては、ネットワークからの入力、ファイルからの入力、キーボードなどの入力デバイスを介してのユーザーからの入力などがあります。
●バッファオーバーフローの仕組み
しかし、言うまでもないことですがこのバッファーの容量には限界があります。バッファ領域の上限はプログラムが規定出来ても、プログラムを実行するCPUはバッファ領域の上限がわかりません。
そのため、情報をバッファ領域に格納する際、格納する情報の大きさがバッファ領域の上限を超えてしまうことがあります。すると、CPUはバッファ領域を超えて情報を格納してしまいます。これが、バッファーオバーフローです。
バッファオーバーフローが起こってしまうと、メモリ上の不正な場所に情報を格納することになってしまうため、プログラムが誤動作したり、ほかの領域に保存されている大事なデータを破壊してしまったりします。
●バッファーオーバフローによるセキュリティーホール
クラッカーは、このバッファオーバーフローをわざと起こしてデータの改竄・コンピュータシステムの損壊につながる操作をおこなうことから、ソフトウェアでバッファオーバーフローの脆弱性が発見されると、高い優先度で修正が行われ、更新バージョンのプログラムや修正パッチの公開・配布などが行われます。
それだけ、バッファーオーバフローによる攻撃はやっかいなのです。
●C言語とバッファーオーバーフロー
実はC言語は、このバッファーオーバフローが起こりやすい仕組みを持っている、という致命的な欠点を持っているのです。
例えば、C言語の標準入出力関数であるscanf関数やgets関数はバッファ長のチェックを行わないで標準入力をバッファに書き込むので、バッファーオーバーフローを起こしやすくなっています。
C言語の歴史はたいへん古く、インターネットが現在のように普及するはるか以前に作られた言語ですから、言語の仕様の中にそういった欠点があるのはある意味仕方がないのとかもしれません。そういったこともあり、C言語は新しいバージョンであるC11でこういった問題に対処するために、gets関数を排除するなどの対策をしています。
しかし、メールサーバーなどで用いられるsendmailと呼ばれるプログラムは、C言語でかかれ、古いライブラリ関数を多用していることから、頻繁に修正されていましたが、ついにはセキュリティ上の問題などでsendmailを標準プログラムから排除する動きがあり、いくつかのOSの標準セットからsendmailは取り除かれてしました。
●セキュアなコード
こういったバッファーオーバフローなどによる脆弱性への対策を行っているコードのことを、「セキュアなコード」と言います。またそのようなコードのプログラミングを行うことを「セキュアプログラミング」と言います。
セキュアなコードをかくための方法は大きく分けて二つあります。一つは、従来の枠組みのなかでできるだけ「セキュア」にプログラミングをする方法、そしてもう一つは「セキュアな関数」を用いてプログラミングを行う方法です。
たとえば、マイクロソフトは、自社が開発したVisualC++コンパイラで、危険性のあるscanfのかわりに、scanf_sという「セキュアな」scanfを用意して、バッファーオーバランを回避する工夫をしています。これにより、以前よりもセキュアなコードを作成しやすくなりましたが、「完全」な対策を行うことは不可能です。
ただ、セキュアなコードをかく方法に関しては、研究が進んでおり、ネットなどでも多くの情報を得ることができます。プログラマーは、そういった情報を絶えずチェックして、脆弱性の低いプログラム作りを心掛ける必要がります。
4.C言語とオブジェクト指向
●C言語は構造化プログラミング言語
このコラムのいくつかのトピックでもすでに取り上げたように、C言語というプログラミング言語は1972年に開発された言語で、ITという変化の激しい世界の中では非常に歴史の古い存在で、それだけ長く残ってきたことは偉大なことではありますが、どうしても「時代遅れ」の部分があることも事実です。
そもそも、C言語というプログラミング言語は、構造化プログラミング言語と呼ばれるもので、プログラム全体を段階的に細かな単位に分割して処理を記述していく手法です。この考え方は、1960年代後半にオランダの情報工学者エドガー・ダイクストラ(Edsger Wybe Dijkstra)氏らによって提唱されたもので、C言語はそれを具現化したものの一つです。
その考え方は、「一つの入口と一つの出口を持つプログラムは、順次・選択・反復の3つの論理構造によって記述できる」というもので、この原則に従うことにより、大規模なプログラムを効率よく、少ないミスで設計・記述できるようになりました。
そして、この原則に従うことにより、大規模なプログラムを効率よく、少ないミスで設計・記述できるようになるようになったので。そしてそれは、C言語が大きく成功した理由の一つでした。
●C言語の限界
このように、当時としては斬新な手法で開発されたC言語は、プログラミングのみならずコンピュータ関連技術の発展に大いに寄与しました。とはいえ、やはり時代の変化には抗しがたく、C言語にも限界が見えてきました。
C言語の欠点は、いくつか挙げることができますが、ここで最大の問題になったのが、「大規模開発に向かない」ということでした。
こういう言い方をすると、「それは、C言語が開発されたときのメリットの一つだったのでは?」と疑問に思う方もいるでしょう。しかし、C言語が出来た当時とその後とでは、「大規模」の「規模」が違ってきてしまうのです。C言語は確かに、「その当時としては」大規模開発に適した言語でした。しかし、C言語が可能にしたさらなる大規模開発には、「C言語では物足りない」という状況を創り出していったのです。なんとも皮肉な話です。
●オブジェクト指向の考え方の導入
そのように、限界にぶつかったC言語でしたが、この状況を打破する方法として考えられたのがオブジェクト指向という考え方の導入でした。オブジェクト指向とは、ソフトウェアの設計や開発において、操作手順よりも操作対象に重点を置く考え方で、データやその集合を現実世界のモノ(Object)になぞらえた考え方です。
例えば、我々が自動車を運転するとき、自動車の内部でどのような装置が動作しているかを理解する必要はありません。ただ運転方法だけを知っていればいいだけです。このように、個々のオブジェクトに対し、操作方法を設定することでその内部の難しい詳細を覆い隠し、利用しやすくしようとする考え方がオブジェクト指向です。
このオブジェクト指向を導入すれば、プログラマーはすでに用意された完成された「部品」を上手に組み合わせることにより、簡単にプログラムができるようになります。C言語とは無関係に開発されたこのオブジェクト指向という考え方ですが、ついにその考え方がC言語にも適用されるようになったのです。
●C++とObjective-C
C言語に対するオブジェクト指向への対応という拡張は、独自に2つの道がとられました。
一つは、最もポピュラーなオブジェクト指向言語の一つといえる、C++(シー・プラス・プラス)です。1983年にベル研究所のコンピュータ科学者のビャーネ・ストロヴストルップによって開発されたもので、当時の名前は「C with Classes」でした。
C++は、Simulaという当時使われていたオブジェクト指向言語の特徴をとりいれたもので、C++という名称の由来は、C言語に存在する算術演算子の一つで、整数型の変数の値に1を加えるインクリメント演算子「++」から来ているといわれています。「C言語より1つ進歩した」といったl気持ちなのでしょうか。
そして、もう一つが、Objective-Cです。Objective-Cは、1983年にブラッド・コックスによって開発され、そのコンパイラやライブラリを支援するためにStepstone社を創立しました。しかし、しばらくはマイナーな存在でしたが、1985年にアップルコンピュータを去ったスティーブ・ジョブズが、この言語に着目し、彼がNeXT
Computer社を創立した際には、その製品であるNeXTコンピュータの主力言語となりました。
のちにジョブズがアップル社に復帰すると、この言語は、MacOSXや、iOSのソフトウェア開発に用いられるようになり、現在では、「アップル製品用のオブジェクト指向言語」として普及するようになりました。
●その後の後継言語
前述の二つの言語、C++や、Objective-Cの特徴は、C言語のソースコードがそのまま使える、ということでした。つまり、それまでのC言語の資産を継承しつつ、オブジェクト指向プログラミングが可能である、という点が最大の特徴でした。
その後、オブジェクト指向が、プログラミングの一般的な考え方となると、C言語の記述方法などは継承しつつ、C言語とは全く違ったオブジェクト指向言語が現れ、普及するようになりました。
そのなかでもメジャーなものの一つが、Javaで、C言語/C++言語の文法を参考にしつつも、ポインタ等の低レベルな操作は基本文法から排除されており、仮想マシンの上で動作し、これにより、プラットフォームに依存しないアプリケーションソフトウェアが開発できるというC言語にはなかった特徴を持っています。
また、マイクロソフトが開発したC#言語もまた、C言語やC++言語を継承しており、これら言語の文法の利点を継承しつつ、独自の拡張がなされています。言語の開発に従事したアンダース・ヘルスバーグは、「C#」が「C++++」(すなわち「C++をさらに進めたもの」)にみえるのが由来、と語っており、このことからも、この言語がC/C++言語の後継言語であることを意識していることがわかります。
さらに、アップル社も、Objective-C言語の後継言語として、Swiftという言語を開発しました。このように、オブジェクト指向もいわば「第二世代」に入り、残念ながらC言語はますます肩身が狭くなりそうです。
dateコマンドで前月をYYYYMM形式で取得する(※ーdオプション禁止)
仕事でSolarisサーバーからシステム日付の前月と前々月の年月を
YYYYMM形式で取得する処理のシェルスクリプトを書くことになりました。
この時に、一筋縄ではいかないことがありました。
その時にどうやって対処したかを記載します。
一番簡単な方法
普通、日付の1か月前の計算はこのようにして行います。
# 1カ月前
$ date -d ‘1 month ago’
このように-dオプション又は-dateオプションを使います。
ところが、同じUnix系なのにSolarisでは使えません。
(参照:http://www.fujitsu.com/jp/products/computing/servers/unix/sparc/technical/command-reference/sys2/07.html)
Solarisのdateコマンドで過去や未来の日付を出すには
sh-utils若しくはshutilsというパッケージをインストールすればいいらしいです。
(参照:https://blogs.yahoo.co.jp/bobuton/26034312.html)
そこで、これを本番環境でインストールしてもいいかお客様に尋ねたところ
「他の重要な処理に影響が出たら困るので、避けてほしい」
との回答が……。
ということで、-dオプションを使わずに日付計算をすることになりました。
最初は、タイムゾーンを設定することで取得できると調べたときにわかり、考えたのが
LASTMONTH=`JST+15 date “+%Y%m”`
(1日前の年月日時刻を取得し、YYYYMM形式で表示)
(参照:http://shellscript.sunone.me/date.html#gnu-date-が使用できない場合-1)
でした。
この処理が「毎月1日に行われる」ことを利用した策ですが
実行日を変更するとき、わざわざこの“+15”を変えないといけません。
これではいつの日にか、ユーザー様にご迷惑をお掛けすることになりますね。
しかも、これは最大でも1週間程度までしか遡れなかったので
中旬以降に実施することに変更になってしまえば、たちまち使えなくなってしまいます。
別の手段を探すことになりました。
そして、日付を整数として計算するという方法を見つけました。
(参照:http://shellscript.sunone.me/date.html#先月の月を取得する)
まずは、システム日付を年月だけの形式(YYYYMM)で取得します。
SYSDATE=`date “+%Y%m”`
1カ月前なら、この変数SYSDATEを整数扱いにして1を引けばいいので
LASTMONTH=`expr ${SYSDATE} -1`
しかし、これではある罠にはまってしまうことに気付きました。
例えば、この処理が2018年1月に行われたとき、どうなるでしょうか。
LASTMONTH=201801-1=201800
と、2018年0月となってしまいます。
これでは具合が悪いので
1月にこの処理が行われた時とそうじゃない時とで条件分岐を与え
別の処理を施す必要が出てきました。
最初に思いついたのは
この変数LASTMONTHを月だけに分け
LASTMONTH_M=${LASTMONTH:4:2}(これで変数から部分的に文字列を取得する)
このLASTMONTH_Mが”00”になるときは
LASTMONTH=LASTMONTH-88
をするということでした。
実際、2018年1月にこの処理を実行したとすると
LASTMONTH=201801-1=201800
LASTMONTH_M=00
LASTMONTH=201800-88=201712
となります。
ただ、これでいいかどうか、相談してみたところ
月計算で88を使うなんて直感的ではない、分かりにくいと指摘を受けました。
それとともに、年と月で分けて計算したほうがいいのではないか?とアドバイスをもらいました。
その後、次のように変更しました。
LASTMONTH=`expr ${SYSDATE} -1`
LASTMONTH_Y=`${LASTMONTH:0:4}`
LASTMONTH_M=`${LASTMONTH:4:2}`
if [${LASTMONTH_M} -eq “00”]; then
LASTMONTH_Y=`expr ${LASTMONTH_Y} -1`
LASTMONTH=”${LASTMONTH_Y}12”
fi
取得した前月を年と月に分け
前月が“00”になったとき
年だけ1引いて
その年の後ろに“12”を付け足すという考えです。
実際に2018年1月に実行されたとして計算してみると
LASTMONTH=`expr ${SYSDATE} -1` =201801-1=201800
LASTMONTH_Y=`${LASTMONTH:0:4}` =2018
LASTMONTH_M=`${LASTMONTH:4:2}` =00
if [${LASTMONTH_M} -eq “00”]; then
LASTMONTH_Y=`expr ${LASTMONTH_Y} -1` =2018-1=2017
LASTMONTH=”${LASTMONTH_Y}12” =201712
fi
このように前月を取得することができます。
storcliでRAIDのステータスを確認する
storcli とは、なんぞや?というと、megacliの後継に当たるCUIのRAID管理ユーティリティツールで、megacliの後継にあたるツールらしい。
後継と言うからにはmegacliに出来ることは全部できるらしいので、今回はこれを使ってRAIDのステータスを確認し、異常を検知したら通知する仕組みを作ることになった。
storcliでのステータス確認方法
今回使ったのはVersion1.17.08。それだと、こんな感じで表示される。
# storcli show all
Status Code = 0
Status = Success
Description = None
Number of Controllers = 1
Host Name = localhost
Operating System = Linux3.10.0-327.el7.x86_64
System Overview :
===============
-------------------------------------------------------------------------
Ctl Model Ports PDs DGs DNOpt VDs VNOpt BBU sPR DS EHS ASOs Hlth
-------------------------------------------------------------------------
0 <RAIDコントローラ名> 8 2 1 0 1 0 Msng On
1&2 N 2 Opt
-------------------------------------------------------------------------
Ctl=Controller Index|DGs=Drive groups|VDs=Virtual drives|Fld=Failed
PDs=Physical drives|DNOpt=DG NotOptimal|VNOpt=VD NotOptimal|Opt=Optimal
Msng=Missing|Dgd=Degraded|NdAtn=Need Attention|Unkwn=Unknown
sPR=Scheduled Patrol Read|DS=DimmerSwitch|EHS=Emergency Hot Spare
Y=Yes|N=No|ASOs=Advanced Software Options|BBU=Battery backup unit
Hlth=Health|Safe=Safe-mode boot
ASO :
===
----------------------------------------------------
Ctl Cl SAS MD R6 WC R5 SS FP Re CR RF CO CW HA SSHA
----------------------------------------------------
0 X U X X U U X U X X X X X X X
----------------------------------------------------
Cl=Cluster|MD=Max Disks|WC=Wide Cache|SS=Safe Store|FP=Fast Path|Re=Recovery
CR=CacheCade(Read)|RF=Reduced Feature Set|CO=Cache Offload
CW=CacheCade(Read/Write)|X=Not Available/Not Installed|U=Unlimited|T=Trial
|HA=High Availability |SSHA=Single server High Availability
show all をオプションに指定すると、こんな感じで全コントローラのステータスが習得できる。
ステータスについて、最初は冒頭のStatusCodeやStatusを見れば良いのかな?と思ったが、紛らわしいことにこいつはコマンドの実行結果を示すようなところらしい。
なので、実際異常が発生しているかは「System Overview」を見て判断する必要があるようだ。
末尾のHlthがステータスを示すパラメータのようで、正常時はOpt。
異常時は、エラー起こさないといけないので試せてないけども、DNOptとかVNOptとか、Msngになるのかな。
RAIDステータス異常の検知方法
とりあえずこんな感じで、System Overviewからステータス取得するようなシェルのロジックを作ってみた
storcli show all > RaidStatus.txt
Status=`awk '/^Ctl Model/ { getline;while(getline){ if ($1 !~ /[[:digit:]]/){ break; } print $1,$NF } }' RaidStatus.txt
コントローラのIDとステータスがこれで取れるので、あとはwhileループなりで処理してやれば、異常の検知は出来そうだ。
余談だけども、「storcli /c0 show」としてやれば、0番のコントローラのシリアル番号だとかFWバージョン、PCIスロットの位置だとか色んな情報が取得できる。
物理ディスクのステータスも確認できるので、いざ障害が発生したときはこれで調査すると良さそう。
「storcli /c0 show all」だと更に細かい情報も取得できるけども、情報が多過ぎるので自分で見る分にはshowだけの方がわかりやすそうだった。
LINQ: Select, SelectMany
LINQが提供する機能を紹介します。
まずは、一番基本的な(よく利用する)機能のSelect, SelectManyから。
select(シーケンスの各要素を新しいフォームに射影)
selectはクラスから特定のプロパティを取り出したり、プロパティ値を加工したりすることができます。
例:1-10の各数値を二乗して取得
IEnumerable<int> squares = Enumerable.Range(1, 10).Select(x => x * x); foreach (int num in squares) { Console.WriteLine(num); } /* This code produces the following output: 1 4 9 16 25 36 49 64 81 100 */
例:文字列型を数値型として取得
string[] nums = new[] { "1", "2", "3", "4", "5" };
IEnumerable<int> numsInt = nums.Select(x => Int32.Parse(x));
// -> { 1, 2, 3, 4, 5 }
SelectMany(Selectの結果シーケンスを 1 シーケンスに平坦化)
SelectManyは、結果を平坦化するSelectです。
言葉ではイメージしにくいので具体例で理解してください。
例:2重配列を単純配列にする
string[][] jaggedArray =
{
new []{"a", "b", "c"},
new []{"1", "2", "3"},
new []{"い", "ろ", "は"},
};
IEnumerable<string> flatten = jaggedArray.SelectMany(x => x);
// -> {"a", "b", "c", "1", "2", "3", "い", "ろ", "は"}
例:グループ内の全メンバを取得
class Group
{
public string Name { get; set; }
public List<string> Member { get; set;}
}
List<Group> company = new List<Group>()
{
new Group() { Name = "総務部", Member = new List<string>() { "徳増", "鈴森" }},
new Group() { Name = "システム開発部", Member = new List<string>() { "清水", "堂山", "久松" }},
}
IEnumerable<string> allmembers = company.SelectMany(n => n.Member);
// -> {"徳増", "鈴森", "清水", "堂山", "久松"}
WindowsでiOSアプリをつくってみる
iPhoneアプリを作ってみたいと思っていましたが、Mac持っていないし、つくれないじゃんって
半分あきらめていましたが、とうとうWindowsでも開発が可能になったという朗報を聞き、早速試してみました。
可能にしたのは
可能にしたのは、VisualStudioとXamarin(ザマリン)です。
試してみたところ、試験運用中のようですが、動作はしました。
必要なもの
- Windows PC (試したものは、Windows 10)
- Visual Studio Community 2017 preview
- Xamarin (試したものは、4.5.0.486)、Xamarin.iOS and Xamarin.Mac SDK (10.10.0.37)
- iOS (試したものは、IPhone6s iOS10.3.3)
- 無線LAN(ローカルネットワーク)
手順
STEP.1 iOS側の準備

