ripgrepとは
Rust製のコマンドラインツール。その名の通りgrepと似た機能を持つ(改良版grep)。
Windows / Linux / Mac にインストール可能。
公式
https://github.com/BurntSushi/ripgrep
本記事ではripgrepの特徴と、個人的によく使っている機能を紹介する。
(バージョン 0.8.1 時点の情報)
インストール
各種パッケージ管理システムを使う方法と、コンパイル済みのバイナリ(実行ファイル)を直接ダウンロードする方法がある。
パッケージ管理システムを使う
https://github.com/BurntSushi/ripgrep#installation
コンパイル済みのバイナリ
https://github.com/BurntSushi/ripgrep/releases
インストールが完了するとrgコマンドが使えるようになる。
ripgrepの特徴(grepとの違い)
とにかく速い
私の手元にある、約20万ファイル格納されたディレクトリを再帰検索した結果
| find + grep | 660秒 (11分) |
| ripgrep | 2秒 |
ripgrepが圧倒的に速い。こんなに速い理由は大きく2つ。
- ripgrepは、検索する必要がなさそうなファイル(たとえば、隠しファイル、バイナリファイル)をデフォルトで無視するようになっている。上記計測に使ったディレクトリを確認したところ、20万ファイル中14万ファイルは無視されるものだった。つまり、ripgrepは実質20万-14万=6万ファイルだけを検索していたのに対し、従来のgrepでは全20万ファイルを律儀に検索していたことになる。
- ripgrepは、シンプルに検索のアルゴリズムが優れている。隠しファイル等を無視せず検索するオプションを指定し、検索対象となるファイル数を同じ20万に揃えて計測してみたところ、それでもripgrepは22秒で検索が終わった。
もっと厳密なベンチマークは公式を参照のこと。
高水準な機能
- デフォルトでディレクトリ再帰検索。findと組み合わせたり、-R(--recursive)のようなオプションを指定したりする必要がない。「rg <正規表現>」たったこれだけの入力でカレントディレクトリの再帰検索が行える。
- 先述の通り検索する必要がなさそうなファイルをデフォルトで無視。隠しファイル、バイナリファイルの他、検索しているディレクトリの中で.gitignoreを見つけるとそれを読み込んでバージョン管理外のファイルも無視してくれる。同様に.ignore(ripgrepより前に登場したgrepツールであるagやackで使用されていた除外リスト)や.rgignore(ripgrep用の除外リスト)も認識する。この辺の挙動はオプションで変更可能(後述)。
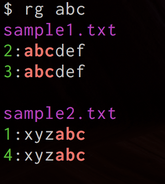
- 出力が見やすい。一方、パイプで繋ぐと自動的に従来のgrepのような行指向のフォーマット(プログラムで処理しやすい)になってくれる空気を読んだ挙動。下図参照
- ファイルタイプ機能。たとえばC言語のソースコードを検索したい場合、ヘッダーファイルも含めるために*.{c,h}のようなワイルドカードを指定することがあると思うが、ripgrepではこのパターンに「c」という短縮名(ファイルタイプ名)が付けられており、-tcというオプションを指定するだけで同じことができる(-tはファイルタイプ指定のオプションで、cがファイルタイプ名)。独自にファイルタイプを定義することもできる(後述)。
- gzip等圧縮されたファイルの検索(zipはサポートされていないので、Windowsではあまり使う機会はないかもしれない)

……とここまで見てきた感じだといいとこ尽くめなripgrepだが、従来のgrepの方が優れている点も存在する。
!grepの方が優れている点!
- どこでも使える(Linux環境ならばたいていデフォルトでインストールされている)。ポータブルなシェルスクリプトを書きたい場合等はやはりgrepを使うべき。
- 安定している(バグや仕様変更の可能性が低い)。ripgrepは新しめのツールであるが故に、予期せぬバグに遭遇したりバージョンアップで使い方が変わったりする可能性がある。
使い方
基本
カレントディレクトリを再帰検索
$ rg <PATTERN>
指定ディレクトリを再帰検索
$ rg <PATTERN> <DIRECTORY>...