App StoreからXamarin Live PlayerをIPhoneにインストールします。
左のQRコードはAppStoreへのリンクです。
無料のようなので、インストールします。

STEP.2 Windows側の準備
Visual Studio PreviewサイトからVisual Studio Communityをダウンロードします。
つづいて、ダウンロードしたVisual Studioインストーラーを起動します。
※Communityでも試したのですが、Xamarin Updaterが導入できず、あきらめました。以下、Community Preview版で試した履歴です。

インストーラを起動すると、どのモジュールをインストールするか選択する画面が出てきます。
Xamarinを使用するので、「.Netによるモバイル開発」にチェックを入れて、インストールボタンをクリックしてください。
※iOSのアプリを試したいだけなら、Android用のJDKなどは要らないかもしれないですが、今回はお試しなのと、HDに余裕があったので、全量インストールしました。なお、概要欄の不要なものからチェックを外せば、インストール対象から外れるようです。

インストールが完了すると、早速Visual Studioを起動してみます。
起動できたら、Xamarinが使える状態か確認します。
上部メニューから「ツール」>「拡張機能と更新プログラム」を選びます。

「Xamarin for VisualStudio」、「Xamarin.Apple SDK」がインストール済みであることを確認します。

「オンライン」を選び、「Xamarin Updater」をダウンロードします。
一度、Visual Studioを落とすと、インストールが始まります。

再びVisual Studioを起動して、「ツール」>「拡張機能と更新プログラム」>「更新プログラム」を選びます。
Xamarinを左メニューから選び、中央に表示されるもの全てを更新します。
一度、Visual Studioを落とすと、インストールが始まります。
全て更新が終わったら、Visual Studioを起動します。
上部メニューから「ツール」>「オプション」を選びます。
「Xamarin」>「その他」を選びます。
Enable Xamarin Live Player にチェックを入れて、OKを押します。

Live Playerのボタンが表示されます。
これで準備は整いました。

Live Playerのボタンを実行すると、右図のような画面が表示されます。

STEP.3 サンプルアプリの準備
手っ取り早く稼働確認したいので、サンプルアプリをダウンロードしてきます。
ダウンロードサイトはこちら
今回はColor Control Sample (iOS)がかわいらしい絵柄だったのでダウンロードしてきました。
ダウンロードしたファイルはzip形式なので、Windows上に展開して、ソリューションファイル(.csproj)をVisual Studioから開きます。

STEP.4 サンプルアプリを稼働させてみる
iPhoneでXamarin Liveを起動します。
「Pair to Visual Studio」をクリックすると、カメラが起動します。
Visual Studioに表示されたQRコードを読み取りペアリングします。
これで稼働検証ができるようになります。

しばらくすると、サンプルアプリが稼働します。

感想
プログラムを動かすには、Xamarin Live Player を起動しておく必要があるようです。
iPhoneがエミュレータのように動いているだけで、iPhoneにインストール(デプロイ)されるわけではないようです。
デプロイするには、 Mac PC が必要になるということでしょうか。
でも、コードを書いたり、試したりはこれで十分なのかなと思います。
JavaScriptによるDB「AlaSQL」
ローカル環境で簡単に使用できるDBが無いか、出来ればJavaScriptで書いているコードなので
JavaScriptから扱えるものを、と探していたところに、JavaScriptで書かれたライブラリの
AlaSQLというものを知りました。
AlaSQL
http://alasql.org/
https://github.com/agershun/alasql/wiki/readme
alasql.min.jsというライブラリをimportするだけで、オンメモリで動いてくれるDB、
さらにクエリ発行も可能ということだったので、自分の求めていた機能は大体実装されていました。
折角なので少し触ってみた所を書いてみたいと思います。
◇CREATE TABLE
alasql("CREATE TABLE testa (code STRING, name STRING, category STRING, tanka INT)");
alasql("CREATE TABLE testb (code STRING, su INT)");
◇INSERT
alasql("INSERT INTO testa VALUES ('apple','リンゴ','fruit',190)");
alasql("INSERT INTO testa VALUES ('orange','オレンジ','fruit',200)");
alasql("INSERT INTO testa VALUES ('nasi','梨','fruit',210)");
alasql("INSERT INTO testa VALUES ('carrot','人参','vegetable', 210)");
alasql("INSERT INTO testb VALUES ('apple',10)");
alasql("INSERT INTO testb VALUES ('carrot',5)");
//シングルクォートとダブルクォートの使い分けがいかにもJavaScriptって感じです
◇SELECT
var rs1 = alasql("SELECT * FROM testa ORDER BY code");
console.log('rs1', JSON.stringify(rs1));
結果セット:
rs1 [{"code":"apple","name":"リンゴ","category":"fruit","tanka":190},
{"code":"carrot","name":"人参","category":"vegetable","tanka":210},
{"code":"nasi","name":"梨","category":"fruit","tanka":210},
{"code":"orange","name":"オレンジ","category":"fruit","tanka":200}]
var rs2 = alasql("SELECT * FROM testa ORDER BY category, code");
console.log('rs2', JSON.stringify(rs2));
結果セット:
rs2 [{"code":"apple","name":"リンゴ","category":"fruit","tanka":190},
{"code":"nasi","name":"梨","category":"fruit","tanka":210},
{"code":"orange","name":"オレンジ","category":"fruit","tanka":200},
{"code":"carrot","name":"人参","category":"vegetable","tanka":210}]
var rs3 = alasql("SELECT * FROM testa, testb WHERE testa.code = testb.code ORDER BY testa.category, testa.code");
console.log('rs3', JSON.stringify(rs3));
結果セット:
rs3 [{"code":"apple","name":"リンゴ","category":"fruit","tanka":190,"su":10},
{"code":"carrot","name":"人参","category":"vegetable","tanka":210,"su":5}]
◇UPDATE
alasql("UPDATE testa SET name = 'りんご' where code = 'apple'");
var rs4 = alasql("SELECT * FROM testa, testb WHERE testa.code = testb.code ORDER BY testa.category, testa.code");
// 結果セットをArrayとして扱うならこんな感じ
for (var i = 0; i < rs4.length; i++) {
var kin = rs4[i].tanka * rs4[i].su;
console.log('rs4', rs4[i].name + ':' + kin);
}
rs4 りんご:1900
rs4 人参:1050
といった具合に直感的に使えます。
また、
alasql("SELECT * INTO CSV('outputfile',{headers:true,separator:','}) FROM testa, testb WHERE testa.code = testb.code \
ORDER BY testa.category, testa.code");
といった具合に、例えばCSVへのexportや、
alasql.promise("select * from csv('inputfile.txt')")
.then(function(rs6){
for (var j = 0; j < rs6.length; j++) {
console.log('t6', rs6[j].name);
}
}).catch(console.error);
CSVからのimportも可能です。
(他にも、xlsやxlsx、IndexedDB、LocalStorage、SQLiteなどにも対応しているようです。)
軽く触ってみただけでも自分の欲しかった機能は大体見つかったのですが、
まだまだ多くの機能を有しているようです。(トランザクション機能もあるのだとか(!))
是非使いこなしていきたいですが、いやあJavaScriptは深いですねえ…。
JavaScriptにおけるオブジェクト指向
JavaScriptのオブジェクト指向
JavaScriptのオブジェクト指向ではインスタンス化/インスタンスという概念はあるもののJavaやC#でいうクラスというものがありません。あるのは実体化されたオブジェクトだけであり、新しいオブジェクトを生成するときも既存のオブジェクトが元になっています。
定義例
//コンストラクタとプロパティの定義
var Person = function(firstName, lastName){
this.firstName = firstName;
this.lastName = lastName;
}
//メソッドの定義
Person.prototype.getName = fuction(){
return this.lastName + this.firstName;
}
変数Personに代入される関数がコンストラクタ、その中身のthis.〇〇〇がプロパティとなります。prototypeプロパティはオブジェクトにメンバーを追加するためのプロパティでここに格納されたメンバーはそのオブジェクトを元にしたインスタンスから利用することができます。prototypeプロパティに追加されたメンバーはインスタンスから暗黙的に参照され、インスタンスにコピーされないためメモリの使用量を減らすことができます。
インスタンス化とプロパティ・メソッドの呼び出し
//インスタンス化
var a = new Person(‘太郎’, ‘山田’);
console.log(a.getName());//結果:山田太郎
変数名.プロパティ名、変数名.メソッド名で呼び出すことができる。
継承
//継承元
var Parent = function(n){
this.x = n;
this.y = n * 2;
}
Parent.prototype.print = function() {
console.log("x = " + this.x + ",y = " + this.y);
}
//継承先
var Child = function(n){
Parent.call(this, n);//親オブジェクトのコンストラクタ呼び出し
}
Child.prototype = new Parent();//親オブジェクトのインスタンスをセット
var test = new Child(2);
test.print();//結果:x = 2,y = 4
継承するオブジェクトのインスタンスを継承先のprototypeにセットすることで親オブジェクトに定義されたメソッドを呼び出すことができる。
class命令
上記のようにJavaScriptのオブジェクト指向では独特なクラス定義を書く必要がありましたがES2015からclass命令が導入され、以下のような定義が可能となりました。
class Person{
//コンストラクタ
constructor(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
//メソッド
getName(){
return this.lastName + this.firstName;
}
}
また、extendsキーワードを使うことで既存のクラスを継承したサブクラスを定義できます。
//親クラス
class Parent{
constructor(n){
this.x = n;
this.y = n * 2;
}
print(){
console.log("x = " + this.x + ",y = " + this.y);
}
}
//子クラス
class Child extends Parent{
constructor(n){
//親クラスのコンストラクタの呼び出し
super(n);
}
}
public/protected/private のようなアクセス修飾子は利用できないなど注意する点もありますがJavaやC#の経験者であれば理解しやすいものとなっています。
ブロックチェーン
■はじめに
金融とテクノロジーを掛け合わせたフィンテックが最近、注目を集めています。その代表例として
ビットコイン(仮想通貨)が有名ですがこの仮想通貨といわれるサービスが成り立つ上で非常に重
要な技術といわれているのがブロックチェーンです。
■ブロックチェーンは分散型
ブロックチェーンは分散型のネットワークシステムであり、中央集権(第三者機関)を置かずに
信憑性を保つことを可能とする技術です。
ブロックチェーン誕生以前は、中央集権(金融業界であれば第三者機関の銀行)を通して行われていました。
これまでは中央集権(銀行)が絶対的な力をもっていました。
しかしブロックチェーンを使えば第三者機関を通さずに買い手と売り手が直接取引きすることが可能になります。
■ブロックチェーンは騙せない
ビットコインでは仮想通貨をウォレットという財布で保管します。
例えば悪意のあるA氏がウォレットの残高(10000BTC)を偽装しても、A氏のウォレットに
10000BTCが入っているという記録がブロックチェーンに存在しないのでA氏が自分が持って
いる通貨より高い通貨で取引を実施しようとしても拒否されます。
つまり取引の履歴データが世界中に分散されている(お互いに監視されている)ため、
ハッキング(偽造)ができない仕組みになっているます。
ブロックチェーンは力をもった支配者に支配されることなく、世界中の人と自由に取引が可能になります。
■ブロックチェーンのメリット
1.コスト
従来型(中央集権)では中央機関から仲介手数料が取られる。ブロックチェーンは手数料が低くい。
2.信頼性
従来型(中央集権)では中央機関のシステムが停止した場合、利用不可となるがブロックチェーンは
分散型のためシステムは停止することなく利用できる。
3.セキュリティ
参加者全員が監視しているためセキュリティ性(改ざん等の防止)が高い。
■ブロックチェーンのデメリット
1.パフォーマンス
ビットコインではブロックチェーンによる取引の記録(登録)には10分かかる。
2.データ量
全ての取引の履歴を保存するため保管するデータ量が膨大になる。
■ブロックチェーンは止められない
インターネットを止められないように仮想通貨(ビットコイン)のブロックチェーンは誰にも止めることはできません。
なぜならシステムが世界中に分散されているためです。
■ブロックチェーンの応用
ブロックチェーンは通貨外にも応用できます。
第三者機関を経由している業界の仲介役を取り除くことができ直接取引が可能になります。
C言語と2038年問題
C言語の時刻取得の勉強として、以下のようなプログラムを作成する。
#include <time.h>
#include <stdio.h>
int main() {
time_t test;
time(&test);
printf("今年は:%ld\n", (1970 + test/3600/24/365));
test += 20*365*24*3600;
printf("20年後は:%ld\n", (1970 + test/3600/24/365));
test += 1*365*24*3600;
printf("21年後は:%ld\n", (1970 + test/3600/24/365));
return 0;
}
time_t型には秒が入っているので、年に変換して表示している。(誤差はとりあえず無視)
では、この結果はどのようになるだろうか?
今年は:2017
20年後は:2037
21年後は:1903
※32bit GCCでビルド。
この原因は、PCの時刻の表現が、基準日時を1970/01/01 00:00:00(UTC)として、そこからの経過時間をtime_t型の値としているため。
time_t型のビット長は実装依存だが、多くの環境で使用されている符号付き32ビットの場合、2038/01/19 03:14:07(UTC ※日本時間では12:14:07)でオーバーフローする。
現在はtime_t型を符号付き64ビットにするなどコンパイラ側で対応されているので、最近のコンパイラでビルドをしたプログラムなら問題ないはず。
しかし、再ビルドせずに使い続けられているモジュールは多い。
また、旧システムの改修には古いコンパイラを使用することもある。
ソースコードもあらかじめ決められた要件の箇所以外は触ることはなく、だれにも気づかれずに残り続ける可能性がある。
新旧さまざまなシステムのどこに32ビットのtime_tが使われているかわからない。
これからも気にし続ける必要がある。
自分のダイログライブラリーを作ってみた!
いつもWebPageを作るとき、単純に alert("何何何何"); を使った事あるでしょ!
あれはWindowのデフォルトのもので何もコントロールが出来ないので、つまらないでしょうね?
ダイログの形も、色も、サイズも、ヘッダーのキャップションも変えることも出来ないですね。
インターネットで他のLibralyをDownloadして使ってみても、自分のWebPageとぴったり似合うではないし、
そのLibralyの使い方を理解するように勉強しないと!
それまでやるなら、自分のDialog Libraryを作ったほうがいいじゃないか!
と思ってるので、作ってみました。
WASIdia の使い方
1.ルートフォルダーに「WASIdia.js」、「WASIdia.css」と "jquery-x.x.x.js" (バーション未確認、何でもいいと思います)を置きます。
(animation も入れたい場合「animate.css」も必要です。 )
2.htmlページの <header> に以上のファイルをインポートします。
例:
<head>
<title>WASI dialog</title>
<meta charset="utf-8">
<link href="css/WASIdia.css" rel="stylesheet" />
<link href="css/animate.css" rel="stylesheet" />
<script src="js/WASIdia.js"></script>
<script src="js/jquery-2.2.3.js"></script>
</head>
3.<body> の中に <div id="WASIdia"></div> を設置する (ダイログを表示するオブジェクト)
例:
<body>
<div id="WASIdia"></div>
...
...
</body>
4.actionがある時にダイログのfunctionを呼ぶ
★アラート(alert)
WASIalert("アラートのタイトル","アラートの内容");
or
//animationのクラス名を追加
WASIalert("アラートのタイトル","アラートの内容","fadeInDown");
結果

★確認ダイアログ(Confirm)
WASIconfirm("アラートのタイトル","アラートの内容");
OK.click(function(){
//OKボタンを押された後何かをする
})
結果

★入力要求ダイアログ(Prompt)
WASIprompt("アラートのタイトル","アラートの内容");
OK.click(function(){
//OKボタンを押された後、入力されたメッセージを取得する
var myText = TEXT.val();
//貰ったメッセージを何かする
});
結果

WASIdiaの操作は どんな風にやってる?
ダイアログの本体は HTML で作ります。
funtionの中でダイアログのHTMLを組成し、貰ったメッセージを入れて、本ページの <div id="WASIdia"></div> の所に置き換えます。
例:
function WASIalert(title,msg,animate){
target = getTarget();
//本ページにダイアログを表示するオブジェクトが設置されているかどうかをチェック。
if(target){
dialogBody=replaceText(dialogBody_alert,title,msg,animate);
//貰ったメッセージを入り換える。
target.innerHTML=bgBlackdrop+dialogBody;
//ダイアログを表示するオブジェクトに出来上がったコードで置き換える
lockScroll();
//画面をscroll出来ないようにする
}
}
ダイアログの操作が完了する時、<div id="WASIdia"></div> の所を元に戻します。
例:
function WASIclose(){
getTarget().innerHTML="";
$('body').removeClass('noscroll');
}
ダイアログの本体にちゃんとCSS styleを入れますね。
ダイアログのCSSのポイント!
.wsDialog{
position:fixed;
/*重要:他のオブジェクトの位置に無視、このclassで決めた位置になる*/
z-index:9999;
/*重要:他のオブジェクトの一番上のレーヤーになる*/
width:80%;
left: 50%; /*重要:真ん中にする*/
margin-left:-40%; /*重要:真ん中にする*/
background-color:white;
color:black;
box-shadow:1px 1px 3px grey;
border-radius:10px;
padding:2%;
}
これだけで簡単にWASIdiaのダイログを利用できますね。
軽くanimation class も入れた見れば色んな面白い動き方が出来ます。 (animation class名はanimation.cssに参考)
Thanks for animate css from
https://daneden.github.io/animate.css
JQueryのセレクタまとめ
jQueryを使って特定の要素を指定する際にセレクタを使いますが,指定方法を間違ったりすると,余計な要素まで取得してしまったり,要素そのものを間違えてしまったりします.
セレクタで要素を指定するパターンをまとめてみました。
セレクタって?
セレクタはjQueryを記述する際の$()の中のことを指します.
|
|
$("#contents").css(...
|
のように記述し,操作したい要素を指定するために使用します.
要素の指定方法あれこれ
全ての要素を指定する
$("*")
<ol class="class1" id="id1">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<ol class="class1" id="id2">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<script>
$("*").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
基本:要素名で指定する
$("要素名")
指定した要素のものが全て選択される
<ol class="class1" id="id1">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<ol class="class1" id="id2">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<script>
$("ol").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
IDで指定する
$("#ID名")
指定したID名の要素1つが選択される。
IDはユニークな要素なので複数選択されることはない。
<ol class="class1" id="id1">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<ol class="class1" id="id2">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<script>
$("#id1").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
CLASSで指定する
$(".CLASS名")
指定したCLASS名の要素が全て選択される
<ol class="class1" id="id1">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<ol class="class1" id="id2">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<script>
$(".class1").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
OR指定
$("要素1,要素2")
カンマ区切りで複数指定できる
<ol class="class1" id="id1">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<ol class="class1" id="id2">
<li>Sample1</li>
<li>Sample2</li>
<li>Sample3</li>
<li>Sample4</li>
</ol>
<script>
$("#id1,#id2").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
要素内の要素を指定する
$("要素1 要素2")
スペース区切りで要素内の要素を指定できる
<div id="div1" class="classA">
DIV1
<div id="div2" class="classA">
DIV2
<div id="div3" class="classA">
DIV3
</div>
</div>
<div id="div4" class="classA">
DIV4
<div id="div5" class="classA">
DIV5
</div>
</div>
</div>
<script>
$("#div2 .classA").css("color","red");
</script>
DIV1
DIV2
DIV3
DIV4
DIV5
要素内の要素を指定する②
$("要素1 > 要素2")
要素と要素の間に>を入れることで、要素直下の要素という指定ができる
<div id="div1" class="classA">
DIV1
<div id="div2" class="classA">
DIV2
<div id="div3" class="classA">
DIV3
</div>
</div>
<div id="div4" class="classA">
DIV4
<div id="div5" class="classA">
DIV5
</div>
</div>
</div>
<script>
$("#div2 > .classA").css("color","red");
</script>
DIV1
DIV2
DIV3
DIV4
DIV5
要素の次の要素を指定する
$("要素1 + 要素2")
要素と要素の間に+を入れることで、要素の次の要素という指定ができる
<div id="div1" class="classA">
DIV1
<div id="div2" class="classA">
DIV2
<div id="div3" class="classA">
DIV3
</div>
</div>
<div id="div4" class="classA">
DIV4
<div id="div5" class="classA">
DIV5
</div>
</div>
</div>
<script>
$("#div2 + .classA").css("color","red");
</script>
DIV1
DIV2
DIV3
DIV4
DIV5
要素より後に出現する要素で指定する
$("要素1 ~ 要素2")
要素と要素の間に~(チルダ)を入れることで、要素1より後の要素2という指定ができる
<div id="div1" class="classA">
DIV1
<div id="div2" class="classA">
DIV2
<div id="div3" class="classA">
DIV3
</div>
</div>
<div id="div4" class="classA">
DIV4
<div id="div5" class="classA">
DIV5
</div>
</div>
</div>
<script>
$("#div2 ~ .classA").css("color","red");
</script>
DIV1
DIV2
DIV3
DIV4
DIV5
フィルター指定方法あれこれ
要素全体の最初の要素
$("要素:first")
要素全体のうち、最初の要素を指定
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".class1 > .classA:first").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
要素全体の最後の要素
$("要素:last")
要素全体のうち、最後の要素を指定
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".class1 > .classA:last").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
親要素を起点とした最初の要素
$("要素1 > 要素2:first-child")
要素1を起点とした要素2の最初の要素
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".class1 > .classA:first-child").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
親要素を起点とした最後の要素
$("要素1 > 要素2:last-child")
要素1を起点とした要素2の最後の要素
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".class1 > .classA:last-child").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
偶数番の要素
$("要素:even")
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".classA:even").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
奇数番の要素
$("要素:odd")
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".classA:odd").css("color","red");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
指定番目の要素
$("要素:eq(指定番)
$("要素:lt(指定番)
$("要素:gt(指定番)")
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<ol class="class1" id="id2">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".classA:eq(3)").css("color","red");
$(".classA:lt(2)").css("color","orange");
$(".classA:gt(5)").css("color","blue");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
- Sample1
- Sample2
- Sample3
- Sample4
要素1の子要素のうち指定番目の要素が要素2であるもの
$("要素1 要素2:nth-child(指定番)")
要素1の子要素のうち指定個おきの要素が要素2であるもの
$("要素1 要素2:nth-child(an+b)")
<div>
<p>1つ目のpタグ</p>
<p>2つ目のpタグ</p>
<p>3つ目のpタグ</p>
<h6>間にh6タグ</h6>
<p>4つ目のpタグ</p>
<p>5つ目のpタグ</p>
<p>6つ目のpタグ</p>
</div>
<script>
$("div p:nth-child(5)").css("color","blue");
$("div p:nth-child(3n+1)").css("color","red");
</script>
1つ目のpタグ
2つ目のpタグ
3つ目のpタグ
間にh6タグ
4つ目のpタグ
5つ目のpタグ
6つ目のpタグ
要素1の子要素のうち要素2であるものの指定番目
$("要素1 要素2:nth-of-type(指定番)")
要素1の子要素のうち要素2であるものを指定個おき
$("要素1 要素2:nth-of-type(an+b)")
<div>
<p>1つ目のpタグ</p>
<p>2つ目のpタグ</p>
<p>3つ目のpタグ</p>
<h6>間にh6タグ</h6>
<p>4つ目のpタグ</p>
<p>5つ目のpタグ</p>
<p>6つ目のpタグ</p>
</div>
<script>
$("div p:nth-of-type(5)").css("color","blue");
$("div p:nth-of-type(3n+1)").css("color","red");
</script>
1つ目のpタグ
2つ目のpタグ
3つ目のpタグ
間にh6タグ
4つ目のpタグ
5つ目のpタグ
6つ目のpタグ
要素1の子要素のうち要素2のみであるもの
$("要素1 要素2:only-child")
<div>
<p>1つ目のpタグ</p>
<p>2つ目のpタグ</p>
<p>3つ目のpタグ</p>
<h6>間にh6タグ</h6>
<p>4つ目のpタグ</p>
<p>5つ目のpタグ</p>
<p>6つ目のpタグ</p>
</div>
<div>
<p>1つ目のpタグ</p>
</div>
<script>
$("div p:only-child").css("color","red");
</script>
1つ目のpタグ
2つ目のpタグ
3つ目のpタグ
間にh6タグ
4つ目のpタグ
5つ目のpタグ
6つ目のpタグ
1つ目のpタグ
特定の文字列を含む要素
$("要素:contains('文字列')")
大文字と小文字は区別されます。
<ol class="class1" id="id1">
<li class="classA">Sample1</li>
<li class="classA">Sample2</li>
<li class="classA">Sample3</li>
<li class="classA">Sample4</li>
</ol>
<script>
$(".classA:contains('3')").css("color","red");
$(".classA:contains('sample1')").css("color","blue");
$(".classA:contains('Sample2')").css("color","blue");
</script>
- Sample1
- Sample2
- Sample3
- Sample4
下位要素を持つ要素
$("要素:parent")
下位要素を持たない要素
$("要素:empty")
<table border="1">
<tr><td></td></tr>
<tr><td>A</td></tr>
</table>
<script>
$("td:parent").css("background-color","yellow");
$("td:empty").css("background-color","blue");
</script>
| A |
要素を含む要素
$("要素1:has(要素2)")
<div id="div1">
DIV1
<div id="div2" id="classA">
DIV2
<div id="div3" id="classA">
DIV3
</div>
</div>
<div id="div4" id="classA">
DIV4
<div id="div5" id="classA">
DIV5
</div>
</div>
</div>
<script>
$(".classA:has(#div3)").css("color","red");
</script>
DIV1
DIV2
DIV3
DIV4
DIV5
特定の属性を持つ要素
$("要素[属性]")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input[name]").css("color","red");
</script>
特定の属性を持たない要素
$("要素:not([属性])")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input:not([name])").css("color","red");
</script>
属性の値が一致する要素
$("要素[属性='値']")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input[name='nameB']").css("color","red");
</script>
属性の値が一致しない要素
$("要素[属性!='値']")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input[name!='nameB']").css("color","red");
</script>
属性の値が前方一致する要素
$("要素[属性^='値']")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input[name^='na']").css("color","red");
</script>
属性の値が後方一致する要素
$("要素[属性$='値']")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input[name$='B']").css("color","red");
</script>
属性の値が部分一致する要素
$("要素[属性*='値']")
<input type="text" name="nameA" value="A">
<input type="text" name="nameB" value="B">
<input type="text" name="nameC" value="C">
<input type="text" value="D">
<script>
$("input[name*='m']").css("color","red");
</script>
フォームの指定方法あれこれ
見出しの要素全て
$(":header")
全てのフォーム要素
$(":input")
| 指定方法 | 対象 |
| :text |
テキストボックス |
| :password |
パスワード入力ボックス |
| :select |
セレクトボックス |
| :radio |
ラジヲボタン |
| :checkbox |
チェックボックス |
| :file |
ファイル選択ボックス |
| :submit |
送信ボタン |
| :image |
画像ボタン |
| :reset |
リセットボタン |
| :button | 全てのボタン |
| :hidden | 隠し要素 |
フォーム要素の状態を指定する
$("要素:has(状態)")
| 指定方法 | 対象 |
| :enabled | 有効である |
| :dsabled |
無効である |
| :checked |
チェック状態である |
| :selsected |
選択状態である |
| :hidden |
非表示状態である |
| :visible | 表示状態である |
| :animated |
アニメーション状態である |
イベントリスナでの指定方法あれこれ
要素そのもの
$(this)
子要素を指定
$(this).children("要素");
親要素を指定
$(this).parent("要素");
カスタムイベントリスナを作ってしまえ
指定の値より大きい値の時にマッチするカスタムイベントリスナ
$("要素:gtval(指定値)")
このようなイベントリスナは存在しませんが、JQueryでは、以下のコードを加えることで、自由に作ることができます。
$.extend($.expr[':'], {
リスナ: function (e,index,meta)
{
return [true/false]
}
});
<input type="text" name="nameA" value="0">
<input type="text" name="nameB" value="1">
<input type="text" name="nameC" value="2">
<input type="text" value="D">
<script>
$.extend($.expr[':'], {
gtval: function (e,index,meta)
{
var num = meta[3].match(/\d/g).join("");
if(isNaN($(e).val())) return false;
if($(e).val() > num) return true;
return false;
}
});
$("input:gtval(1)").css("color","red");
</script>
SQLチューニング
SQLを使ったことがある人ならわかると思いますが、SQLは書き方、使い方によって
実行スピードがかなり変わる場合があります。
実行スピードが遅いなどでSQLの見直しなどしたことがあると思います。
SQLのチューニングとして気を付ける点など上げていきます。
具体的なチューニング手段
- インデックスの作成
SQLのチューニングとしてまず思い付くのがインデックスの作成だと思います。
作成したSQL文の条件式で使用している項目へインデックスが作成されているか確認してみてください。
インデックスを作成すれば、基本的にはパフォーマンスが向上しますが、作成してもパフォーマンスの
向上が見込めないケースがあります。
・WHERE句の検索条件にほとんど使用されない列
検索条件にほとんど使用されない列に対してインデックスを作成しても、効果はありません。
逆に、作成したことによってパフォーマンスの低下を招く恐れがあります。インデックスを作成すると、
インデックスを作成した列のデータを更新した際に、インデックスそのものも更新されるからです。
したがって、検索条件にほとんど使用されない列で、かつ更新頻度が過剰な列に対してはインデックスを
作成しないことをお勧めします。
・検索条件に該当するデータが大量にある場合
インデックスは、大量のデータから 1~ 数百件のデータを取り出すときに最も効果があります。
検索条件に該当するデータが大量にある場合には、インデックスの効果が得られません。
上記のような例もありますので、インデックスの作成はよく考えてから行ってください。
- IN句でのサブクエリ
NOT INやIN句を使用したサブクエリは可能な限り、EXISTS、NOT EXISTSを使用したほうがいい。
IN句を使用した例
SELECT name FROM Personnel WHERE birthday IN (SELECT birthday FROM Celebrities);
EXISTS句を使用した例
SELECT P.name FROM Personnel AS P WHERE EXISTS (SELECT * FROM Clelebrities AS C WHERE P.birthday = C.birthday);
- 不要な結合、不要なDISTINCT
あるテーブルにあるかどうか、ないかどうかを実現するためだけにJOINをして
結果をDISTINCTするSQLをみたことがありますが、大変無駄なのでEXISTS、NOT EXISTSを使用すること。
遅い例
SELECT a.name
FROM shain a,
(SELECT DISTINCT shain_id
FROM sikaku
WHERE sikaku_name
IN ('基本情報','java') ) b
WHERE a.shain_id = b.shain_id;
速い例
SELECT a.name
FROM shain a
WHERE EXISTS
(SELECT ‘X’
FROM sikaku b
WHERE sikaku_name
IN ('基本情報','java')
AND a.shain_id = b.shain_id);
- 左辺の関数
条件では列側に関数は使用しない。インデックスが使用されない。
遅い例
SELECT a.name FROM shain a WHERE to_char(a.birthday,’YYYY/MM/DD’) = ‘2000/03/21’;
速い例
SELECT a.name FROM shain a WHERE a.birthday = to_date(‘2000/03/21’ ,’YYYY/MM/DD’);
- その他
・UNIONよりUNION ALL
重複行を排除するためのソートが発生するので、重複を許すのであればUNION ALLを使う。
・IS NULLはなるべく使わない
・NOT IN、!=、<>はなるべく使用しない
NOT EXISTS、ORやINで代用できるならする。工夫しても無理なら使ってもよいと思う。
他にも方法はたくさんあるかもしれませんが、よくある例としてあげてみました。
効果的なものからそうでもないものまであると思いますが、少しでも動作が早くなるよう
工夫を重ねていくことが大事だと思います。
GLSLシェーダーを使って絵を描く
まず、OpenGLの簡単な説明から
OpenGLとは、クロスプラットフォームの3 次元グラフィックスAPIです。ハードウェアの機能を利用してリアルタイムにレンダリングすることができます。
詳細は省きますが、大まかな流れは以下のようになります。