指定ファイルを検索
$ rg <PATTERN> <FILE>...
検索の挙動
| デフォルト | オプション | |
| 大文字小文字の区別 | 区別する | -i で区別しない |
| 単語検索 | OFF | -w でON |
| 正規表現検索 | ON | -F でOFF(キーワード検索) |
| .gitignore/.ignore/.rgignore | 解釈する | --no-ignore で解釈しない |
| 隠しファイル | 無視する | --hidden で無視しない |
| バイナリファイル | 無視する | -a で無視しない |
| 行番号の出力 |
ON (パイプで繋いだ場合はOFF) |
-n で常にON |
| 列番号の出力 |
OFF |
--column でON |
| エンコーディング |
UTF-8 |
-E で指定。 -E utf-16 -E sjis など |
設定ファイル
設定ファイルを使ってデフォルトの挙動を変更できる。
設定ファイルにはコマンドラインオプションを1行ずつ羅列する。
#で始まる行はコメント。
空行は無視される。
例)
# 常に行番号を出力する -n # デフォルトエンコーディングをShift_JISに変更 -E sjis
上記のような内容のファイルを適当な場所に保存(~/.ripgreprcが使われることが多い?)
ただファイルを置くだけでは読み込まれないので、環境変数RIPGREP_CONFIG_PATHにパスを設定してやる。
$ export RIPGREP_CONFIG_PATH="$HOME/.ripgreprc"
以降、rgコマンドを実行すると自動的にこの設定ファイルが読み込まれる(常に -n -E sjis を指定しているのと同じ挙動になる)。
ファイルタイプ
ファイルタイプは先にも触れた通り、ワイルドカードの短縮名。
オプション-tに続く形でファイルタイプ名を指定すれば、特定の種類のファイルだけを検索することができる。
$ rg -t<ファイルタイプ名> <PATTERN>
反対に大文字の-Tオプションを指定すると、特定の種類のファイルだけを検索対象から除外することもできる。
$ rg -T<ファイルタイプ名> <PATTERN>
どんなファイルタイプが使えるかは--type-listオプションで確認できる。
$ rg --type-list
すると、たとえばファイルタイプ「c」は以下のように定義されていることがわかる。
c: *.H, *.c, *.h
これは、次の2つのコマンドが等価であることを意味している。
# ファイルタイプ指定 $ rg -tc <PATTERN> # ワイルドカード指定 $ rg -g '*.H' -g '*.c' -g '*.h' <PATTERN>
独自のファイルタイプを定義する
独自のファイルタイプは--type-addオプションで定義できる。
例)
HTML, CSS, JavaScriptをまとめて検索するための「web」ファイルタイプを定義する。
# 1つずつ指定 $ rg --type-add 'web:*.html' --type-add 'web:*.css' --type-add 'web:*.js' -tweb <PATTERN> # まとめて指定でもいい $ rg --type-add 'web:*.{html,css,js}' -tweb <PATTERN>
しかし上記ファイルタイプの定義は永続化されない(その検索1回限りでしか使えない)。毎回このような長ったらしいオプションを指定するのは面倒なので、設定ファイルを活用する。
# ファイルタイプ「web」を定義
--type-add
web:*.{html,css,js}
このように書いておけば-twebオプションの指定だけで済む。
$ rg -tweb <PATTERN>
ファイルの「中身」ではなく「ファイル名(ファイルパス)」で検索
--filesオプションを指定すると、ただ単にファイルパスを列挙するようになる(findコマンドのような感じ)。「あのファイルどこ置いたっけ……」と、名前だけ覚えているファイルを探したい場合に使える。
# ワイルドカードで検索 $ rg -g '<WILDCARD>' --files # 正規表現で検索 $ rg --files | rg <PATTERN>
以上