まず、頂点シェーダで3次元座標を2次元座標に変換し、ラスター形式に変換、最後にフラグメントシェーダ(大雑把に言って色を付けたりぼかしたり)をやって完成となります。
このうち、頂点シェーダとフラグメントシェーダは、昔は固定で出来合いのものを使うしかなかったのですが、今はプログラマが定義する必要があります。
この「シェーダ」を記述するための言語の一つが、GLSLです。
OpenGLはC言語などで扱うため、実際のプログラムはCやJavaなどの言語とGLSLを組み合わせて使うことになります。
プログラマブルシェーダについて
プログラムを書いて実行モジュールを作るのは、こんな流れになると思います。

GLSLもコンパイルして実行する方式なので、基本的には同じです。

C言語のプログラムを実行するときと違う点として、
- 出力されるのは実行ファイルではなくGPU依存の中間コードで、出力先はグラフィックボードのメモリなので、基本的に見ることはできない
- プログラム実行時に毎回コンパイルされるので無駄な気もするが、グラフィックボードが変わっても同じコードが実行できるメリットがある。
- VC++やGCCのようなコンパイラではなく、グラフィックボードのドライバに文字列を食わせることになる。
GLSLというプログラミング言語について
GLSL言語はこんな感じの言語です。
※フラグメントシェーダです。頂点シェーダは今回はやりません。
#ifdef GL_ES
precision mediump float;
#endif
#extension GL_OES_standard_derivatives : enable
uniform float time;
vec3 getColor()
{
return vec3(sin(gl_FragCoord.x / 16.0 + time) * 0.5 + 0.5);
}
void main(void)
{
gl_FragColor = vec4(getColor(), 1.0);
}
ぱっと見、C言語っぽいですが、見慣れないものがあります。
- 最初の#extensionは、まあそんなもんだと思ってください。
- 変数宣言の最初にuniformとかがついている。
- gl_FlagCoordやgl_FlagColorという変数をいきなり使っている。
- vec2とかvec3という型が登場している。
まず、C言語の場合はmain関数が実行されますが、GLSL(というかシェーダ言語)の場合、1つ1つの画素に対してmainが実行されるようなものだと思ってください。
つまり。。。
for (gl_FlagCoord.y = 0; gl_FlagCoord.y < 描画領域の高さ; gl_FlagCoord.y++) {
for (gl_FlagCoord.x = 0; gl_FlagCoord.x < 描画領域の幅; gl_FlagCoord.x++) {
main();
}
}
こんな感じで、画素の数だけmainが呼ばれます。
※実際は、パイプラインで並列処理されるのでこの説明は嘘です。
次に、uniformのついた変数宣言ですが、これはシェーダ外部から渡される変数の定義です。
timeには、経過時間(秒)が入ります。
gl_FlagCoordは、フラグメント(つまり画素)の座標が入ります。左下が原点です。
gl_FlagColorは、変数に代入することで、その画素に色が塗られると思ってください。
vec2やvec3は、float型が2個や3個集まった構造体のようなものです。
vec2は2次元座標、vec3は3次元座標、vec4は色(最後の1つはアルファチャンネル)に使われますが、用途が決まっているわけではありません。
動かしてみる
GLSLは、それ単独では動かすことはできず、絵を1枚出すまでのお膳立てが長くなってしまうので、ここでは説明しません。
ただ、動かすだけなら、WebGLというものがあるので、ブラウザ上で試すことができます。
このサイトでは、GLSLのフラグメントシェーダを使って、入力したプログラムが即座に反映されて絵が動きます。
(Chrome推奨)
[Processing]OpenCVを利用した人物認識(その1)
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
API
- Video
動画ファイル、ライブカメラ等の映像を扱う機能を提供
https://processing.org/reference/libraries/video/index.html
- OpenCV for Processing
画像処理・画像解析および機械学習等の機能を提供
https://github.com/atduskgreg/opencv-processing
OS
- macOS sierra 10.12.6
フロー
1.setup
1.1 動画ファイルを指定
1.2 検知対象を設定
1.3 再生設定
2.draw
2.1 OpenCVが検知した対象を配列に格納
2.2 検知対象を四角形で表示
コード
package detection.phase1;
import java.awt.Rectangle;
import gab.opencv.OpenCV;
import processing.core.PApplet;
import processing.video.Movie;
public class WalkerDetection extends PApplet {
Movie movie;
OpenCV openCV;
Rectangle[] detectsFromOCV;
public void settings() {
size(1280, 720);
}
public void setup() {
//動画ファイルを指定
movie = new Movie(this, "umeda_rain.m4v");
openCV = new OpenCV(this, width,height);
//検知対象に歩行者を指定
openCV.loadCascade(OpenCV.CASCADE_PEDESTRIAN);
//ループ再生
movie.loop();
movie.play();
//再生スピード
movie.speed(1);
}
public void draw() {
//動画をメモリに展開
image(movie, 0, 0);
openCV.loadImage(movie);
//OpenCVで検知したオブジェクトを配列に格納
detectsFromOCV = openCV.detect();
//検知対象を四角形で表示
noFill();
stroke(255, 0, 0);
strokeWeight(3);
for (int i = 0; i < detectsFromOCV.length; i++) {
rect(detectsFromOCV[i].x, detectsFromOCV[i].y,
detectsFromOCV[i].width, detectsFromOCV[i].height);
}
}
//映像フレーム毎に自動呼び出しされるイベント
public void movieEvent(Movie m) {
//現在のフレームを読み込み
m.read();
}
//キー押下
public void keyPressed() {
//Spaceキー
if(key == ' '){
//一時停止
movie.pause();
}
//ENTERキー
if(key == ENTER){
//再生
movie.play();
}
}
public static void main(String[] args) {
PApplet.main(WalkerDetection.class.getName());
}
}
実行結果
OpenCVforJavaをインストール
開発環境
API
- OpenCV for Java 3.3.1
画像処理・画像解析および機械学習等の機能を提供
OS
- macOS sierra 10.12.6
参考サイト
macOS環境でhomebrewを利用したインストール方法を紹介するサイトがいくつかありましたが
どれも次のモジュールが作成されなかったので調べたところ参考サイト記載の方法でうまくいったので
メモしておきます。
libopencv_java331.dylib
opencv-331.jar
1.terminalを起動
2.コマンド実行
brew edit opencv
3.以下編集
-DBUILD_opencv_java=OFF
↓
-DBUILD_opencv_java=ON
4.homebrewでインストール
brew install --build-from-source opencv
5.確認
ls /usr/local/Cellar/opencv/3.3.1_1/share/OpenCV/java/
BOXAPI① 準備編
・BOXAPIとは?
法人向けクラウドストレージサービスのBoxを利用するためのA
Boxのサービス概要については公式HP参照
https://www.box.com/ja-jp/home
・事前準備
BOXアカウントを登録する。以下のURLで登録出来る。
アカウント設定から言語設定が変更できるので、
https://account.box.com/
登録が出来たら、
https://developer.box.com/
・アプリケーションの作成
マイアプリの「アプリの新規作成」から作成する。
作成するアプリの種類を聞かれるので「カスタムアプリ」
認証方法は「JWTを利用したOAuth2.0(サーバー認証)
アプリの名前は任意に設定する。
アプリの作製に成功すると、
このトークンは1時間の間利用可能。
Box上のフォルダやファイルにアクセスが出来る。
curlがインストールされている環境なら、
実行すると、以下のように表示される。

改行が無いので非常に見づらいが、
これはルートディレクトリを表示する、
ブラウザ上で見ると、こんな感じ。

curlを使ってゴリゴリやるのもいいのだけども、
せっかくなので今回はSDKを使ってみようと思う。
次の記事でとりあえず環境のセットアップから。
[Processing]OpenCVを利用した人物認識(その2)
開発環境
言語
- Processing 3.1.1
eclipseを使用し、core.jarをインポートした環境でコーディングしているため、ProcessingのIDEでは実行できません。
参考URL
http://hiroyukitsuda.com/archives/1721
- java 1.8.0_91
API
- Video
動画ファイル、ライブカメラ等の映像を扱う機能を提供
https://processing.org/reference/libraries/video/index.html
- OpenCV for Processing
画像処理・画像解析および機械学習等の機能を提供
OS
- macOS sierra 10.12.6
参考サイト
光り輝くパーティクルを作ってみよう
参考著書
Nature of Code -Processingではじめる自然現象のシミュレーション
フロー
1.setup
1.1 動画ファイルを指定
1.2 検知対象を設定
1.3 再生設定
2.draw
2.1 画面の明るさを指定調整し、モノクロで表示
2.2 OpenCVが検知した対象を配列に格納
2.3 検知した対象の頭上に発光する粒子を表示
2.4 全ての検知対象をラインで接続
コード
package detection.phase2;
import java.awt.Rectangle;
import gab.opencv.OpenCV;
import processing.core.PApplet;
import processing.video.Movie;
public class WalkerDetection extends PApplet {
Movie movie;
OpenCV openCV;
Rectangle[] detectsFromOCV;
//---発光処理-------------------------------------------
final int LIGHT_DISTANCE = 500*500; //光が届く距離
final int BORDER = 1000; //発光する計算範囲(短形)
float baseR,baseG,baseB; //光の色
float baseRAdd,baseGAdd,baseBAdd; //色の加算量
final float RED_ADD = 2.7F; //赤色
final float GREEN_ADD = 2.2F; //緑色
final float BLUE_ADD = 3.5F; //青色
float lightPower; //光の大きさ
public void settings() {
size(1280, 720);
}
public void setup() {
//光色の初期化
baseR = 50;
baseRAdd = RED_ADD;
baseB = 100;
baseBAdd = BLUE_ADD;
baseG = 150;
baseGAdd = GREEN_ADD;
//動画ファイルを指定
movie = new Movie(this, "umeda_rain.m4v");
openCV = new OpenCV(this, width,height);
//検知対象に歩行者を指定
openCV.loadCascade(OpenCV.CASCADE_PEDESTRIAN);
//ループ再生
movie.loop();
movie.play();
//再生スピード
movie.speed(0.3F);
}
public void draw() {
//動画をメモリに展開
image(movie, 0, 0);
openCV.loadImage(movie);
//画面の明るさを調整。モノクロ表示とする。
openCV.brightness(-80);
image(openCV.getOutput(), 0, 0 );
//OpenCVで検知したオブジェクトを配列に格納
detectsFromOCV = openCV.detect();
//--光の色を変更
baseR += baseRAdd*5;
baseB += baseBAdd*5;
baseG += baseGAdd*5;
//色が範囲外になった場合は、色の加算値を逆転させる
colorOutCheck();
//各ピクセルの色の計算
int tRed = (int)baseR;
int tGreen = (int)baseG;
int tBlue = (int)baseB;
//綺麗に光を出すために二乗する
tRed *= tRed;
tGreen *= tGreen;
tBlue *= tBlue;
//各ピクセルの色の計算
loadPixels();
//各particleの周囲のピクセルの色について、加算を行う
for(int i=0;i<detectsFromOCV.length;i++){
//particleの影響範囲を計算
int left = max(0,(int) (detectsFromOCV[i].getCenterX()-BORDER));
int right = min(width,(int) (detectsFromOCV[i].getCenterX()+BORDER));
int top = max(0,detectsFromOCV[i].y-BORDER);
int bottom = min(height,detectsFromOCV[i].y+BORDER);
//particle影響範囲の色を加算する
for(int y = top;y<bottom;y++){
for(int x=left;x<right;x++){
int pixelIndex = x + y * width;
//ピクセルから、赤・緑・青の要素を取りだす
int r = pixels[pixelIndex] >> 16 & 0xFF;
int b = pixels[pixelIndex] >> 8 & 0xFF;
int g = pixels[pixelIndex] & 0xFF;
//パーティクルとピクセルとの距離を計算する
float dx = (float) (detectsFromOCV[i].getCenterX() -x);
float dy = (detectsFromOCV[i].y + (detectsFromOCV[i].height/9)) - y;
float distance = (dx * dx) + (dy * dy); //三平方の定理
//ピクセルとパーティクルの距離が一定以内であれば、色の加算を行う
if(distance < LIGHT_DISTANCE){
if(distance < 1){
distance = 1;
}
//検知対象の大きさに比例したパーティクルとする
lightPower = detectsFromOCV[i].width/30;
r += tRed * lightPower/distance;
g += tGreen * lightPower/distance;
b += tBlue * lightPower/distance;
}
//ピクセルの色を変更する
pixels[pixelIndex] = color(r,g,b);
}
}
}
updatePixels();
//検知対象をラインで接続する
stroke(255,150);
strokeWeight(2);
for(int i=0;i<detectsFromOCV.length-1;i++){
for(int j=i+1;j<detectsFromOCV.length;j++){
line((float)detectsFromOCV[i].getCenterX(),
(float)(detectsFromOCV[i].y + detectsFromOCV[i].height/9),
(float)detectsFromOCV[j].getCenterX(),
(float)(detectsFromOCV[j].y + detectsFromOCV[j].height/9)
);
}
}
}
//映像フレーム毎に自動呼び出しされるイベント
public void movieEvent(Movie m) {
//現在のフレームを読み込み
m.read();
}
//色の値が範囲外に変化した場合は符号を変える
private void colorOutCheck() {
if (baseR < 10) {
baseR = 10;
baseRAdd *= -1;
}
else if (baseR > 255) {
baseR = 255;
baseRAdd *= -1;
}
if (baseG < 10) {
baseG = 10;
baseGAdd *= -1;
}
else if (baseG > 255) {
baseG = 255;
baseGAdd *= -1;
}
if (baseB < 10) {
baseB = 10;
baseBAdd *= -1;
}
else if (baseB > 255) {
baseB = 255;
baseBAdd *= -1;
}
}
//キー押下
public void keyPressed() {
//Spaceキー
if(key == ' '){
//一時停止
movie.pause();
}
//ENTERキー
if(key == ENTER){
//再生
movie.play();
}
}
public static void main(String[] args) {
PApplet.main(WalkerDetection.class.getName());
}
}
実行結果
ネットワークの基礎 プロトコルとは ~初心者でも分かりやすく~
パケット解析ツールを構築するにあたって、そもそも通信ってどういう仕組み?とか
OSI7階層モデルってよく聞くけどいまいちピンと来ないなあ~とか
プロトコルは決まりごとって言うけど、意識してないからどういうとき知っておかないと影響でるのか分からない
といった状況だったので、改めて自分なりにまとめなおしてみたくなったのでメモ書きしていく。
まず通信とはざっくり言うと、PCとPC、PCとプリンタ、PCとスマホ、PCと機械とかAとBを繋いで情報や資産のやりとりをすることと認識しておけばいいかなと思います。掘り下げれば掘り下げるほど小難しくなるのでまずは概要から!
次に、AとBを繋いでやりとりをするときのお約束事をプロトコルと言いますね。
お約束事とよく言われますが、そもそもなんでやりとりするのに約束事が必要なの?って思うわけです。
人間に置き換えると、LINEや電話、SNSなんかは何も意識せずできちゃってるわけです。
PCだとそれがどうなるか、少しだけ掘り下げてみましょう。

上の図みたいに人間だったら何も気にせず会話スタートできますよね。
これが機械だったらどうなるのか。

はい、イメージとしてはこんな感じです。
・・・。
なんじゃこりゃですよね。
AちゃんからすればBくんはなんていってるかまったく分かりません。
人間の世界でも、こういうコミュニケーションがとれないことってよくありますよね。
アメリカ人の友達がほしくても、英語話せないからそもそも会話できないな、、みたいな。
人間でも機械でもコミュニケーションをとるためにはそれぞれに伝わる方法で接していかなければなりません。
何かコミュニケーションをとるためには、人間だと言葉が一緒じゃないと難しいってことはみなさん認識あると思います。
では同じ日本語でも、方言みたいにそれぞれに癖があったらどうなるでしょう?

秋田

沖縄
こんな具合に秋田や沖縄だと同じ文章でも全然ちがいますよね。
機械の場合においてもそれは一緒で、メーカーが変わるごとにそれぞれ約束事を取り決めていては
意味わかんない!って悲鳴をあげちゃう可能性があるんです。
そのため、異なるメーカ同士でも通信が出来るようにするため、国際的にルールを標準化する動きが出てきたわけです。
それらを取り決める団体も存在します。
wikiさんに聞けば一発なのでここは割愛します。(標準化団体)
ちなみにこういった団体で標準化されたものを強制的に使用しなければいけないということはなく、
あくまで使用を決めるのはメーカが判断します。
つまり「こういう仕様を規格化したからよかったら活用してねぇ」と世界中に知らせることにより標準化を促進しているにすぎないということです。
外国の人たちが始めに勉強する日本語って大体標準語ですよね。
でも関西弁や博多弁などを勉強してはいけない!とはなってませんからそれと一緒です。(プロトコル一覧)
次にプロトコルの階層化の考え方や、ネットワークの基本OSI参照モデル7階層の考え方や通信するときのデータの流れについて
とても分かりやすいサイトがあったのでリンクを張っておきます。
プロトコルの階層化 https://www.itbook.info/study/p36.html
と、ここで私のおすすめしたかったサイトが見れなくなってしまいました、、、
何でだろう?私のリンク設定がおかしかったのかなんなのか。
以前もこんなことがあったので、脱線しますがちょっと原因探ってみます。
コマンドプロンプトを開いて下記のコマンドを実行します。
user1>nslookup www.ドメイン名
すると要求がタイムアウトしました。の結果表示が、、、、、
つまりは、DNSサーバーに登録していたはずの情報が無い状態になってるみたいですね。
IPアドレスが分かればサイトも見れるようになるけれど、これ以上の調査は難しそうです。。。
このnslookupコマンドは何かというと、DNSサーバに問い合わせてドメイン情報を取得できるコマンドです。
nslookup IPアドレス/ホスト名 [DNSサーバー]でDNSサーバーにIPアドレス/ホスト名の情報を問い合わせます。
DNSサーバーを指定しない場合は、/etc/resolv.conf に記載されているDNSに問い合わせます。
本来はこんな感じでIPとドメイン名の紐付けが分かるはずです。
$ nslookup yahoo.com Server: aaa.bbb.ccc.ddd Address: aaa.bbb.ddd.ddd#53 Non-authoritative answer: Name: yahoo.com Address: 206.190.36.45 Name: yahoo.com Address: 98.138.253.109 Name: yahoo.com Address: 98.139.183.24
DNSサーバーに問い合わせてドメイン情報を取得する流れは以下のサイトの図が分かりやすいです。
http://ドメインまるわかり.jp/special/dns/page_02.html
BOXAPI② SDKを利用する

開発環境はPleades Mars(4.5.1)を利用、Javaのバージョンは1.8.0_60。
BOXAPIのSDKは、11/1時点で最新の2.8.2を利用する。

必要最小限のライブラリをインポートするとこんな感じ。
とりあえずはこれで動くけども、もしかしたら他にも必要な物はあるかもしれない。
その他に必要なライブラリはSDKのダウンロード先に記載があるが、以下二点のみ注意が必要。
・Java Cryptography Extension は、Javaのバージョンに合わせた物を使用する。今回はJava1.8.0なので、SDKのダウンロード先のリンクではなく、こちら。
・slf4jを追加ライブラリが参照しているようなので、必要ならlog4jなどから取ってくる
必要ライブラリの用意が出来たら、サンプルコードが用意されているので、そちらを動かしてみる。
https://github.com/box/box-java-sdk/tree/master/src/example/java/com/box/sdk/example
幾つかのコードが存在するが、とりあえずは一番シンプルなMain.javaを動かしてみる。
動かす前に認証用のトークンが必要なので、BOXの開発者用ページから前回作成したアプリケーションを選択する。
アプリケーションの設定画面に移動したら、画面左のメニューからConfigurationを選択する。

画面中央の「Developerトークンを生成」ボタンを押下すると、Developerトークンが生成される。
今回は動作確認なので、お試しにこれを使って認証を行う。
生成に成功すると、こんな感じに表示が変わる。

この「qTEdNsjWfUJ2ycY7Q4kRxxDBIWOPn6fA」と表示されているのがDeveloperトークン。
COPYボタンを押すとクリップボードに保管されるので、このDeveloperトークンをサンプルコードの以下の行にコピーする。

これをビルドして実行すれば、ルートフォルダとそこから1階層したのフォルダに存在するファイルとフォルダのリストが表示される。
実際に実行してみると、こんな感じ。

とりあえずはこれでSDKから操作は出来るようになった。
今回は単純なリスト表示だけだか、もっといろいろなことをやりたい場合は、その他のサンプルコードやSDK付属のドキュメント、もしくはリファレンスを見ながらやれば、だいたいのことは出来るようにはなると思う。
それよりも、Developerトークンだと1時間しか有効期限が無いので、せっかく作ったアプリもしばらくすると認証エラーで使えなくなってしまう。
この場合でも再度Developerトークンを発行すれば再び使用できるようになるのだが、1時間おきに作業が必要になるのは現実的ではない。
なので、次回はJWT(JSON Web Token)を利用したOAuth2.0認証を実装するのに挑戦してみる。
tcpdump(iptraceなど)とfirewall(ipsec、iptablesなど)はどっちが先?
ソケット通信がハーフオープンになってしまうって事象が発生しました。
こういう時には、tcpdumpで調べますよねってことで、通信トレースを取得して解析をしてみると、どうやら、ハンドシェイクの時に、syn、syn ackと通信があってackが返せていないって感じでした。
syn、syn ackまで通信ができているってことは、ネットワークルーティングや機器間のFirewallとかには問題ないだろうって推測で、
ソースとなる機器側がackを返せない理由を調べていました。
結果として、機器自体のfirewall(AIXでしたので、IPsecのフィルター)で該当のインバウンド通信が閉じていたからなんですけど、
まてよと、インバウンドを閉じているなら、tcpdumpにsyn ackが記録されたのは何故だろうと思ったので、その理由をメモしておきます。
まず、結果から
NIC → tcpdump(iptrace) → firewall(ipsec) という処理順になっていると思われます。
その理由:
NIC (L1) → tcpdump(L2での処理) → firewall(L3-L4での処理) だからですね。
ネットワークの通信は、OSI参照モデルの順で処理されているからってことで、納得。
備考:
Firewallのパケットフィルタとは、OSI参照モデルにおけるネットワーク層(レイヤ3)やトランスポート層(レイヤ4)に相当するIPからTCP、UDP層の条件(ポリシー)で、通信の許可/不許可を判断するもの。
MinecraftのMODを作りたい~環境構築編~
MinecraftのMODを作ってみたい!!
そう思ったので、なにかしら作ってみようと頑張ってみることにしました。
Minecraftとは、知っている人も多い時代になりPC版以外にも様々な据え置き型ゲーム機やスマートフォン版がリリースされています。
その中でも、PC版ではMODというユーザーが作成した新たな要素を追加することができ、据え置き型ゲーム機などではできないことが出来るようになります。
そんなMODを作成するってのはいまいちよくわかってないんですが、とりあえず調べながらやっていってみようと思うます。
と、言うわけでまずは環境構築だ!!どんなMODを作るかはその場のノリだ!!
環境構築開始!!
とりあえず、調べてみたところMODを作成する方法は意外といろいろある様子。
その中で、ソースをいじくりまわしたりする方法でがんばってみる。
環境としては以下のものを準備!
・JDK(Java SE Development Kit)
・MinecraftForge MDK
・Eclipse
そしてバージョン的には以下のものを使うぞ!!
全てを模倣しても面白くないので最新バージョンでやってみる!!
・jdk-8u152-windows-x64.exe
・forge-1.12.2-14.23.1.2555-mdk.zip
・pleiades-4.7.1-java-win-64bit-jre_20171019.zip
ちなみにEclipseは日本語化されたAll In Oneのやつです。
そして私のPCはWindows7 64bitです。他になにか書いておくべきこと...わからない!
環境構築の手順は以下のサイトを参考にしてます。そっちを見てね?
参考の内容と違うところがあったら書きます!!
①JDKのインストール
→開発環境の構築1-1 JDK(Java SE Development Kit)
②MinecraftForgeのビルドアップ
※私はDドライブで作業をするため、コマンドプロンプトを使うときはまず最初に「cd /d d:」でドライブ移動する。
③Eclipse
そんなこんなで参考にしたURL通りに進めていったらうまくMinecraftが起動しましたー!!

でもやっぱりスキンは反映されなかったけれど、動いたので良しとしよう!!
次回は、なにかしら新要素を作っていきたいと思います。
[openFrameworks]ofxBox2d addonを利用するとエラー
開発環境
言語
- openFrameworks 0.98
addon
- ofxBox2d
質量・速度・摩擦といった、古典力学的な法則をシミュレーションするゲーム用の2D物理演算エンジン
IDE
- xcode Version 9.1 (9B55)
OS
- macOS sierra 10.12.6
参考著書
Beyond Interaction[改訂第2版] -クリエイティブ・コーディングのためのopenFrameworks実践ガイド
エラー内容
Use of undeclared identifier 'ofDefaultVertexType'
回避方法
https://github.com/vanderlin/ofxBox2d
のaddonを利用するとエラーとなります。
ダウンロードしたaddonのREADME.md記載のとおりにopenFrameworksのバージョンにあわせたaddonを利用する。
First, pick the branch that matches your version of openFrameworks:
* OF [stable](https://github.com/openframeworks/openFrameworks/tree/stable) (0.9.8): use [ofxBox2d/stable](https://github.com/vanderlin/ofxBox2d/tree/stable)
* OF [master](https://github.com/openframeworks/openFrameworks) (0.10.0): use [ofxBox2d/master](https://github.com/vanderlin/ofxBox2d/)
MinecraftのMODを作りたい~事前準備編~
ちょっとした事前準備
本格的に新要素を追加していく前に基本となるメインクラスを書いておくぞ!!
以下のページを参考に作った
package katanaMod.main;
public class Reference {
public static final String MOD_ID = "katanamod";
public static final String MOD_NAME = "KatanaMod";
public static final String MOD_VERSION = "1.0.0";
public static final String CLIENT_PROXY_CLASS = "katanaMod.proxy.ClientProxy";
public static final String COMMON_PROXY_CLASS = "katanaMod.proxy.CommonProxy";
}
package katanaMod.proxy;
import net.minecraftforge.fml.common.event.FMLInitializationEvent;
import net.minecraftforge.fml.common.event.FMLPostInitializationEvent;
import net.minecraftforge.fml.common.event.FMLPreInitializationEvent;
public class ClientProxy extends CommonProxy {
// init アイテム・ブロックの登録、コンフィグ読み込みなど事前の初期化作業を行う
@Override
public void preInit(FMLPreInitializationEvent event) {
super.preInit(event);
}
// RegisterRender レシピ追加、レンダー登録など
@Override
public void init(FMLInitializationEvent event) {
super.init(event);
}
// 他Modとの連携
@Override
public void postInit(FMLPostInitializationEvent event) {
super.postInit(event);
}
}
package katanaMod.proxy;
import net.minecraftforge.fml.common.event.FMLInitializationEvent;
import net.minecraftforge.fml.common.event.FMLPostInitializationEvent;
import net.minecraftforge.fml.common.event.FMLPreInitializationEvent;
public class CommonProxy {
// init アイテム・ブロックの登録、コンフィグ読み込みなど事前の初期化作業を行う
public void preInit(FMLPreInitializationEvent event) {
}
// RegisterRender レシピ追加、レンダー登録など
public void init(FMLInitializationEvent event) {
}
// 他Modとの連携
public void postInit(FMLPostInitializationEvent event) {
}
}
package katanaMod.main;
import org.apache.logging.log4j.Logger;
import katanaMod.proxy.CommonProxy;
import net.minecraftforge.fml.common.Mod;
import net.minecraftforge.fml.common.Mod.EventHandler;
import net.minecraftforge.fml.common.Mod.Instance;
import net.minecraftforge.fml.common.SidedProxy;
import net.minecraftforge.fml.common.event.FMLInitializationEvent;
import net.minecraftforge.fml.common.event.FMLPostInitializationEvent;
import net.minecraftforge.fml.common.event.FMLPreInitializationEvent;
@Mod(modid = Reference.MOD_ID, name = Reference.MOD_NAME, version = Reference.MOD_VERSION)
public class Katana {
@SidedProxy(clientSide = Reference.CLIENT_PROXY_CLASS, serverSide = Reference.COMMON_PROXY_CLASS)
public static CommonProxy proxy;
@Instance
public static Katana instance;
public static Logger logger;
// init アイテム・ブロックの登録、コンフィグ読み込みなど事前の初期化作業を行う
@EventHandler
public void preInit(FMLPreInitializationEvent event) {
logger = event.getModLog();
proxy.preInit(event);
}
// RegisterRender レシピ追加、レンダー登録など
@EventHandler
public void init(FMLInitializationEvent event) {
proxy.init(event);
}
// 他Modとの連携
@EventHandler
public void postInit(FMLPostInitializationEvent event) {
proxy.postInit(event);
}
}
と、言うわけで事前準備が完了しました!!
それぞれのクラスに書かれているのでもう分かっているかもしれませんが、
刀を作って武器とできるようなModを作成しようと思います。
事前準備だけでそれなりの長さになってしまったので、新ブロック作成編は次の記事に。
まずは刀の材料となる玉鋼の元となる鉱石ブロックを追加しようと思います!!
刀に関しての知識は全然ないんだけどね...
MinecraftのMod ListにKatanaModが表示される!
GPUコンピューティングを始めよう
1. GPUとは?
GPUとは Graphics Processing Unit の略称です。
高速のVRAM(ビデオメモリ;グラフィックボード上のGPU専用メモリ)を持っています。
大量のデータを複数のプロセッサで同時かつ並列処理することができます。


2. GPUコンピューティングとは?
計算機での数値計算においてGPUを利用することをGPUコンピューティングといいます。
NVIDIA(エヌビディア)社が汎用計算に対応したGPUを開発し、CUDA(クーダ)を配信しGPUコンピューティングが普及しました。
3. CUDAとは?
CUDA(クーダ)とはCompute Unified Device Archtectureの略称です。
半導体メーカーNVIDIA(エヌビディア)社が提供するGPUコンピューティング向けの統合開発環境で、
プログラム言語はC言語ベースに拡張を加えたものを使用します。

4. CUDAに必要なもの(使用環境)
【GPU】
CUDAに対応したNVIDIA製GPU
【OS】
Windows 10(64bit版)
【コンパイラ】
OSに対応したCコンパイラ(WindowsならVisual Studio)
https://www.microsoft.com/ja-jp/dev/default.aspx
Visual Studio community 2017を使用
CUDA TOOLKITのダウンロード
https://developer.nvidia.com/cuda-downloads
5. CUDAのインストール
①Visual Studio community 2017 をインストールします。
②CUDA TOOLKIT をインストールします。
6. Hello, World !
#include <stdio.h>
int main(int argc, char **argv) {
printf("Hello World!\n");
return 0;
}
コンパイルし実行すると、
**********************************************************************
** Visual Studio 2017 Developer Command Prompt v15.4.2
** Copyright (c) 2017 Microsoft Corporation
**********************************************************************
[vcvarsall.bat] Environment initialized for: 'x64'
C:\cuda>nvcc -o hello_world hello_world.cu
hello_world.cu
ライブラリ hello_world.lib とオブジェクト hello_world.exp を作成中
C:\cuda>hello_world
Hello World!
拡張子が「cu」であり、「nvcc」というCUDA用のコマンドを使用してコンパイルできることを確認します。
nvccコンパイラというのは、「ソースの中のCPUで動く部分とGPUで動く部分を分け、
CPU用コードをCコンパイラに渡し、GPU用コードをコンパイルする」というものです。
そのため、ソースがC言語のみで書かれていてもコンパイル可能、
その場合実際にコンパイルしているのはCコンパイラです。
7. Hello, World FROM GPU !
#include <stdio.h>
__global__ void helloFromGPU(void) {
printf("Hello World from GPU!\n");
}
int main(int argc, char **argv) {
helloFromGPU<<<1,10>>>();
return 0;
}
コンパイルし実行すると、
C:\cuda>nvcc -o hello_gpuN hello_gpuN.cu
hello_gpuN.cu
ライブラリ hello_gpuN.lib とオブジェクト hello_gpuN.exp を作成中
C:\cuda>hello_gpuN
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
先ほどのHello Worldと少し違う点がありますね。
・__global __から始まる helloFromGPU(void) という名前の空の関数
・<<<1,10>>>で修飾された関数の呼び出し
という、C言語では見慣れないコードが出てきました。
__global__(←アンダーバー2つ)は、
簡単に言えばコンパイラに「以下の関数をGPU側で実行します」と指定するコマンドです。
helloFromGPU()関数はGPU用コードを処理するコンパイラに渡され、
main()関数はCコンパイラに渡されます。
CUDA言語はC言語と似ており、同じようにプログラムを書くことができることが特徴です。
8. どれくらいスピードアップするの?
配列の加算処理を例にCPUとGPUの処理時間を比較してみる。
#include <stdio.h>
#include <helper_functions.h>
#include <helper_cuda.h>
#include <helper_timer.h>
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
printf("Error: %s:%d, ", __FILE__, __LINE__); \
printf("code:%d, reason: %s\n", error, \
cudaGetErrorString(error)); \
exit(1); \
} \
}
/*
この例では、GPUとホスト上の単純なベクトルの合計を示します。
sumMatrixOnGPU2Dは、GPU上のCUDAスレッド間でベクトル合計の作業を分割します。
2Dスレッドブロックと2Dグリッドが使用されます。
sumMatrixOnHostは、ホスト上のベクトル要素を順番に反復処理します。
*/
void initialData(float *ip, const int size){
int i;
for(i = 0; i < size; i++){
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumMatrixOnHost(float *A, float *B, float *C, const int nx, const int ny){
float *ia = A;
float *ib = B;
float *ic = C;
for (int iy = 0; iy < ny; iy++){
for (int ix = 0; ix < nx; ix++){
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
return;
}
void checkResult(float *hostRef, float *gpuRef, const int N){
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++){
if (abs(hostRef[i] - gpuRef[i]) > epsilon){
match = 0;
printf("host %f gpu %f\n", hostRef[i], gpuRef[i]);
break;
}
}
if (match)
printf("配列が一致します。\n\n");
else
printf("配列が一致しません。\n\n");
}
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC, int nx, int ny){
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny){
MatC[idx] = MatA[idx] + MatB[idx];
}
}
int main(int argc, char **argv)
{
printf("%s 開始...\n", argv[0]);
// デバイスを設定する
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("使用するデバイス %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
int nx = 12192;
int ny = 12192;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
printf("配列サイズ: nx %d ny %d\n", nx, ny);
// mallocホストメモリ
float *h_A;
float *h_B;
float *hostRef;
float *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
//********************************************************************
// 時間計測(初期化)
//********************************************************************
StopWatchInterface *timer=NULL;
sdkCreateTimer(&timer);
sdkResetTimer(&timer);
sdkStartTimer(&timer);
initialData(h_A, nxy);
initialData(h_B, nxy);
sdkStopTimer(&timer);
float time = sdkGetTimerValue(&timer);
sdkDeleteTimer(&timer);
printf("配列初期化処理 %f 秒\n", time/1000);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
//********************************************************************
// 時間計測(CPU)
//********************************************************************
// 開始時刻の取得
sdkCreateTimer(&timer);
sdkResetTimer(&timer);
sdkStartTimer(&timer);
// 配列加算処理(CPU)
sumMatrixOnHost(h_A, h_B, hostRef, nx, ny);
// 終了時刻の取得
sdkStopTimer(&timer);
time = sdkGetTimerValue(&timer);
sdkDeleteTimer(&timer);
printf("配列加算処理(CPU) %f 秒\n", time/1000);
// mallocデバイスのグローバルメモリ
float *d_MatA;
float *d_MatB;
float *d_MatC;
CHECK(cudaMalloc((void **)&d_MatA, nBytes));
CHECK(cudaMalloc((void **)&d_MatB, nBytes));
CHECK(cudaMalloc((void **)&d_MatC, nBytes));
// ホストからデバイスにデータを転送する
CHECK(cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice));
// ホスト側でカーネルを起動する
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
//********************************************************************
// 時間計測(GPU)
//********************************************************************
// 開始時刻の取得
sdkCreateTimer(&timer);
sdkResetTimer(&timer);
sdkStartTimer(&timer);
// 配列加算処理(GPU)
sumMatrixOnGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
CHECK(cudaDeviceSynchronize());
// 終了時刻の取得
sdkStopTimer(&timer);
time = sdkGetTimerValue(&timer);
sdkDeleteTimer(&timer);
printf("配列加算処理(GPU) %f 秒\n", time/1000);
// カーネルエラーをチェックする
CHECK(cudaGetLastError());
// カーネルの結果をホスト側にコピーする
CHECK(cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost));
// デバイスの結果を確認する
checkResult(hostRef, gpuRef, nxy);
// デバイスのグローバルメモリを解放する
CHECK(cudaFree(d_MatA));
CHECK(cudaFree(d_MatB));
CHECK(cudaFree(d_MatC));
// ホストのメモリを解放する
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// デバイスをリセットする
CHECK(cudaDeviceReset());
return (0);
}
コンパイルし実行すると
Hello World from GPU!
C:\cuda>nvcc -o sumMatrixOnCPU sumMatrixOnCPU.cu
sumMatrixOnCPU.cu
ライブラリ sumMatrixOnCPU.lib とオブジェクト sumMatrixOnCPU.exp を作成中
C:\cuda>sumMatrixOnCPU
sumMatrixOnCPU 開始...
使用するデバイス 0: GeForce GT 710
配列サイズ: nx 12192 ny 12192
配列初期化処理 5.338648 秒
配列加算処理(CPU) 0.636599 秒
配列加算処理(GPU) 0.123255 秒
配列が一致します。
まとめ
GPUの方が処理時間が約1/5になりました。
単純な数値計算はすごく早いです。
※CPU:AMD Ryzen 3 1300X プロセッサー(4コア 3.5GHz)
※GPU:GeForce GT 710
MinecraftのMODを作りたい~鉱石ブロック作成編~
鉱石ブロックを作る!
このMODの目標は、武器としての刀を作れるようにしたいことです。
なので、その刀の材料となる玉鋼の大元となるものを鉱石として作成したいと思います。
はたして、存在するのかわかりませんが玉鋼鉱石なるものを新たな要素として作成する!!
今回の使用するクラスなどなど
// 各種アイテムなどを登録する処理を定義するクラス
・RegistyHandler.java
// 作成する鉱石の登録と描画を行う
・KatanaModBlocks.java
// ブロックの定義と設定を行う
・BlockTamahaganeOre.java
// 鉱石としての細かい定義と設定を行う
・TamahaganeOre.java
package katanaMod.init;
import katanaMod.init.blocks.TamahaganeOre;
import net.minecraft.block.Block;
import net.minecraft.client.renderer.block.model.ModelResourceLocation;
import net.minecraft.creativetab.CreativeTabs;
import net.minecraft.item.Item;
import net.minecraft.item.ItemBlock;
import net.minecraftforge.client.model.ModelLoader;
import net.minecraftforge.fml.common.registry.ForgeRegistries;
public class KatanaModBlocks {
public static Block TAMAHAGANE_ORE;
// ブロックのインスタンスを生成
public static void init() {
TAMAHAGANE_ORE = new TamahaganeOre("tamahagane_ore", 2.0F, 4.0F, 2);
}
// ブロックを登録
public static void register() {
registerBlock(TAMAHAGANE_ORE);
}
public static void registerBlock(Block block) {
ForgeRegistries.BLOCKS.register(block);
block.setCreativeTab(CreativeTabs.BUILDING_BLOCKS);
ItemBlock item = new ItemBlock(block);
item.setRegistryName(block.getRegistryName());
ForgeRegistries.ITEMS.register(item);
}
// ブロックのモデルを登録
public static void registerRenders() {
registerRender(TAMAHAGANE_ORE);
}
// ブロックのモデルを読み込む
public static void registerRender(Block block) {
ModelLoader.setCustomModelResourceLocation(Item.getItemFromBlock(block), 0, new
ModelResourceLocation(block.getRegistryName(), "inventory"));
}
}
ここでは詰まったところがありました。
ブロックの読み込みを行うregisterRenderメソッドで、マインクラフトの世界にアイテムを追加するための処理があります。
正:ModelLoader.setCustomModelResourceLocation()
上記の部分を最初は以下のようにしていました。
誤:Minecraft.getMinecraft()
しかし、どうやらこれはv1.11 までだと動作するのですが、v1.12 だと動作しないということが調べてわかりました。
また、もう一つ詰まったところがありました。
正:ForgeRegistries.BLOCKS.register(block);
としてあるところを最初は以下のようにしていました。
誤:GameRegistry.register(block);
しかし、こうすると「メソッドregister(K)は型GameRegistryで不可視です」とエラーが出てしまっていました。
package katanaMod.init.blocks;
import net.minecraft.block.material.Material;
public class TamahaganeOre extends BlockTamahaganeOre {
public TamahaganeOre(String name, float hardness, float resistance, int harvestLevel) {
super(name, hardness, resistance);
setHarvestLevel("pickaxe", harvestLevel);
}
public TamahaganeOre(Material materialIn) {
super(materialIn);
}
}
ここでのTamahaganeOre(String name, float hardness, float resistance, int harvestLevel)は、
KatanaModBlocks.java で呼び出している部分です。
name は鉱石の名前
hardness は採掘するときのブロックの硬さ
resistance は爆発耐性
harvestLevel はどのランク(木・石・鉄・金・ダイヤ)以上の道具で採取できるか
以上のようにブロックの定義を設定しています。
setHarvestLevel("pickaxe", harvestLevel); は、ピッケルの道具でないと採取できないということになる。
package katanaMod.init.blocks;
import net.minecraft.block.Block;
import net.minecraft.block.material.Material;
import net.minecraft.creativetab.CreativeTabs;
public class BlockTamahaganeOre extends Block {
public BlockTamahaganeOre(String name, float hardness, float resistance) {
super(Material.ROCK);
setUnlocalizedName(name);
setRegistryName(name);
setHardness(hardness);
setResistance(resistance);
setCreativeTab(CreativeTabs.BUILDING_BLOCKS);
}
public BlockTamahaganeOre(Material materialIn) {
super(materialIn);
}
}
package katanaMod.handlers;
import katanaMod.init.KatanaModBlocks;
public class RegistyHandler {
public static void Client() {
KatanaModBlocks.registerRenders();
}
public static void Common() {
KatanaModBlocks.init();
KatanaModBlocks.register();
}
}
ブロックのテクスチャを決めるリソースファイル
アイテムとしての、ブロックとしての見た目を決めるためのリソースファイル
// ブロックの形状を定義するファイル
・/forge-2555-mdk/src/main/resources/assets/katanamod/blockstates/tamahagane_ore.json
// 鉱石としての定義を追加
・/forge-2555-mdk/src/main/resources/assets/katanamod/models/block/tamahagane_ore.json
// アイテムとしての定義を追加
・/forge-2555-mdk/src/main/resources/assets/katanamod/models/item/tamahagane_ore.json
// ブロックの見た目を決める画像
・/forge-2555-mdk/src/main/resources/assets/katanamod/textures/blocks/tamahagane_ore.png
// 鉱石用の名前の定義を追記(英語と日本語)
・/forge-2555-mdk/src/main/resources/assets/katanamod/lang/en_us.lang
・/forge-2555-mdk/src/main/resources/assets/katanamod/lang/ja_JP.lang
{
"variants": {
"normal": { "model": "katanamod:tamahagane_ore" }
}
}
{
"parent": "block/cube_all",
"textures": {
"all": "katanamod:blocks/tamahagane_ore"
}
}
{
"parent": "katanamod:block/tamahagane_ore"
}

/forge-2555-mdk/src/main/resources/assets/katanamod/textures/blocks/tamahagane_ore.png
tile.tamahagane_ore.name=Tamahagane Ore
/forge-2555-mdk/src/main/resources/assets/katanamod/lang/ja_JP.lang
tile.tamahagane_ore.name=玉鋼鉱石
さっそくMinecraftを起動!!







う~ん...インベントリに追加はされているけれどテクスチャが反映されていない...
ワールドに設置をすれば作成したpng画像通りの玉鋼鉱石が設置されるので全てを間違えているわけではなさそうです。
あと、日本語表記でしているのに玉鋼鉱石ではなくTamahagane Oreになっているのも気になります。
この記事の公開を成功してからか、それとも公開してしまって成功した結果を次の記事にしてしまうか。
悩みどころです。
以下は参考にしたサイトです。
WordやExcelでマクロやボタンを作成する方法
Wordのマクロとツールボックス表示方法
①[ファイル]タブー[Wordのオプション]
□開発タブをリボンに表示する
に✓を入れOKします。
②開発のタブができます。
WordマクロやVisual Basicが構成できるようになります。
ツールボックスも構成できるようになるので、
Word内にボタンを追加できますね。
Excelのマクロとツールボックス表示方法

①[ファイル]タブー[Excelのオプション]
□開発タブをリボンに表示する
に✓を入れOKします。

②開発のタブができます。
ExcelマクロやVisual Basicが構成できるようになります。
ツールボックスも構成できるようになるので、
Excel内にボタンを追加できますね。
なお、Ctrl+F11のショートカットでVisual Basicが開きます。
Excelで横方向にフィルターする
Excelには便利なオートフィルター機能がついてるが、これって縦方向しかイメージがない。
今回、横方向でフィルターしたいことがあったので、調べてみた。
とりあえず、知らないだけで実はそのような機能があるのかと思い、「エクセル 横 フィルター」でググる。
...
......
なかった。
エクセルには、横方向にフィルターする機能はない。
ではどうするのか。
サンプルを使ってみていく。

サンプルは、先生が担当できる科目を一覧にしたもの。
このように横に長く伸びている場合、どの科目に対して、どの先生が担当できるのか、横スクロールしていかないとわからない。
★このサンプルから、科目5を担当できる先生が誰か、フィルターして探してみる★
案①
行列を入れ替えてフィルターする。
エクセルには行列を入れ替える機能がある。(表をコピー → 形式を選択して貼り付け → 行列を入れ替える)
この機能と縦方向のフィルター機能を使って実現する。
行列を入れ替えるとこんな感じ。
科目5でフィルター。

担当先生が判明した。
だが、この方法は表をコピーして別の表を作成する手間がある。
一回限りならまだしも、何回も探すとなると、面倒くさすぎる。
案②
ExcelVBAを使う。
VBAでマクロを作る。
実現イメージは、
1.科目一覧でフィルターした状態の行番号を保存
2.その行番号の担当先生列を、右に一つずつ見ていき、
○が一つもない場合は、非表示にする
○が一つでもある場合は、表示にする
科目5でフィルターして、

横フィルターボタンをクリック。

担当先生が判明した。
だが、この方法では、速度が遅くなる可能性がある。(今回のサンプルでは早いが)
実現イメージの、以下の部分。
>2.その行番号の担当先生列を、右に一つずつ見ていき、
> ○が一つもない場合は、非表示にする
> ○が一つでもある場合は、表示にする
このときに、一つずつ設定していくと、速度が遅くなることがあった。
非表示の設定を行うときは、一括で設定したほうがよさそうである。
案③
ExcelVBA + SUBTOTAL関数を使う。
SUBTOTAL関数を埋め込み、それを用いてVBAでマクロを作る。
実現イメージは、
1.各担当先生列の○の個数を関数で取得する
2.その個数が
0のセルをすべて取得する
0以外のセルをすべて取得する
3. 取得した0セルを一括で非表示にする
取得した0以外セルを一括で表示にする
図は、案②と一緒なので、違うところだけ。

先頭行にSUBTOTAL関数を使用する。(別に先頭じゃなくてもいい)
案②との違いは、
・一括で設定するので速度が速いはず
・表の行を追加する場合は、VBAの修正が不要
たが、この方法では、関数が漏れたり式が壊れると誤動作する恐れがある。
(最終的にVBAで関数を埋め込めば、式が崩れる心配もなく、手間もなくなり、一石二鳥)
また、終端列に値が設定されていない場合、

一度横フィルターボタンを押してフィルターされた状態から、解除のボタンを押すと、フィルターされた位置までしか解除されない!
これを回避するためには、終端列の隣に、何か値を設定しておく必要がある。

ここら辺は、もうちょっと工夫したらよいのかもしれない。
こちらの記事も参考にしてください。
WindowsPC同士でWindowsの機能のみでメッセージをやりとりする(失敗談)
業務中に相談しながら作業したいって時ありますよね。
しかし、静かな環境であったり、座席が離れていたりして、会話しにくい時があります。
そういう時、チャットツールやメッセージツールなりを使って、リアルタイムに話ができれば効率が上がります。
インターネットに繋がれば、クラウドのチャットサービスも利用できますが、ローカルLANのみの作業環境もあるのではないでしょうか。また、昨今のセキュリティ事情から、ツールのインストールが制限されていることも多いです。
そこで、作業で使っている端末の標準機能のみを使ったメッセージのやり取りを試したいと思います。
私の使っているWindows7で試してみようと思います。
まずは、昔よくつかっていた方法からやってみます。
自分のマシン: windows7 192.168.13.7/255.255.255.0
相手のマシン: windows7 192.168.13.8/255.255.255.0
ローカルLANにどちらも繋がっています。
とりあえず、CMD命令でDOS窓を起動して、net sendをしてみます。
C:\Users\user1>net send 192.168.13.8 "テスト送信"
このコマンドの構文は次のとおりです:
NET
[ ACCOUNTS | COMPUTER | CONFIG | CONTINUE | FILE | GROUP | HELP |
HELPMSG | LOCALGROUP | PAUSE | SESSION | SHARE | START |
STATISTICS | STOP | TIME | USE | USER | VIEW ]
C:\Users\user1>
あれ?windows7ではSENDが使えなくなっていますね。
じゃあ、他の手段を試してみましょう。
調べてみると、windows7やvista以降は、msg.exeに置き換わったようです。
ではmsgコマンドを使ってみます。
C:\Users\user1>msg
ユーザーにメッセージを送信します。
MSG {ユーザー名 | セッション名 | セッション ID | @ファイル名 | *}
[/SERVER:サーバー名] [/TIME:秒] [/V] [/W] [メッセージ]
ユーザー名 送信先のユーザー名を指定します。
セッション名 セッション名を指定します。
セッションID セッション ID を指定します。
@ファイル名 メッセージの送信先一覧のファイル (ユーザー名、
セッション名、セッション ID) を指定します。
* 指定されたサーバーのすべてのセッションにメッセージを
送信します。
/SERVER:サーバー名 送信先のサーバーを指定します (既定値は現在のサーバー)。
/TIME:秒 受信者の確認応答までの待ち時間を指定します。
/V 実行中に詳細情報を表示します。
/W ユーザーからの応答を待ちます。通常 /V オプションと共に
指定します。
メッセージ 送信するメッセージを指定します。指定しない場合は、入力
プロンプトが表示されるか、または stdin から読み取ります。
C:\Users\user1>C:\Users\user1>msg Console /server:192.168.13.8 "テスト送信"
セッション名の取得エラー 5
C:\Users\user1>
コマンドは有効そうですが、「セッション名の取得エラー 5」っていうエラーになりました。
リモートメッセージだからかな。。。。自分の端末に送ってみる。
C:\Users\user1>msg Console /server:192.168.13.7 "テスト送信"
C:\Users\user1>

自分の端末へは送信できたようです。
相手の端末に何か設定が必要そう。。
どうやら、msgコマンドの規定ではリモートの Windows 7 や Windows Vistaに対してメッセージを送付することができないようです。でも自分のPCへは送信できたので、レジストリで制限があるのだろうと予測して調べてみました。
やはり、変更をすれば動きそうなので、やってみます。
原因は、ターミナルサービスセッションに対するリモートからのRPC接続が無効に設定されているからのようです。
キー HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server
値の名前 AllowRemoteRPC
タイプ REG_DWORD
値 0→1
C:\Windows\system32>reg query "HKLM\SYSTEM\CurrentControlSet\Control\Terminal Se
rver" /v AllowRemoteRPC /s
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server
AllowRemoteRPC REG_DWORD 0x0
検索の完了: 該当 1 件
C:\Windows\system32>reg add "HKLM\SYSTEM\CurrentControlSet\Control\Terminal Serv
er" /v AllowRemoteRPC /d 1 /t REG_DWORD
値 AllowRemoteRPC は存在します。上書きしますか? (Yes/No) y
この操作を正しく終了しました。
C:\Windows\system32>reg query "HKLM\SYSTEM\CurrentControlSet\Control\Terminal Se
rver" /v AllowRemoteRPC /s
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server
AllowRemoteRPC REG_DWORD 0x1
検索の完了: 該当 1 件
C:\Windows\system32>
※レジストリをコマンドで変更する時は、管理者権限でコマンドプロンプトを起動する必要があります。
では、早速、試してみます。
C:\Users\user1>msg Console /server:192.168.13.8 "テスト送信"
セッション名の取得エラー 5
C:\Users\user1>
あれ。。。。
調べてみると、制限があるようです。
- 対象はドメインのメンバーコンピューターのみ
- 管理者権限が必要
-
ファイアウォールを開ける必要がある
以下のグループポリシーを追加します。
Windows Vista, 7の場合
コンピューターの構成/ポリシー/Windows の設定/セキュリティの設定/セキュリティが強化された Windows ファイアウォール/セキュリティが強化された Windows ファイアウォール - LDAP://(略)/受信の規則/
新規作成して、リモートサービス管理をあける
Windows XPの場合
コンピューターの構成/ポリシー/管理用テンプレート/ネットワーク/ネットワーク接続/Windows ファイアウォール/ドメイン プロファイル/
Windows ファイアウォール: 着信リモート管理の例外を許可する
ということで、今回は、あきらめました(残念)
HTMLで外部ファイルを読み込む
・HTMLで外部ファイルを読み込みたい
HTMLで、外部のテキストファイルを読み込みたい時…
例えば以前に書いたエントリ(JavaScriptによるDB「AlaSQL」)のように、SQLをJavaScriptで実行する場合など、SQLをテキストファイルで置いておけば取り回しが効きやすいのではないかと考えました。
・FILEAPIを使えば…?
ファイルを読み込むといってパッと思いつくのは、HTML5で追加されたFILEAPIだと思います。
FILEAPIの使い方を調べると、FILEタグからファイル選択ダイアログを立ち上げ、選択したファイルを読み込む、という手順が紹介されている場合が標準的かと思います。
ただ、このファイル選択を行う方法だと、実行時に操作者が読み込むファイルを適宜指定してやる必要があるため、要件によっては適さない場合があるかと思います。
今回の私の場合などがその例で、画面表示などのイベント発生時にDBから自動でデータを読み込みたいと考えていました。
というところで、今回私が目指したのは、「画面表示時に自動で読み込まれる」「ローカルで実行する」という二つの要件を満たすことでした。
・ところが…
最初はonLoadイベントをこねくり回したり、色々と試していた…のですが、
ところがここで一つ壁に当たってしまいました。セキュリティ上の制約です。
自動で読み込ませるにはファイルの場所を指定してやる必要がありますが、ブラウザのセキュリティ制約により任意のローカルパスのファイルの読み込みを行おうとしてもブロックされてしまうようでした。
たしかに何でもかんでも自動で読み込んでしまえるというのは、非常にマズいというのは想像がつきます。
・試行錯誤した結果…
試行錯誤した結果、読み込む対象のファイルを実行するHTMLと同フォルダ、または下層のフォルダ配下に配置することによって、セキュリティ制約を回避することが出来る、ということが分かりました。(IE11、Edge、FireFox57.0で試した限りは可能でしたが、ブラウザに依存するのではないかと思われます。)
自分が実現したいことは出来るので、この方法を採用することにしました。
そして最終的に、
<object id="sqltext" data="sql.txt" type="text/plain" style="display:none"></object>
<script>
var obj = document.getElementById("sqltext");
obj.onload = function() {
var loadtext = obj.contentDocument.documentElement.textContent;
alert(loadtext);
}
</script>
このように実は読み込むだけならobjectでアクセスできてしまうという事が分かってしまいました。
セキュリティの制限に苦しめられた一方で、またJavaScriptの別種のおおらかさを感じる一件でした。
BIGIP(F5) Memo No.2 証明書のインポート
BIGIPのGUIを使わずに、証明書を更新する手順の紹介です。
※GUIを使った方が簡単ですが、GUIでアクセスができないような環境向けになります。
BIG-IP(v11以降)での証明書更新方法
リクエストの発行
1.BIG-IPマシンにAdminユーザでログインします
2.以下のコマンドで証明書ファイルとキーファイルを把握します
# cd /config/filestore/files_d/Common_d
# ls certificate_d/* certificate_key_d/* | grep [定義名(sample)] | awk -F ':' '{print $3}'
3.以下のコマンドで証明書リクエストを発行します。
# cd /config/filestore/files_d/Common_d
# openssl x509 -x509toreq -in certificate_d/[証明書ファイル名] -signkey certificate_key_d/[Keyファイル名] -out [出力ファイル]
リクエスト作成コマンドサンプル
[root@mybigip:Active:In Sync] Common_d # openssl x509 -x509toreq -in certificate_d/\:Common\:test.crt_196799_2 -signkey certificate_key_d/:Common:test.key_196796_3 -out /shared/tmp/test.csr
Getting request Private Key
Generating certificate request
[root@mybigip:Active:In Sync] Common_d # ls -ltr /shared/tmp/test.csr
-rw------- 1 root root 3612 Jul 13 14:22 /shared/tmp/test.csr
[root@mybigip:Active:In Sync] Common_d #
証明書の更新手順
1.scpでBIG-IPマシンの/shared/tmpにcrt(証明書)を配置します
2.BIG-IPマシンにAdminユーザでログインします
3.以下のコマンドで現状の更新数を把握します
# cd /config/filestore/files_d/Common_d
# ls certificate_d/* certificate_key_d/* | grep [定義名(sample)] | awk -F ':' '{print $3}'
4.以下のコマンドで更新します。
# tmsh modify sys file ssl-cert [定義名(sample.crt)] source-path file:[証明書(/shared/tmp/sample.crt)]
5.更新した内容をコンフィグファイルに反映します。この操作をやっておかないとリブート後に定義が失われます。
# tmsh save sys config
6.更新数がインクリメントされたことを確認します。
# cd /config/filestore/files_d/Common_d
# ls certificate_d/* certificate_key_d/* | grep [定義名(sample)] | awk -F ':' '{print $3}'
更新コマンドサンプル
[root@mybigip:Active: In Sync] tmp # tmsh modify sys file ssl-cert test.crt source-path file:/shared/tmp/test.cer
[root@mybigip:Active:Changes Pending] tmp # tmsh save sys config
Saving running configuration...
/config/bigip.conf
/config/bigip_base.conf
/config/bigip_user.conf
[root@mybigip:Active:Changes Pending] tmp # tmsh run cm config-sync to-group device-group-1
[root@mybigip:Active:Changes Pending] tmp #
[root@mybigip:Active:Not All Devices Synced] tmp #
[root@mybigip:Active:In Sync] tmp #
※今回は紹介しませんが、tmsh installコマンドを使うと、新規の証明書インポートも更新も同じコマンドで可能です。
インフラ開発現場でのテストで使える技集
作ったプログラムをテストする時に、例外ロジックの検証で苦労することがあります。
アプリケーション開発では、ステップ実行ができるツールなどで、SKIPさせたり、値を改変しながら進めることで実現可能ですが、インフラ系の開発現場では、ツールで回避できることが少なく、テクニックが必要になります。
このブログでは、そのテクニックをいくつか紹介しようと思います。
その1:ドメインのアクセス先をごまかしたい
WEBアプリケーションなどの開発現場でも利用できるかもしれません。
ドメインのアクセス先をごまかして、スタブの画面へアクセスをいざなう方法です。
たとえば、http://1excellence.com/xxxx/ というリクエストを実行すると、ブラウザは、1excellence.comというドメインをDNS参照して、IPアドレスに変換し、目的のサイトのサーバーにリクエストを発行します。
これをテスト用サイトのテストアプリに向けたいという時があります。
DNSの定義を変更すれば解決できるのですが、利用中のサイトの場合、業務影響が出てしまいます。
このような時は、作業端末のhostsファイルを使い、ごまかします。
ドメインの名前解決(FQDNをIPアドレスに変換)する時、通常はhostsファイルを参照し名前解決の定義が無いことを確認してから、DNSに問い合わせする挙動をします。
そのため、hostsファイルに名前解決の定義を追加することで、DNS参照をせずに、別のIPアドレスに変換させることができます。
では、hostsファイルはどこにあるのか。
Windowsの場合:
C:\Windows\System32\drivers\etc\hosts
Linux/Unixの場合:
/etc/hosts
このファイルに定義を追加します。
たとえば、
127.0.0.1 1excellence.com
という行を追加して保存します。
すると、先ほどの http://1excellence.com/xxxx/ は、127.0.0.1 というIPアドレスにリクエストを送信します。
※例の127.0.0.1とはLocalhostの意味で、作業端末自身へリクエストを発行することになりますね。
その2.Linuxコマンドをスタブに置き換えたい
シェルスクリプトのテストや、Linux上のコマンド実行をエラーさせたい時等で使える技です。
たとえば、pwd というコマンドがあります。
このコマンド、カレントディレクトリの絶対パスを表示させるコマンドですが、エラーになることはありません。
これをエラーにしたい場合は困りますよね。
実はエラーにみせかけることが可能です。
Linuxにはalias機能があります。長いコマンドを短くすることも可能ですし、実際そのような使い方がされています。
では、Redhat Linuxのデフォルトがどうなっているか確認してみます。
[root@testserver ~]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
[root@testserver ~]#
このようにデフォルトで、いくつか定義されています。
たとえば、通常、lsというコマンドを皆さん実行してディレクトリ内のファイルをリストしていると思いますが、
lsというコマンドは、実は、ls --color=auto というコマンドなんですね。
このalias機能を使えばごまかせます。
例をみていただければ一目瞭然です。
[root@testserver ~]# pwd
/root
[root@testserver ~]# alias pwd='echo test'
[root@testserver ~]# pwd
test
[root@testserver ~]#
このように、pwdというコマンドをecho testというコマンドに置き換えできました。
これを利用して、エラーになるように変更してみましょう。
[root@testserver ~]# echo "exit 1" > a.sh
[root@testserver ~]# chmod +x a.sh
[root@testserver ~]# alias pwd='/root/a.sh'
[root@testserver ~]# pwd
[root@testserver ~]# echo $?
1
[root@testserver ~]#
$?はリターンコードですね。
一次的にpwdコマンドはリターンコードを1にすることができました。
ログアウトしたり、スイッチユーザーすると効果はなくなります。
この挙動変更を恒久的にするには、HOMEのプロファイルや/etc/enviroment等にaliasコマンドで定義を追加します。
これらはあくまでもテスト環境でご利用ください。
悪用すると色々できちゃいますが、けっして、悪いことには利用しないでくださいませ。
こういったテストテクニックを断続的に掲載していこうと思います。
Cmderでタブやカレントディレクトリの状態を保存する
前置き
Cmderとは
タブ機能
複数のコンソールを立ち上げ、タブで管理することができる。
タブには名前を付けることができて、画面下部のタブバーにその名前が表示される。
名前を付けていないタブの場合、実行中のプログラム名が表示される。
また、タブには左から順番に1から始まる番号が振られている(この番号は後で出てくる)。
ウィンドウ分割機能
ウィンドウを複数の領域(ペイン)に分割することもできる。
本題
何が問題か
Cmderは、デフォルトでは終了時のタブやウィンドウ分割の状態を記憶しない。
つまり、いい感じにタブ作って名前付けてウィンドウ分割して作業していても、
Cmderを一旦終了して次回起動するときにはそれらの情報はすべて失われている。
解決策1. タブを保存するオプションを有効にする
[Settings > Startup] から "Auto save/restore opened tabs" にチェックを入れる。

こうしておくと、Cmderの終了時に開いていたタブの状態が保存され、次回起動したときに自動的にその状態が復元されるようになる。
しかし、これは場合によってはうまく動作しないこともあるらしい。
参考:https://github.com/cmderdev/cmder/issues/455
また、自分の場合「プロジェクトに応じた複数のタブ構成を保存しておいて、それらを使い分ける」という用途を想定していたので、上記オプションは適しておらず別の方法をとることにした。
解決策2. Taskを使う
以下のようなタブ構成を例に説明。

- 3つのタブ+最後のタブは3つのペインに分割
- それぞれタブ名やカレントディレクトリは適当に設定
これをCmder起動時に自動的に構築する。
まず [Settings > Tasks] から、以下のようなコマンドを持ったTaskを作成する。
>cmd /c "C:\Program Files\Git\bin\bash" --login -i -new_console:t:tab1 -new_console:d:"C:\path\to\a" cmd /c "C:\Program Files\Git\bin\bash" --login -i -new_console:t:tab2 -new_console:d:"C:\path\to\b" cmd /c "C:\Program Files\Git\bin\bash" --login -i -new_console:t:tab3-1 -new_console:d:"C:\path\to\c" cmd /c "C:\Program Files\Git\bin\bash" --login -i -new_console:t:tab3-2 -new_console:d:"C:\path\to\d" -new_console:s3T50V cmd /c "C:\Program Files\Git\bin\bash" --login -i -new_console:t:tab3-3 -new_console:d:"C:\path\to\e" -new_console:s4T50V
意味
- 各コマンドは空行で区切られる(つまり上記Taskは5つのコマンドを持つ)。
- 最初のコマンドの先頭 > は、初期状態でこのタブをアクティブにすることを示す。
- -new_consoleオプションについては以下の通り
- 書式
- -new_console:<flag>:<value> (<flag>の種類によっては<value>は不要)
- flag,value
- t:<tabname> タブ名指定
- d:"<dir>" カレントディレクトリ指定
- s<tabnumber>T<percents>(V|H) ウィンドウ分割。<tabnumber>は分割対象のタブの番号を指定。その後ろのTは固定。<percents>は分割によって新しく出現するペインの大きさを%単位で指定(ベースは分割前のペインのサイズ。ウィンドウ全体のサイズではない)。最後のVとHは分割方向。垂直方向、つまり下に新しいペインを作りたければVを指定する。水平方向、つまり右に新しいペインを作りたければHを指定する。
- その他詳しくはここに
- https://conemu.github.io/en/NewConsole.html#syntax
- (CmderではなくConEmuのページだが、CmderはConEmuを拡張(?)して作ったアプリケーションらしく、少なくとも自分が使ってみた範囲ではこのページの内容はCmderでも共通している)
Taskができたら、Cmder本体のコマンドラインオプション /TASK でTaskの名前を指定してやればいい。
その際、Task名の{}は外す。すなわち{bash::sample}というTask名の場合は以下のようなコマンドになる。
cmder /TASK bash::sample
自分は、以下のようなショートカットをデスクトップに配置して簡単に起動できるようにしておいた。


